Well before Bulldozer had taped out, AMD briefed us on the high level processor plans (our software was included in BAPCo Sysmark and we'd been a very early adopter of AMD64, so we had lots of these meetings). I told them that it was a total mismatch for our workloads (audio and video production tools) and would prove to be a bad fit. They protested at first, as our inputs and outputs were fixed point formats and the doubled-up integer/logic units would allow us to thread more. That's when I spelled it out:
1. Our business logic and UI each basically operated in single threads.
2. Our intermediate audio and video processing buffers were floating point or moving in that direction in the future.
3. Wherever possible in filtering and effects, we avoided branching, relying on zero-folding in vector instructions.
I went on to explain where they'd be in trouble for game engines, document processing, and other key use-cases.
Their hardware architects slowly sank in demeanor over the course of that all-day meeting. I later heard from contacts at AMD that it was an "oh shit" moment for them. That said, having been at Sony at the time, we'd gone down the long dark road of the Cell...
Sometimes people try bold and interesting things that don't work. Bulldozer was definitely one of those, and it should have been killed (or at least diverted), like Larrabee. Nonetheless, AMD survived, and their current architectures owe some of their thinking to the hard-learned lessons of Bulldozer.
Meanwhile the "efficiency cores" in the latest processors (both x86 and ARM) are basically optimal for precisely those highly threaded integer workloads. Bulldozer was just too early for its time.
I totally agree that Bulldozer was ahead of its time. In some ways, it was a case of being too clever, trying to do things under the hood for the FPU similarly to Hyper-Threading for decoder/front-end resources (which also caused problems). Getting integrated with the underlying software (e.g., the kernel and its scheduler) in big.LITTLE was a comparative revelation.
Conversely, the Cell took this too far, requiring that high level software be deeply SPE and memory-shuffling aware, almost like having a bank of DSPs in-package. The instruction-set/functional difference between the PPE and SPE made for encumbrances that likely would never have been fully solved by the toolchain (even if the toolchain had shipped ahead of the processor rather than well afterwards).
Larrabee made attempts to solve the instruction set difference problem (in a very Intel way), but the topology, cache behavior, and pure core size proved to be far too limiting in real applications. In the end, Intel missed on the balance of core/execution-unit size vs. count when compared to Nvidia and ATI. GPGPU progress has definitely demonstrated the value of toolchain abstraction, though, and adherence to a given instruction set (and the architectural implications that came from that) proved to be a limiting constraint for Larrabee.
The last 20-25 years in compute architecture design have seen many interesting articulations of clever ideas. Some deaths were predictable, but each of the explorations should be commended for the ways that they pushed boundaries and cleared the path for their successors.
I think you could draw somewhat different lessons from this, though:
- Cell failed because it required too much work and was too incompatible with any other platform (save for DSPs).
- Larrabee failed because KNC wasn't binary compatible and the toolchain was too much of a pain to work with, and KNL/KNM "failed" because they were too hard to get (although, I think "failed" is perhaps too strong here, the "lots of general-purpose cores with vector units" is exactly where Intel, AMD, and the aarch64 vendors have gone since). KNC's lack of binary compatibility is really what got things off on the wrong foot, the whole advantage it had over AMD/Nvidia GPUs was it amenability to GPU-unfriendly code, but I think the barrier of having to rebuild everything was prohibitive for many of the smaller users who would have been well-positioned to use it.
- NVidia "won" in the GPGPU space because CUDA and its libraries have provided a stable-enough basis for complex applications to use, and the underlying hardware has evolved to be ever more performant and capable.
- AMD "failed" in the GPGPU space because their toolchain abstraction is too weak and compatibility is poor. Unlike CUDA, there's no capable API that works on the whole range (even with OpenCL AMD's support is questionable at times, with two totally different driver stacks).
I'd say the biggest lessons are: (1) compatibility with existing code is king, and (2) toolchain and hardware accessibility is critical. You can survive breaking (1) if your tools are good enough, but you can't win by breaking both of them.
> Unlike CUDA, there's no capable API that works on the whole range
Microsoft's D3D is very capable, and vendor-agnostic, same code works on all GPUs because the user-mode half of the GPU driver includes a JIT compiler for these shaders.
Not sure why it's not popular outside of game development. IMO their GPGPU API is the best one currently available.
D3D is the exception to basically everything in graphics-land, avoiding the pitfalls that basically every other cross-hardware-vendor API suffers. The problem, obviously, is that it is Windows-only. It's only popular in cases where the rest of the system is also Windows-only, since otherwise you'd have to write multiple backends anyways (at which point you either stick to OpenCL, or you do both CUDA and OpenCL for better performance).
Being limited to Windows makes DirectCompute a non-starter to basically anything in the HPC/server/embedded space.
...and Lisa Su was, at IBM, the team lead of the Cell CPU. Zen, about ten years later, was designed to be largely "performance compatible" with Intel Core. Similar cache, buffer, decode, etc sizes and characteristics to Core. Lessons learned, I guess.
Others have covered it here, using masks, multiplies, or horizontal operations to avoid branching by running the logic for all of the branches is common in vectorized code (and shader operations for similar reasons), where raw compute outruns branch mis-prediction costs for deeply pipelined processors.
In older SSE architectures, memory alignment and register-to-register result latencies sometimes made it easier/better to stride operations on partially-masked registers rather than reorganize the data. With high architectural register counts and newer shuffling instructions, that need is lower.
Definitely avoid branching in tight compute code, though. Branching kills performance, sometimes in very data-dependent and annoying ways.
“Avoid branches” isn’t strictly true in scalar code (and sometimes vector code) - zero folding leads to longer dependency chains, so if your branch is very predictable and doesn’t preclude other optimizations (I.e. vectorizing) the branch can be faster.
You mileage may vary, depending on how much reordering capacity the hardware has, how good the branch predictor is, how expensive a mispredict is, whether the extra dependency chains are impactful, etc.
To add to your last point: look at the optimised assembly and see if your code actually does contain branches. The compiler can see through certain if statements and replace them with cmov instructions. Replacing that with a complex sequence of arithmetic to get rid of the 'if' might make performance worse rather than better.
No rule is strictly true in optimization, except the rule that no rule is strictly true in optimization...
It's quite often the case that branches are bad for performance in tight loops, so It's better to treat branches as likely sources of trouble than as no big deal.
You don't need to multiply by zero; there are comparison operations which will generate a mask value which can then be used to select the appropriate value (`vsel` for altivec, `_mm_blend_ps` for sse4, or a combination of `_mm_and_ps` / `_mm_andnot_ps` / `_mm_or_ps` for ssse3 and earlier)
At least on Xbox 360 / Cell, high performance number crunching code would often compute more than needed (ie: both the if-case and else-case) and then use a branchless select to pick the right result. It may seem like a waste but it was faster than the combination of branch misprediction as well as shuffling values from one register file to another to be able to do scalar comparisons.
That instruction uses a mask provided at compile time; it encodes the mask as a part of the instruction. SSE 4 set has a similar one, `_mm_blendv_ps`, which does take the mask from another vector register.
I remember deliberating between AMD's eight core FX-8150 and the latest Intel Sandy Bridge in early 2012.
Even though lots of people consider Bulldozer to be an AMD misstep, I don't regret my choice: AMD's eight integer cores performed favorably compared with the four real cores plus four hyperthreads of the Intel. Considering I bought it to be used primarily for compiling, it was a good choice.
This is an interesting read, and seeing the design choices with knowledge of how things turned out later makes it even more interesting.
i used an fx-6300 for years and it was fine. for most use cases the practical need for desktop cpu performance plateaued 10 years ago. during that time adding more memory and moving from hdd to ssd made a much larger difference in user experience than increasing the cpu performance.
the biggest problem for amd was not the architecture of the cpu, but the lack of integrated graphics on high end parts, and power efficiency on mobile. both of which were caused by being stuck on an older process.
it's also worth remembering that internally amd had a grand vision of unifying the cpu and gpu (HSA) which would have added a bunch of fp compute to the integrated chip, but that vision required a lot of other things to go right, and a lot of them went wrong, so it never happened.
> for most use cases the practical need for desktop cpu performance plateaued 10 years ago
This drives me insane, literally every day my computer spends minutes - likely hours in total in a day - blasting at 100% CPU and it's not a ten years old one. Hell, I got access to a threadripper 5990X and even that one I sometimes end up in situations where I have to wait for CPU operations to finish, even for basic life things such as uncompressing archives or editing pictures so I really cannot understand
High memory use will still peg a CPU at 100%. They don't get many opportunities to do other things while waiting for cache refills. Increasing core speed/single thread performance will not help much in memory-bound tasks.
A lot of core functionality like dealing with zip files hasn't been updated for modern times, and doesn't support multiple cores. So it's likely you're using just one core to uncompress stuff.
sure, if you have a modern system with plenty of ram and ssd, then cpu will still be a bottleneck.
what i am saying is that if given a choice of a brand new cpu with 8gb ram and a hard drive (common specs for 10 years ago) or a 10 year old cpu with 16gb ram and an ssd, then i would definitely take the 10 year old cpu.
case in point, i recently bought this super cheap dell laptop, which has a really nice brand new cpu (i5-1135G7) but only 8gb ram and a crappy ssd. i will upgrade those things when i have the time, but right now if i am running too many things it will start swapping out, and that is far worse than maxing out the cpu.
I agree and I also think the timing of it's release helped as well. It came out about a year before the new Xbox and Playstation consoles were released and which were both using AMD silicon. So from a gaming perspective it was passable.
It could run last gen console ports well and didn't struggle much with next gen. I had a FX-8320E that was used almost exclusively for gaming and it was fine.
I'm assuming you're talking about PS4 and Xbox One. If so, they used a much simpler and lower-power architecture than Bulldozer that was initially intended for netbooks and tablets.
I had a programmer friend who got the FX-8150 in 2012 for compiling - pricewise it was basically equivalent to a i5 but you got 8 integer cores in return. It's a decent choice if you prioritize core count over single-core/FP performance.
Efficiency wise those desktop CPUs were space heaters, with the FX-9590 coming to mind. Pre-Zen laptops were also notorious for poor battery life.
> I had a programmer friend who got the FX-8150 in 2012 for compiling - pricewise it was basically equivalent to a i5 but you got 8 integer cores in return.
but the integer cores shared a frontend which alternated between feeding the two cores, so using all 8 threads (2 threads per module) reduced per-thread performance even further from the already abysmal 1TPM performance levels.
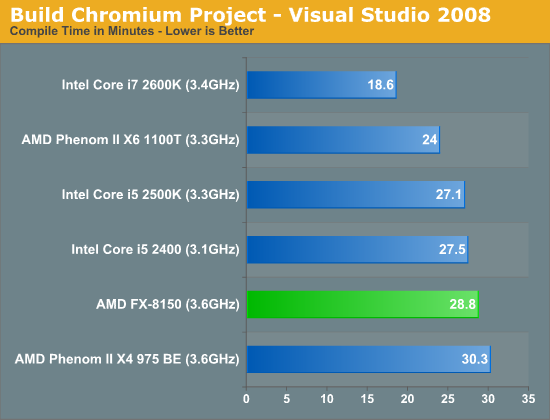
The FX-8150 failed to outperform a 2500K in compiling let alone a 2600K. In fact it was significantly slower than a Phenom II X6, which was much closer to the 2600K while the FX-8150 failed to even match the 2500K.
You can see how hard that shared frontend hits - Phenom with 6 "modules" curbstomps the Bulldozer in compiles despite having "fewer threads". It's not just that Bulldozer IPC is bad per-thread and it's made up with more threads, using more threads actually causes further reductions of the IPC which destroy a lot of the benefits of having those threads in the first place. It was not a good processor even in heavily multithreaded loads, outside some happy cases.
Frankly there was just as much of a fanboy effect in those days as in the early days of Ryzen, which really wasn't justified by the actual performance. Most actual productivity loads used AVX which strongly favored Intel over Ryzen due to the half-rate AVX2, the 5820K did great in those workloads for a very affordable price and was also much better in gaming/etc, plus had massive overclocking headroom. But people tend to laser-focus on the handful of very specific workloads Ryzen 1000 did OK at. Intel was generally much more potent per-core if you did video encoding, for example, or in later Cinebench variants that used AVX. But Ryzen looked real good in pre-AVX cinebench R11.5 and R15 so that's what people cited.
People bought Bulldozer because they had always bought AMD and that was the brand they identified with on a social level. It was a terrible product and only slightly mitigated by the Piledriver series (FX-8350)... which had to go up against Ivy Bridge and later Haswell, where it was just as far behind.
Same story as Phenom. Bulldozer would have been a competitive product if it got to market 2 years earlier and didn't need another couple years to fix the deficiencies.
These were interesting results then, but I think code generation and OSes have evolved enough that current compiles on a current OS with a current toolchain are actually faster on an FX-8150 than on an i5 of the age from those results.
Even from the time that Ryzen first came out until now, OSes have been improving threading, reducing contention, et cetera, to noticeable degrees.
Tell you what - when I'm back on the coast that has my older machines, I'll run some modern compiles on a quad i5 of that era and on my FX-8150, and we'll see. If nothing else, perhaps it'll be interesting to see how much threading performance has improved in the last decade.
BTW - I did do side-by-side testing back then between the quad i7 and the FX-8150, and the results were certainly not as clear cut as these. Then again, I wasn't building a huge, barely portable source tree with -J 8 like Chromium - I was building many separate things in parallel at the same time. The cost is what ultimately tipped me in favor of AMD.
Not everyone who bought AMD then was necessarily a fanboi, and I'd point out that people who were fans of the Ryzens when they were new often liked both how they were very favorably priced compared with anything Intel, plus how we were assured that later Ryzens would work in our then current motherboards. Having just replaced a Ryzen 2600 with a Ryzen 5700X and seeing overall power usage go down, I'd have to disagree with your early Ryzen sentiment.
I am still using a FX-8xxx (and probably will until RISC-V will beat it), and haven't even bothered overclocking it yet.
Anyone knows what kind of issues having "The frontend, FPU, and L2 cache [] shared by two threads" causes compared to 2 real cores / 2 hyper threads on 1 core / 4 hyper threads on 2 cores ?
Read the "bottlenecks in bulldozer" section, particularly the parts about instruction decode (never say x86 doesn't have any overhead) and instruction fetch. Or see the excerpt I posted below.
(author here) With hyperthreading/SMT, all of the above are shared, along with OoO execution buffers, integer execution units, and load/store unit.
I wouldn't say there are issues with sharing those components. More that the non-shared parts were too small, meaning Bulldozer came up quite short in single threaded performance.
My ELI5 understanding is it's a problem of throughput and resource availability.
Long story short, running two threads with only enough hardware to run just one at full speed means any thread that tries to run at full speed will not be able to.
It would work fine with double integer loads, or heavily integer based work with the occasional FPU necessity. The problem wasn't throughput as much as the latter: it didn't have enough FPU resources and would get deadlocked waiting on availability; so would behave in the worst case (as a single core) more often than not.
The problem isn't execution unit throughput at all, it's decode, where running the second thread on the module would bottleneck the decoder and force it to alternate between servicing the two threads. And this doesn't really matter what is running on the other core, it simply cannot service both cores at the same time regardless of instruction type even if the first core isn't using all its decode. If it has to decode a macro-op, it can even stall the other thread for multiple cycles.
> Each decoder can handle four instructions per clock cycle. The Bulldozer, Piledriver and Excavator have one decoder in each unit, which is shared between two cores. When both cores are active, the decoders serve each core every second clock cycle, so that the maximum decode rate is two instructions per clock cycle per core. Instructions that belong to different cores cannot be decoded in the same clock cycle. The decode rate is four instructions per clock cycle when
only one thread is running in each execution unit.
...
> On Bulldozer, Piledriver and Excavator, the shared decode unit can handle four instructions per clock cycle. It is alternating between the two threads so that each thread gets up to four instructions every second clock cycle, or two instructions per clock cycle on average. This is a serious bottleneck because the rest of the pipeline can handle up to four instructions per clock.
> The situation gets even worse for instructions that generate more than one macro-op each. All instructions that generate more than two macro-ops are handled with microcode. The microcode sequencer blocks the decoders for several clock cycles so that the other thread is stalled in the meantime.
> But as you might think, nobody at AMD envisioned it that way in the planning or design stages. No engineer would ever start working with the idea to “build a shit product”;
That made me chuckle. There are many reason for why a design turns sour, but actual malice is rarely on of them - although it may feel that way for the user.
On the other hand: I can very well imagine some senior staff rolling eyes but feeling unfree to 'spoil the mood' by explaining how certain choices are going to come back and create problems later on.
I find it superinteresting, but also superhard to have that sort of feedback as things are ongoing. I've seen both happen (old hats hating progress too), but I was never successful (not in those larger above-my-paygrade-but-visible-nonetheless) in having a conversation about how we're having the discussion and whether or not every point/everyone is seriously hearda and considered. There can be a 'mood' that is overriding, and I haven't found a way to override the mood. Things tend to have to break down before that can happen.
I've found that when in discussions where choices made now will create problems in the future it's useful to raise that issue by couching it as a potential issue of priorities. Yes, the short-term solution may create problems in the long-term but sometimes the short-term priorities are more important. Taking on a tech debt isn't inherently bad, it's when you take it on unknowingly or without a full understanding of the terms of that debt that it goes bad.
Just as with any other debt, the cost in the long term must be balanced against the needs of the short term. And as with any other debt, if someone takes on that debt and then decides to ignore repayment there will be much wailing and gnashing of teeth when the bill comes due. ;)
>> Each module was designed to run two threads. The frontend, FPU, and L2 cache are shared by two threads, while the integer core and load/store unit are private to each thread.
If I recall correctly, they ended up calling each module 2 cores. I thought in the beginning that each module would be a single core running 2 threads. I've always thought the problem was marketing. If Bulldozer was sold as having half the cores, it's multithreaded performance would have been spectacular while single thread was meh. But some have said those modules were too big (expensive) to be sold as a single core.
I have no proof, but the use of the word "module" seems to support the confusion around what constitutes a core vs thread.
There is enough actual stuff so that each integer core is, in fact, a separate, distinct core. The issue is that there was only technically one FPU core per two integer cores. AMD paid out $12 million because they called these individual cores, and the case was decided against AMD because of the single FPU per core module:
> and the case was decided against AMD because of the single FPU per core module:
this has always been a massive oversimplification and misrepresentation from the AMD fanclub. the case was decided because of shared resources including the L2 and the frontend (fetch-and-decode, etc) which very legitimately do impact performance in a way that "independent cores" do not.
Citing the actual judgement:
> Plaintiffs allege that the Bulldozer CPUs, advertised ashaving eight cores, actually contain eight “sub-processors” which share resources, such as L2 memory caches and floating point units (“FPUs”). Id. ¶ 37–49. Plaintiffs allege that the sharing of resources in the Bulldozer CPUs results in bottlenecks during data processing, inhibiting the chips from “simultaneously multitask[ing].” Id. ¶¶ 38, 41. Plaintiffs allege that, because resources are shared between two “cores,” the Bulldozer CPUs functionally only have four cores. Id. ¶ 38–43. Therefore, Plaintiffs claim the products they purchased are inferior to the products as represented by the Defendant. Id. ¶ 39
This is completely correct: the chip only has one frontend per module which has to alternate between servicing the two "cores" and this does bottleneck their independent operation. It is, for example, not the same thing as a "core" used on Phenom and this significantly impacts performance to a hugely negative extent when the "second thread" is used on a given module.
It's fine to do it, this same approach is used in SPARC for example, but SPARC doesn't market that as (eg) a "64 core processor", they market it as "8 cores, 64 threads". But AMD wanted to have the marketing bang of having "twice the cores" as intel (and you can see people representing that even in this thread, that programmers bought AMD for compiling because "it had twice the cores", etc). And that is not how anyone else has marketed CMT before or since, because it's really not a fair representation of what the hardware is doing.
Alternately... if that's a core then Intel is definitely a core too, because basically CMT is just SMT with some resources pinned to specific threads, if you want to look at it like that. After all where is the definition that says an integer unit alone is what constitutes a core? Isn't it enough that there are two independent execution contexts which can execute simultaneously, and isn't it a good thing that one of them can use as many resources as possible rather than bottlenecking because of an execution unit "pinned" to another thread? If you accept the very expansive AMD definition of "core" then there's lots of weird stuff that shakes out too, and I think consumers would have found it very deceptive if Intel had done that like AMD, that’s obviously not what a “core” is, but it is if you believe AMD.
AMD did a sketch thing and got caught, end of story. No reason they should call it anything different than the other companies who implement CMT.
I hate hate hate the "AMD got skewered because they didn't have an FPU" narrative. No, it was way more than the FPU, and plaintiffs said as much, and it's completely deceptive and misrepresentative to pretend that's the actual basis for the case. That's the fanclub downplaying and minimizing again, like they do everytime AMD pulls a sketchy move (like any company, there have been a fair few over the years). And that certainly can include El Reg too. Everyone loves an underdog story.
Companies getting their wrists slapped when they do sketchy shit is how the legal system prevents it from happening again and downplaying it as a fake suit over crap is bad for consumers as a whole and should not be done even for the “underdog”. The goal shouldn’t be to stay just on the right side of a grey area, it should be to market honestly and fairly… like the other companies that use CMT did. Simple as.
To wit: NVIDIA had to pay out on the 3.5GB lawsuit even though their cards really does have 4GB. Why? Because it affected performance and the expectation isn't mere technical correctness, it's that you stay well on the right side of the line with your marketing's honesty. It was sketch and they got their wrist slapped. As did AMD.
The UltraSparc T1 shared the one FPU and the one logical L2 between all 32 threads/8 cores. L2 is very common to share between cores, the world has more or less converged on a shared L2 per core complex, so 4 to 8 cores. And you still see vector units shared between cores where it makes sense too, for instance Apple's AMX unit is shared between all of it's cores.
It's really only the frontend and it's data path to L1 that's a good argument here, but that's not actually listed in the complaint.
And even then, I can see where AMD was going. The main point of SMT is to share backend resources that would otherwise be unused on a given cycle, but these have dedicated execution units so it really is a different beast.
> And even then, I can see where AMD was going. The main point of SMT is to share backend resources that would otherwise be unused on a given cycle, but these have dedicated execution units so it really is a different beast.
Sure, but wouldn't it be ideal that if a thread wasn't using its integer unit and the other thread had code that could run on it, you'd allow the other thread to run?
"CMT" is literally just "SMT with dedicated resources" and that's a suboptimal choice because it impairs per-thread performance in situations where there's not anything to run on that unit. Sharing is better.
If the scheduler is insufficiently fair, that's a problem that can be solved. Guarantee that if there is enough work, that each thread gets one of the integer units, or guarantee a maximum latency of execution. But preventing a thread from using an integer unit that's available is just wasted cycles, and that's what CMT does.
Again: CMT is not that different from SMT. It's SMT where resources are fixed to certain threads, and that's suboptimal from a scheduling perspective. And if you think that's enough to be called a "core", well, Intel has been making 8-core chips for a while then. Just 2 cores per module ;)
Consumers would not agree that's a core. And pinning some resources to a particular thread (while sharing most of the rest of the datapath) does not change that, actually it makes it worse.
> It's really only the frontend and it's data path to L1 that's a good argument here, but that's not actually listed in the complaint.
That's just a summary ;) El Reg themselves discussed the shared datapath when the suit was greenlit.
And you can note the "such as" in the summary, even. That is an expansive term, meaning "including but not limited to".
If you feel that was not addressed in the lawsuit and it was incorrectly settled... please cite.
Again: it's pretty simple, stay far far clear of deceptive marketing and it won't be a problem. Just like NVIDIA got slapped for "3.5GB" even though their cards did actually have 4GB.
With AMD, "cores" that have to alternate their datapath on every other cycle are pretty damn bottlenecked and that's not what consumers generally think of as "independent cores".
> Sure, but wouldn't it be ideal that if a thread wasn't using its integer unit and the other thread had code that could run on it, you'd allow the other thread to run?
> "CMT" is literally just "SMT with dedicated resources" and that's a suboptimal choice because it impairs per-thread performance in situations where there's not anything to run on that unit. Sharing is better.
> If the scheduler is insufficiently fair, that's a problem that can be solved. Guarantee that if there is enough work, that each thread gets one of the integer units, or guarantee a maximum latency of execution. But preventing a thread from using an integer unit that's available is just wasted cycles, and that's what CMT does.
Essentially, no, what you're suggesting is a really poor choice for the gate count and numbers of execution units in a Jaguar. The most expensive parts are the ROBs and their associated bypass networks between the execution units. Doubling that combinatorial complexity would probably lead to a much larger, hotter single core that wouldn't clock nearly as fast (or have so many pipeline stages that branches are way more expensive (aka the netburst model)).
> And you can note the "such as" in the summary, even. That is an expansive term, meaning "including but not limited to".
Well, except that I argue it doesn't include those at all; shared L2 is extremely common, and shared FPU is common enough that people don't really bat an eye at it.
> If you feel that was not addressed in the lawsuit and it was incorrectly settled... please cite.
I'm going off your own citation. If you feel that after that these were brought up in the court case itself you're more than welcome to cite another example (ideally not a literal tabloid, but keeping the standards of the court documents you cited before).
> With AMD, "cores" that have to alternate their datapath on every other cycle are pretty damn bottlenecked and that's not what consumers generally think of as "independent cores".
That's not how these work. OoO Cores are rarely cranking away their frontends at full tilt, instead they tend to work in batches filling up a ROB with work that will then be executed as memory dependencies are resolved. The modern solution to taking advantage of that is to aggressively downclock the front end when not being used to save power, but I can see the idea of instead keeping it clocked with the rest of the logic and simply sharing it between two backends as a valid option.
But even this article states that the L2 and front end aren't bottlenecks on simultaneous operation.
Perhaps it'd be more accurate to say that the case was lost primarily based on the strength of the argument that there are four FPUs, considering how there had been other examples of independent cores sharing L2 and other things.
Cue the “fine wine” bulldozer memes. Are the memes grounded on reality though? Plenty of youtube videos from 2020 or later showing the 8350 displaying some impressive results for their age, specially on proper multithreading stuff.
Seems like where AMD went wrong is expecteing programmers to be able to easily take advantage of multithreading... while in reality the extra performance is often not worth the extra complexity, and sometimes it's even impossible to implement ?
Well, one big aspect is gaming, and in particular consoles at that time only had few cores. That changed few years later with ps4/xb1, but of course it took bit longer for gamedevs to catch up.
It didn't help that it was also time when Intel was at top of their game, still pushing significant single-thread perf improvements. Sandy Bridge, which was Bulldozers main competitor, was exceptionally successful launch on its own right
For some years, and especially during the last six months before the Bulldozer launch in 2011, AMD has continuously made various claims about its performance, always stressing that it will crush Sandy Bridge, due to having a double number of "cores".
Immediately after launch, all the AMD claims were proved to be shameless lies. There is absolutely no excuse for AMD. Intel had published accurate information about the performance of Sandy Bridge, one year in advance. Even without the advance publication, the performance of Sandy Bridge could have been easily extrapolated from the evolution of Penryn, Nehalem and Westmere.
The performance of Bulldozer was determined by design decisions taken by AMD at least 3 to 4 years before its launch. Therefore, during the last 6 months, when they have lied the most, they knew perfectly well that they were lying and it should have been obvious to them that this is futile, because the lies will be exposed by independent benchmarks immediately after launch.
For most operations, a so-called Bulldozer "module" (with 2 "cores") had exactly the same execution resources as a Sandy Bridge core, while for a few operations, like integer multiplication, a Bulldozer "module" had even less execution resources than a Sandy Bridge core.
The common FPU of 2 Bulldozer "cores" was more or less equivalent with the FPU of a single Sandy Bridge core.
The Bulldozer integer "cores" were stripped down in comparison with the cores of the previous AMD CPUs, e.g. a new "core" had 2/3 of the addition throughput and 1/2 of the multiplication throughput of an old core.
So 2 Bulldozer integer "cores" were together barely faster than one old AMD core, while a single Sandy Bridge core was faster than them, by having an equal addition throughput, but a double multiplication throughput.
Bulldozer could have been a decent CPU, if only AMD, instead of describing it as a 4-"module"/8-"core" CPU, would have described it as a 4-core/8-thread CPU, which matched Sandy Bridge, except that in Sandy Bridge the 2 threads of a core shared dynamically most execution resources, while in Bulldozer only a part of the execution resources were shared dynamically, e.g. the FPU, while the rest of the execution resources were allocated statically to the 2 threads of a core, which is less efficient.
Such a description would have set correctly the expectations of the users, and they would not have felt cheated.
I am pretty certain that the huge disappointment that has accompanied the Bulldozer launch has hurt much more the AMD sales than they might have gained from the buyers lured by the false advertising about the 8-core monster AMD CPUs, which should easily beat the puny 4-core Intel CPUs.
(author here) The FPU is not quite equivalent to a Sandy Bridge FPU, but the FPU is one of the strongest parts of the Bulldozer core. Also, iirc multiply throughput is the same on Bulldozer and K10 at 1 per cycle. K10 uses two pipes to handle high precision multiply instructions that write to two registers, possibly because each pipe only has one result bus and writing two regs requires using both pipes's write ports. But that doesn't mean two multiplies can complete in a single cycle.
With regard to expectations, I don't think AMD ever said that per-thread performance would be a match for Sandy Bridge. ST performance imo was Bulldozer's biggest problem. Calling it 8 cores or 4 cores does not change that. You could make a CPU with say, eight Jaguar cores, and market it as an eight core CPU. It would get crushed by 4c/8t Zen despite the core count difference and no sharing of core resources between threads (on Jaguar).
All AMD CPUs since the first Opteron in 2003 until before Bulldozer had a 64-bit integer multiplication throughput of 1 per 2 clock cycles.
Initially the Intel CPUs had a much lower throughput, but they improved in each generation, until they matched AMD in Nehalem.
In Sandy Bridge, Intel doubled the 64-bit integer multiplication throughput to 1 at each clock cycle.
On the other hand, AMD reduced in Bulldozer the 64-bit integer multiplication throughput to 1 per 4 clock cycles.
The FPU of Bulldozer had the additional advantage of implementing FMA, but the total throughput in FP multiplications + additions of the 4 Bulldozer FPUs was equal to the total throughput of the 4 Sandy Bridge FPUs.
While you are right that calling Bulldozer a 4-core CPU does not change the user expectations about ST performance, it totally changes the user expectations about MT performance.
In 2011, the people were not as shocked about the low ST performance (though they were surprised that it was lower than in the AMD Barcelona derivatives), because that was a given ever since Intel had introduced Core 2, as they were shocked about the low MT performance, seeing that an "8-core" CPU is trounced by a 4-core CPU.
After being exposed to the AMD propaganda, it was expected that Bulldozer was unlikely to match Intel in ST performance, but it should have a consistent advantage in MT performance, due to being "8-core".
Yeah you're right about the multiplication performance. I checked back and 64-bit integer multiplication is one per four clocks.
I disagree that core count should be taken to mean anything about MT performance. You always have to consider the strength of each core too. Nor does twice as many cores for the same architecture imply 2x performance, because there are always shared things like cache and memory bandwidth. And even if those aren't limiting factors, MT boost clocks are often lower than ST ones.
Huh, so the benchmarks that show that a FX-8xxx is about on par to i3 for ST, but even better than a i5 for MT are misleading ??
I actually have no complaints about MT performance (even though learning that it wasn't a "real" 8-core was disappointing), I can even run VR because it takes full advantage of MT, even though ST is often struggling for other tasks...
The benchmarks that you have in mind had probably been run on some later Piledriver/Steamroller/Excavator models, which corrected some of the initial problems, like the too low instruction decoding throughput, and which raised the clock frequency, due to an improved CMOS SOS process.
I also had an AMD Richland APU of 4.4 GHz, which was reasonably faster for most tasks than an Intel Haswell U i5, but the speed ratio was much, much less than the power consumption ratio of 100 W for AMD vs. 15 W for Intel.
The original Bulldozer fared much worse against Sandy Bridge.
Hmm, but AFAIK the performance didn't radically improve in P/S/E - and anyway, I had assumed that this whole discussion also covered them because B/P/S/E are still all using the same architecture - for instance : doesn't TFA apply to P/S/E ?
> So 2 Bulldozer integer "cores" were together barely faster than one old AMD core
This sounds like a wild claim : I went from a better than midrange 3-core Phenom to a worse than midrange ~~8~~ 4 core Bulldozer, and my singlethreaded performance not only did not nearly halve, but has even improved !
EDIT : By Bulldozer, I mean Excavator (I assume that performance wasn't radically different, especially when compared to the Intel equivalents released at the same time, but I might be wrong ?)
Gaming and enthusiast machines are only a fraction of AMD's market, most consumers and clients didn't care about the features AMD's marketing department lied about.
AMD did not lie about some particular feature of Bulldozer.
They lied by claiming that Bulldozer should be faster than Sandy Bridge, while knowing that it is completely impossible for their claims to be true.
Even without running any benchmark, it was trivial to predict that at similar clock frequencies the "8-core" Bulldozer must be slower than the 4-core Sandy Bridge.
For multi-threaded performance, the complete Bulldozer had between 50% and 100% of the number of arithmetic units of Sandy Bridge, so in the best case it could match but not exceed Sandy Bridge.
For single-threaded integer performance, one Bulldozer "core" had between 25% and 50% of the number of arithmetic units of Sandy Bridge, so in the best case it could be only half as fast as Sandy Bridge.
The only chance for Bulldozer to beat Sandy Bridge as in the AMD claims would have been a very high clock frequency, in the 5 to 7 GHz range.
However, AMD never made the false claim that Bulldozer will beat Sandy Bridge by having a much higher clock frequency. They claimed that they will beat Intel by having more "cores", which implied more arithmetic units, while knowing very well that they had decided to remove a large part of the arithmetic units from their cores, at the same time when Intel was adding arithmetic units to their cores, instead of removing them.
I had one running as an ESX server for a long time. Back then, this was the cheapest path to 8 cores and was ideal for carving up into smaller VMs. The 8 core/32M specs were what was the most you could put on a personal 'free' box.
adjective - "marked by a concerted effort and effected in the shortest possible time especially to meet emergency conditions" - Merriam Webster dictionary.
Crash here means something like "speedy" or "rushed". It refers to AMD's attempt to modernize their architecture in a hurry, and doesn't have anything to do with how recovers from or deals with crashes. I was also initially confused.
{kind=link}
{kind=link}
1. Our business logic and UI each basically operated in single threads.
2. Our intermediate audio and video processing buffers were floating point or moving in that direction in the future.
3. Wherever possible in filtering and effects, we avoided branching, relying on zero-folding in vector instructions.
I went on to explain where they'd be in trouble for game engines, document processing, and other key use-cases.
Their hardware architects slowly sank in demeanor over the course of that all-day meeting. I later heard from contacts at AMD that it was an "oh shit" moment for them. That said, having been at Sony at the time, we'd gone down the long dark road of the Cell...
Sometimes people try bold and interesting things that don't work. Bulldozer was definitely one of those, and it should have been killed (or at least diverted), like Larrabee. Nonetheless, AMD survived, and their current architectures owe some of their thinking to the hard-learned lessons of Bulldozer.