I’ve been a Microsoft developer for over two decades. But once I started architecting solutions on AWS and seeing the Windows Tax first hand - in terms of resource requirements and licensing costs - I started trying to avoid Windows like the plague.
Also the true costs of infrastructure became my problem - accounting can see exactly what a solution costs - instead of some amorphous cost in the IT budget.
I really like the better visibility into the true costs. Too many times in the past, a team had a budget for the software they needed to deploy a project, but the Virtualization software, storage array, etc, were all out of the IT budget. that makes the IT budget look bloated, and hard to explain, and ripe for being seen as a 'cost center'.
That’s too bad and unfortunate of some companies who see IT as a black hole. Imagine having an R&D dept which could incur lots of costs and little result individually but as a group produce good licensable IP. Sometimes you have to realize some things are a cost of doing business.
It's not that they don't realize it. The R&D department doesn't have to be accountable for costs. The R&D department isn't incentivized to control costs because it isn't our problem. Proper tagging of resources shines a light on the R&D department and the business knows exactly what our projects' infrastructure cost is.
> Seriously though - Windows images are big - absolutely massive compared to a Linux image - we are talking 30 times larger (on the best of days) so copying these large images to the hypervisor nodes takes time.
No... just no. Disks aren't local to hypervisors. There's no copying going to be taking place. EC2 instances are provisioned using EBS volumes, which aren't going to be local to the instance itself. EBS is likely doing a disk clone operation, and those are relatively cheap in standard filer operations. Even large images you're talking a drop in the ocean in terms of the overall time.
The main issues with Windows in a cloud environment comes from that first boot scenario. You could get past some of that by keeping a pool of warm instances around, but it'd require a lot of work on the Windows side to handle the provisioning use case.
On Linux the instance boots, init processes kick off, and right at the end cloud-init creates and configures accounts with ssh keys etc. and away you go. Typically anywhere between 30-60 seconds boot time depending on the distribution.
Windows isn't that accommodating. Images that are used in cloud environments have to be "generalized". You install it on specific hardware, and then tell it that it's not to give a crap about hardware specifics, but oh you must have these specific drivers etc. in you. It also tells it to clear up after yourself while it is at it.
First boot happens, and Windows goes through a mandatory process whereby it identifies hardware, installs and configures drivers etc. etc. etc.
You can inject a script to carry out the process of things like setting up a user, and generating a password, but that's fairly minor on the scale of things. This first process requires a reboot. There's no escaping it.
That's really the reason why Windows provisioning takes long.
There's unavoidable reboots, and unavoidable Windows driver installation and configuration, where the Linux distribution approach to the kernel makes life easier (every driver you're likely to need is a module and available on boot... unless you've got dracut running in the default host-only mode and it has made you a totally stripped down initramfs.)
Add on that Windows booting takes longer than Linux even under optimal conditions and you end up with a slower launch.
> Windows goes through a mandatory process whereby it identifies hardware, installs and configures drivers etc. etc. etc. You can inject a script to carry out the process of things like setting up a user, and generating a password, but that's fairly minor on the scale of things. This first process requires a reboot. There's no escaping it.
This is the "OOBE" (out of box experience) phase. I'd have thought they'd just skip it and provision you a pre-warmed image .. but I guess because there's a license/activation dependency they can't do that?
I wonder how many MWh could be saved by Microsoft adding a "acquire cloud volume license at boot" mode. Or shoving the licensing/uniquification requirements into the platform TPM.
OOBE occurs after this, the hardware identification phase is what takes the longest time. It has to reboot to load drivers and take 5-10 minutes to identify what hardware in the machine needs to have drivers, etc. Once you get to the blue "Just a moment..." screen, you can inject a script to activate Windows and get to the desktop.
License activation stage is negligible, and doesn't need to be done for several days+. The actual activation of windows doesn't really enter in to the story here.
Disclosure and claim to authority: I work on the Windows team at Microsoft, sometimes on performance and OS installation stuff.
There's definitely some cruft that chews up time on first boot. But it's not everybody's favorite punching-bag, licensing. That stuff doesn't happen in the critical boot path.
It might be installation of device drivers, but that too is unlikely. If you generalize Windows in a VM, you can use the `sysprep.exe /mode:vm` flag, which essentially tells sysprep to retain most of the device tree, since you expect to run the thing on similar hardware. I would assume that AWS is clever enough to have found that flag; certainly we have Azure use it. When the flag is used, there's very little device- and driver-related work to do on first boot after generalization.
The reality is that software is complicated and hard, and anything punchy enough to fit into a comment on a website is going to be a vast simplification of reality. So let the simplification begin :)
One reason first boot is slow is the component that orchestrates startup of usermode services, which on Windows is called SCM. SCM is very old. At the time SCM was created, it was much better than the SysV-style init scripts of other OSes. But since then, other OSes leapfrogged Windows with systemd/launchd, which are a generation ahead of SCM. SCM starts services in serial, while systemd maximizes parallelization. SCM has a "push" model: it basically starts all the services that it can find, while systemd has a "pull" model: it starts just the dependency cone you need to get the system you want. (This is a simplification.)
Another performance issue is that Windows doesn't have a way to notify code that the hostname has changed. Obviously it'd be easy to add one, but then the hard part would be updating the whole OS to do something reasonable with that notification. So instead, Windows requires a reboot to change the hostname. Except first boot: to avoid a reboot as soon as you power on your shiny new computer, there's a clumsy dance where the OS holds back most usermode processes until the hostname is set, then it sort of tries booting usermode again. (Huge simplification!)
Thirdly, the footprint of Windows is just bigger than that of an expertly hand-tuned Linux installation. Much of this problem was solved with Nano Server... but are you actually using Nano Server? It turns out that people like Windows because Windows runs Windows programs. Take away compatibility with many Windows programs, like Nano Server did, and you get a much faster and more secure OS that nobody's heard of.
We take both perf and cloud hosting seriously, and we're working on problems in this space. You should expect Windows to get better with each release. But to close this off, I don't want to hog all the blame. It's always possible that AWS is doing something silly in their guest agent or paravirtualization stack that measurably degrades boot perf. We've previously caught Azure doing silly things -- now fixed -- that seriously delayed the amount of time before the guest reported itself as ready. If you want to see Windows hosting done well, try Azure.
> you can use the `sysprep.exe /mode:vm` flag, which essentially tells sysprep to retain most of the device tree, since you expect to run the thing on similar hardware
In my experience that only really works with full paravirtualized environments. If you start mixing in SR-IOV things can get a little messy. Given customers actually crave high performing networks, that then presents you with a choice:
1) Make two images. One for full paravirtualized environments.
2) Ignore it and let Windows first boot time take longer.
Of course most clouds already end up with what are effectively multiple images for the same setup/configuration of Windows, one per hardware type anyway, because even with full PV things can get a bit strange, and you're often ending up with blue screens during first boot.
They're not going to want to _double_ that number. Even with full automation that's a bunch more things that can go wrong, more operational burden etc. etc. Where's the value proposition? Windows provisions a little faster?
Linux images rarely need to be produced for different hardware types / environments. They just spin up and away you go. As to your systemd/sysv comment.. even sysv based instances have a time-to-login on first boot of under a minute.
The systemd developers were obsessed with the idea that parallelism would speed up the boot process, but it doesn't make as significant a performance impact as they'd have you believe, especially when you're talking about cloud images that rarely have many services running on first boot. Even if you go trawling down the systemd boot time reporting, you'll see that most components start in fractions of a second, and the same was true under SysV too.
>Now that I have got your attention with a catchy title - let me share with some of my thoughts regarding how AWS shines and how much your experience as a customer matters.
This is the one guaranteed way to turn me off to whatever you're going to talk about in the article.
I don't think they have a pool of instances at all.
It's a generalized image which they boot up for you. Cloning the image, even though it is many gigabytes, takes milliseconds since the underlying storage (EBS) will be some log-based storage.
If they really wanted to optimize boot time, they would freeze the fully booted machine (keeping all the RAM contents) and then clone the frozen instance. That should be able to get running in just ~10 seconds (enough time to copy enough of the RAM contents to be able to log you in). They probably won't do that because having every user running from a fork of the same image could have some weird repercussions - for example the kASLR would be the same for all machines, making designing exploits much easier.
I used Windows instances a few years ago. Beyond the slow start, once started, frequently the CPU would stay stuck at very low %, and my tasks would run very slowly.
Eventually I would get to 100%, but it could often take 10 minutes.
What I learned from those pains is how to use Linux in the Cloud.
Seems like you were using T2 instances which have a low baseline performance and burst credits. I would imagine that you quickly run out of credits on some of the smaller instance types after creation, given how lengthy and costly (in terms of CPU usage) the instance creation and boot process is.
I was typically using c3.xlarge for CPU-intensive tasks (video processing).
Boot time was OK. I would log in on the machine with RDP, because sometimes my processes were almost frozen for a while. It felt like my neighbours were stealing my CPU, but I did not know how to prove it.
Once I moved to Ubuntu, same instance type, I never experienced this.
Instances launched from EBS snapshot (or EBS-backed AMI) are lazily loaded from S3, which probably explains slow performance, if you are doing lots of I/O operations (in my experience Windows is more I/O heavy, especially on boot).
From Amazon documentation[1]:
However, storage blocks on volumes that were restored from snapshots must be initialized (pulled down from Amazon S3 and written to the volume) before you can access the block. This preliminary action takes time and can cause a significant increase in the latency of an I/O operation the first time each block is accessed.
I've experienced this lately with a variety of Amazon Windows images. For example I will boot a 2016 image from this year vs one from last year and last year's will be significantly faster on the same hardware.
Its possible. I didn't run any numbers or look at patch levels. It just went from running AD FS flawlessly on one to being barely usable over RDP on the other. Now I'm interested and might have to dig up which AMIs I've been through.
AWS might as well apply any Windows Update changes so that they deliver a fully-patched and secure instance, instead of an insecure image from a few months ago. It isn't just AWS, all Windows cloud servers seem to be delivered unpatched.
Customers probably wouldn't appreciate getting a Windows instance with an inconsistent patch level, you want to know that when you start a specific AMI ID you tested in your staging environment that it will be the same AMI you launch in production.
Also they ship a new Windows instance approximately every 3-4 weeks with the most recent updates merged in. They don't make a big enough thing of it but you can subscribe to update announcements.
This is an interesting thought; I use Windows instances myself but I use a custom AMI built using Packer on our CI server. Presumably Amazon doesn't have a pool of my custom AMI images lying around.
So I wonder if the custom AMI is actually stored as a layer on top of the source Windows AMI and applied to the instance from the pool before it is made available to me.
Alternatively, it means I'm missing out on an optimisation and I could get a faster start-up time by using a vanilla Windows AMI and installing dependencies in the user data.
A couple of jobs ago I have spent plenty of time optimizing a Packer-based AMI pipeline that was similar in spirit to that which you've described. It was all quite frustrating, but then the job got yanked from underneath me, so I never finished solving the problem.
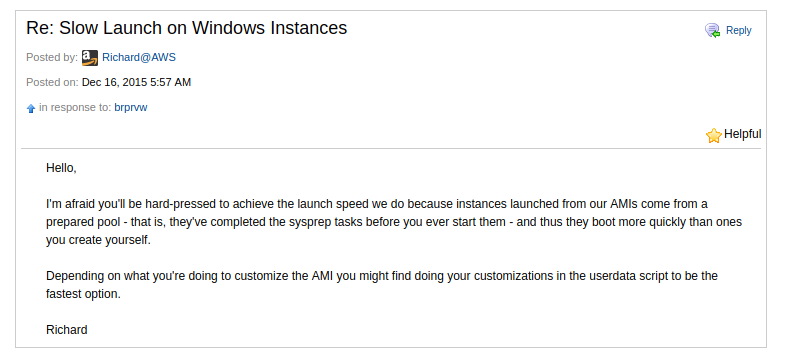
The article contains a screenshot[1] of a response from AWS support indicating that only EC2's own AMIs benefit from this pooling optimization. It follows that custom AMIs must take the startup time hit all the way.
Does AWS have to pay a license fee to maintain a pool of Windows instances? Who foots the cost of the license if a prepared/pooled instance is never allocated to a customer?
There has to be a custom deal in place, but it could be similar in spirit to a hot standby MS SQL Server instance where you only pay for one license but have a mirror of the machine ready to go if the first one goes down (my knowledge of licensing was only tangential to my dev work and could be several years out of date now).
There are MS license agreements for cloud solutions providers that allow license usage up to a certain limit, with monthly reporting of actual usage for billing purposes.
It would make sense to apply these optimizations to any kind of startup since presumably anticipating resource allocation ends up as a cost savings and improvement in user experience regardless of the base OS. There are plenty of Linux AMI images that are bloated and slow to start.
It would only be practical to do this for very commonly used AMIs that AWS create and provision themselves. Commonly used because you don't want unused AMIs languishing in the instance pool long term. Only their own, because these AMIs are heavily manipulated and then customised for the user so you have to be positive the AMI is compatible with the manipulations.
I'm pretty sure GCE does the same, just last week I had a need to test something and with 1vCPU instance was ready in about 3-4 mins. Next time will check logs to confirm it. But seems the reasanoble thing to do.
Also note AWS Windows is not plain vanilla. It comes with an x64 Python 2.7 build built in, and the x64 python27.dll is on the standard path. Bit of a gotcha if you're deploying x86 Python 2.7 to AWS Windows!
I'm curious why the author does not think AWS will confirm his analysis. He seems to have hard evidence of how the system works and communications from staff.
I could see them declining to comment to avoid creating the expectation that the system works in a particular way. Being a black box means they can make changes without breaking expectations. Documenting internals, even informally, means folks may come to expect that behavior.
My assumption is that they're not shared. Once you request an instance from the pool, if the desired number of pooled instances is still the same, another one would immediately begin the imaging process to take its place.
{kind=link}
Also the true costs of infrastructure became my problem - accounting can see exactly what a solution costs - instead of some amorphous cost in the IT budget.