It kind of feels like this is just Intel's marketing machine. The chip is less impressive than the article makes it sound, Nvidia shipped the A100 in 2020. This Intel chip doesn't even exist in a production system... and the A100 is already pretty damn close, hitting (w/ FP16) 624 TF with sparsity according to Nvidia's documentation which is at least as accurate as an unreleased data center chip from Intel:
Given the _actual_ performance metrics that they gave about its Xe HP cousin (which Intel didn't publish any indication on it having FP64 at all), I'm inclined to believe that the 1PF number is indeed some very ML-specific stuff.
It is I was amazed how with the new ceo bombastic statement for some reason magically all intel problems went away and their statements about 7nm and 10nm were believed. They are going back to tick tock cadence?. Intel are such masters of marketing in 2016 they already knew 10nm fabs were not going to work so they announced stopping tick tock.
NVIDIA's hardware and software (CUDA) badly need competition in this space -- from Intel, from AMD, from anyone, please.
If anyone at Intel is reading this, please consider releasing all Ponte Vecchio drivers under a permissive open-source license; it would facilitate and encourage faster adoption.
The One-API and OpenCL implementations, Intel Graphics Compiler, and Linux driver are all open source. Ponte Vechio support just hasn't been publicly released yet.
CUDA’s biggest advantage over OpenCL other than not being a camel was its C++ support which is still the main language in use for CUDA in production, I doubt FORTRAN was the reason why CUDA got to where it is, C++ on the other hand had quite a lot to do with it during its initial days when OpenCL was still stuck in OpenGL C-Land.
NVIDIA understood also early on the importance of first party libraries and commercial partnerships something Intel also understands which is why OneAPI has wider adoption already than ROCm.
How does CUDA support any of these (.Net, Java, etc?). It's the first time I hear this claim. There are 3rd party wrappers in Java, .Net, etc. that call CUDA's C++ API, and that's all. Equivalet APIs exist for OpenCL too...
There are Java and C# compilers for CUDA such as JCUDA and http://www.altimesh.com/hybridizer-essentials/ but the CUDA runtime, libraries and the first party compiler only supports C/C++ and FORTRAN, for Python you need to use something like Numba.
Most non C++ frameworks and implementations tho would simply use wrappers and bindings.
I also am not aware of any high performance lib for CUDA that wasn’t written in C++.
Hybridizer simply creates CUDA C++ code from C# which is then compiled to PTX it also does it for AVX which you can the compile with Intel’s compiler or gcc, it’s not particularly good and you often need to debug the generated CUDA source code yourself, it’s also doesn’t always play well with the CUDA programming model especially its more advanced features.
And again it’s a commercial product developed by a 3rd party, whilst someone uses it I wouldn’t even put it as a rounding error when accounting for why CUDA has the market share it has.
It is like everyone arguing about C++ for AAA studios, as if everyone was doing Crysis and Fortnight clones, while forgetting the legions of people making money selling A games.
Or forgetting the days when games written in C were actually full of inline Assembly.
It is still CUDA, regardless if it goes through PTX or CUDA C++ as implementation detail for the high level code.
The market for these secondary implementations is tiny, and that is coming from someone who worked at a company that had CUDA executed from a spreadsheet.
The C#/Java et. al isn’t what made CUDA popular nor what would make OneAPI succeed or fail.
CUDA became popular because of its architecture, using an intermediate assembly to allow backward and forward compatibility, it had exe Elle to support across the entire NVIDIA GPU stack which means that it could run on everything form bargain bin laptops with the cheapest dGPU to HPC cards.
It came with a large library of high performant libraries and yes the C++ programming model is why it was adopted so well by the big players.
And even arguably more importantly is that when ML and GPU compute exploded and that wasn’t that long ago NVIDIA from a business perspective was the top dog in town, CUDA could’ve been dog shit but when AMD could barely launch a GPU that could compete with NVIDIA’s mid range for multiple generations it wouldn’t have mattered.
>CUDA could’ve been dog shit but when AMD could barely launch a GPU that could compete with NVIDIA’s mid range for multiple generations it wouldn’t have mattered.
This is really the only point to be made. Intel could release open source GPU drivers and GPGPU frameworks for every language under the sun, personally hold workshops in every city and even give every developer a back massage and everyone would likely still use CUDA.
Intel has one huge advantage tho, OneAPI already supports their existing CPUs and GPUs (Gen9-12 graphics), and it’s already cross platform available on Linux, MacOS and Windows this was the biggest failure of AMD no support for consumer graphics, no support for APUs which means laptops are cut out of the equation and Linux only which limits your commercial deployment to the datacenter and a handful of “nerds”.
The vast majority of CUDA applications don’t need 100’s of HPC cards to execute, consumers want their favorite video or photo editor to work, they want to be able to apply filters to their Zoom calls, students and researchers want to be able to develop and run POCs on their laptops as long as Adobe and the likes adopt OneAPI and as long as Intel will provide a backend for common ML frameworks like Pytorch and TF (which they already do) performance at that point won’t matter as much as you think.
Performance at this scale is a business question if AMD had a decent ecosystem but lacked performance they could’ve priced their cards accordingly and still captured some market share. Their problem was that they couldn’t actually release hardware in time, their shipments were tiny and they didn’t had the software to back it up.
Intel despite all the doom and gloom still ships more chips than AMD and NVIDIA combined if OneAPI is even remotely technically competent and from my very limited experience with it it is looking rather good Intel can offer developers a huge addressable market overnight with a single framework.
I am not denying that C++ is very relevant for CUDA (since version 3.0), it is also why I never bothered to touch OpenCL.
And when Khronos woke up for that fact, alongside SPIR, it was already too late for anyone to care.
Regarding the trees, I guess my point is that regardless of tiny they are, the developers behind those stacks rather bet on CUDA and eventually collaborate with NVidia than going after to the alternatives.
So the alternatives to CUDA aren't even able to significally atract those devs to their platforms, given the tooling around CUDA to support their efforts.
Yep, CUDA running on literally anything and everything definitely helped its success. So many data scientists, ML engineers, who got into cuda by playing with their gaming GPUs.
Which is exactly the advantage Intel has over AMD, they aren’t locked to Linux only and they support iGPUs, ROCm is essentially an extension of the Linux display driver stack at this point and barely supports any consumer hardware and most importantly APUs.
I would really want to be able to find the people at AMD who are responsible for the ROCm roadmap and ask them WTF were they thinking...
"Alternatively you can let the virtual machine (VM) make this decision automatically by setting a system property on the command line. The JIT can also offload certain processing tasks based on performance heuristics."
A lot of what ultimately limits GPUs today is that they are connected over a relatively slow bus (PCIe), this will change in the future, allowing smaller and smaller tasks to be offloaded.
Oooh, I didn’t know PTX was an intermediate representation and explicitly documented as such, I really thought it was the actual assembly ran by the chips…
PTX is a virtual ISA and the reason why ROCm is doomed to fail well beyond its horrendous bugs.
ROCm produces hardware specific binaries which not only means you need to produce binaries for multiple GPUs but you also don’t have any guarantee for forward compatibility.
A CUDA binary from 10 years ago will still run today on modern hardware, ROCm breaks compatibility between minor releases sometimes and it’s often not documented.
You can get the GPU-targeted assembly (sometimes called SASS by NVIDIA) through specifically compiling to a given GPU then using nvdisasm, which also has a very terse definition of the underlying instruction set in the docs (https://docs.nvidia.com/cuda/cuda-binary-utilities/index.htm...).
But it's one way only, NVIDIA ships a disassembler, but explicitly doesn't ship an assembler.
in addition, grCuda is a breakthrough that enable interop with much more languages such as Ruby, R, Js, (soon python), etc
https://github.com/NVIDIA/grcuda
I don't have specific knowledge of Ponte Vecchio in particular, so I'll defer to you if you have such info. The support for their mainstream GPU products is open source, though.
CUDA is not as important as Tensorflow, PyTorch and JAX support at this point. Those frameworks are what people code against, so having high quality backends for them are more important than the drivers themselves.
Can you give me another GPGPU framework that puts in the effort to have up-to-date benchmark comparisions between different hardware?
Just as an example I just bought an M1 laptop. Even PyTorch CPU cross-compiling hasn't been done properly, and TensorFlow support is full of bugs. I hope that with M1X it will be taken more seriously by Apple.
I understand your point (Julia is a great example), but trying to support a rarely used hardware with a rarely supported framework is just not practical. (Stick with CUDA.jl for Julia :) )
OneAPI is already cross platform through codeplay’s implementation which also can run on NVIDIA GPUs, its whole point is to be open cross platform framework that targets a wide range of hardware.
Wether it would be successful or not is up in the air but it’s goals are pretty solid.
So basically, a thing that will provide first-class capabilities only on Intel hardware, and won't be really optimised for maximum performance/expose all the underlying capabilities of the hardware elsewhere.
I really don't get this push to polyglot programming when 99% of the high performance libraries use C++. Even more, openAPI has DPC++, SPIR-V has SYCL, CUDA is even building a C++ standard library that is heterogeneous supporting both CPU and GPU, libcu++. Seriously now, how many people from JVM or CLR world actually need this level of high performance? How many actually push kernels to the GPU from these runtimes? I have yet to see a programming language that will replace C++ at what it does best. Maybe Zig because it is streamlined and easier to get into will be a true contender to C++ HPC but only time will tell.
Enough people to keep a couple of companies in business, and NVidia doing collaboration projects with Microsoft and Oracle, HPC is not the only market for CUDA.
Indeed it is, but the developers in these ecosystems created complements like Apache Arrow that will unload the data in a language-independent columnar memory format for efficient analytics in services that will run C++ on clusters of CPUs and GPUs. Even Spark has rewritten their own analytics engine in C++ recently. These were created because of the limitations of the JVM. We have tried to move the numerical processing away from C++ in the past decades but we have always failed.
You asked who in the JVM world would be interested in this kind of performance: that's big data folks. To the extent that improvements accrue to the JVM they accrue to that world without needing to rewrite into C++.
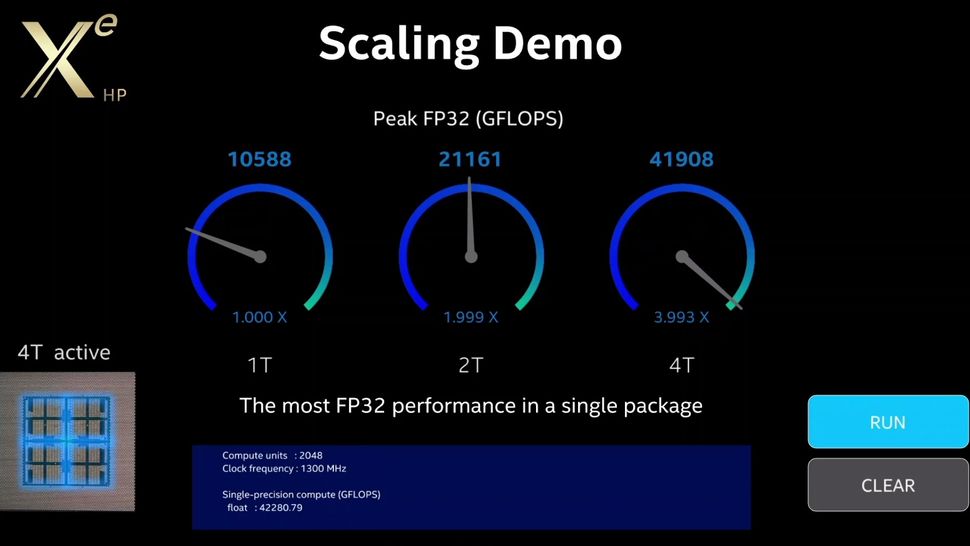
The Cebras prototype was about 0.86 PFLOPS (?) for a whole wafer (1T transistors) so this Intel chip looks like a potential viable competitor at 1PFLOP for only 100B transistors (even if just FP16). I'm sure Intel will want to chase NVidia but Cerebras is also a threat given it already has software support (Tensorflow, Pytorch, etc). Maybe I'm making an unfair comparison but looks Ponte Vecchio would put Intel just above where Cerebras was a couple years ago.
These PFLOP measurements aren't very comparable. Benchmarks are probably the best way to see which chip is better. For example, Cerebras claims ~1PFLOPS, but has not put out any numbers showing that that actually is the case, on standard machine learning models such as ResNet, Transformers, or others. Their hardware is basically DoA.
Manufacturing the chip-lets independently appears to be an interesting approach to maximizing yields. If anyone component has a defect, you just assemble using a different chip-let, as opposed to it affecting the final product.
Anyone know how this affects power, compute, or communications metrics compared to monolithic designs?
Or am I off in thinking this approach maximizes yields?
> Anyone know how this affects power, compute, or communications metrics compared to monolithic designs?
It does effect ennormously, but everything is highly design specific.
The die size limits are not only yield related.
Power, and clock have stopped scaling few generations ago.
New chips have more, and more disaggregated, independent blocks separated by asynchronous interfaces to accomodate more clock, and power domains.
If you have to break a chip along such domain boundary, you loose little in terms of speed unlike if you did it right across registers, logic, and synchronous parallel links.
Caches also stopped scaling too, and making them bigger, also makes them slower.
Instead, more elaborate application specific cache hierarchies are getting popular. L1-2 get smaller, and faster, but L3 can be made to ones fantasy: eDRAM, standalone SRAM, stacked memory etc.
This ( EMIB ) is suppose to be the most interesting part of the announcement but most of the discussion seems to focused on CUDA / One-API.
>Or am I off in thinking this approach maximizes yields?
This is absolutely the case here especially for HPC or high performance market where they are all previously served by large die size solutions. You can also use the best node for each tiles / chipsets. Example I/O die may use other node for lower power consumption while Compute die uses High power node to push performance. High Density node for SRAM, low cost node for simple function accelerator etc. You can now customise each part of the tiles/chiplet best according to your target power/performance/cost equation.
Now of course their are trade offs, Intel Tiles packaging (EMIB, Embedded Multi-die Interconnect Bridge) is expensive. And it adds tiny latency for not being on die. Although you could argue you saved latency for certain parts with it not being off a PCIE bus.
But this is very exciting. The best part is with this announcement that you can use Tiles and Chiplet from other foundries on Intel packaging! You could theoretically use Global Foundry ( or Samsung ) FD-SOI node for certain applications and still be on the same packaging. You can now truly mix and match to the maximum.
Not so good part is we are still limited by TDP design. And I dont see anything being done in the consumer / prosumer space.
Actually - regardless of the performance of this, and perhaps this is orthogonal to their GPU - with the global crunch in chips/GPU, would this be a natural market space for Intel, especially with the new foundry services, to compete? I would imagine there is a lot of business to be had from Nvidia/AMD for GPUs...assuming the mining boom holds up.
Intel with their own production facilities seems to manage the shortage better than everyone else. Their product may be worse, but their supply situation has been consistently better since December.
Well, that's likely true, though it underestimates how many people will continue to buy the established option regardless of a better alternative being around.
But when not a single AMD processor is available and Intel processors are, that's just logical. Later on AMD processors were available, but way more expensive than before, with Intel selling nice options like the i5-10400F at their lowest price ever. That price difference in essence still continues today. Right now at that price point the Intel offering is unbeatable for AMD.
To a certain extent, they have to compete on price.
Price elasticity of demand for AMD is partially dependent upon the price of Intel chips. There will always be pricing pressure, even if there is scarcity of AMD chips, because to some extent AMD and Intel chips are substitute goods.
Your comment gets far less sensible if you consider just how many CPUs are purchased directly by PC manufacturers, for whom supply continuity is very important. Lenovo isn't going to "wait a few months," even if some individual purists would be willing to do so.
I can't shake the feeling that buying anything with Intel today is like buying already obsolete technology.
Did I get myself too much under influence of advertisement etc. or is it valid to an extent?
My laptop is currently 3 years old so I am looking for a replacement and it seems like there is no point to buy anything right now apart from M1 and AMD is out of stock everywhere. But even latest AMD processors are not that great of an upgrade. So I am left with M1, but I cannot support this company politics and my conclusion is that I am going to stick to my old laptop for a time being...
3 years isn't that old. Unless someone else is footing it, keep using what works for you. The 14nm Intel laptops haven't changed much in that time.
Very small laptops with Intel Tigerlake are on level with AMD and Apple products. They have all the new IO bits (PCIe 4, LPDDR4x, Wifi6) and low power usage on 10nm.
If you wanted a bit more battery life, performance, or just want to try a fancier display upgrading could be nice.
I don't see Apple laptops having worse politics than other companies. On my iPad I feel the lots of problems of the closed ecosystem, but M1 laptops are accessable enough for developers to work with (even though it is sadly undocumented).
I still use a trusthy Asus bought in 2009, other than requiring additional fan under it, and a new battery, it is a perfectly working computer usable as desktop replacement for my coding activities.
We are long past the days of buying a new computer every couple of years.
Alder Lake is still only 8+8 big+small cores, while you can already get 16 big cores in 5950X with hopefully Zen3 Threadrippers in the pipeline coming soon now that Milan is out. Feels like Intel has little to offer in competition.
Every time I see someone mention 5950x on HN or Twitter, I check Best Buy to see if it's in stock, and so far it has never been available. It could be the standout desktop chip in its market segment, but sellers are asking over a grand for it on Amazon. If the average PC builder takes price and availability into consideration when choosing a CPU, then those factors matter too.
I'm not sure who started showing images with the Integrate Heat Spreader removed, I feel it must have been AMD with the chiplet design, but those shiny chips do look shiny :)
This will probably be a nightmare for a consumer product.
Too many components from too many different sources, with intel doing the "integration".
Doesn't this remind anyone of the engineering philosophy of the Boeing 787 Dreamliner? Have individual manufacturers build component parts and then use just in time integration to put assembly and packaging at the end. If any individual manufacturer runs out of chips or components, or de-prioritize production (for example, if Samsung or TSMC is being ordered by Korea or Taiwan to specifically prioritize chips for their automotive industries) - this could lead to shortages that will cause ripples down the assembly line for these xe-hpc chips.
Especially in today's world, when companies like Apple are constantly moving toward vertical integration, and bringing in all external dependencies inward (or at least have ironclad contracts mandating partners satisfy their contractual duties), this move by intel is in the wrong direction in the post Covid-chip shortage era.
"Intel usually considers FP16 to be the optimal precision for AI, so when the company says that that its Ponte Vecchio is a 'PetaFLOP scale AI computer in the palm of the hand,' this might mean that that the GPU features about 1 PFLOPS FP16 performance, or 1,000 TFLOPS FP16 performance. To put the number into context, Nvidia's A100 compute GPU provides about 312 TFLOPS FP16 performance. "
{kind=link}
{kind=link}
https://www.nvidia.com/en-us/data-center/a100/
I'd guess, by the time Intel actually ships anything useful, Nvidia will have it made it mostly moot.