Oh wow, a 23-page write up about how the author misunderstood AWS Lambda's execution model [1].
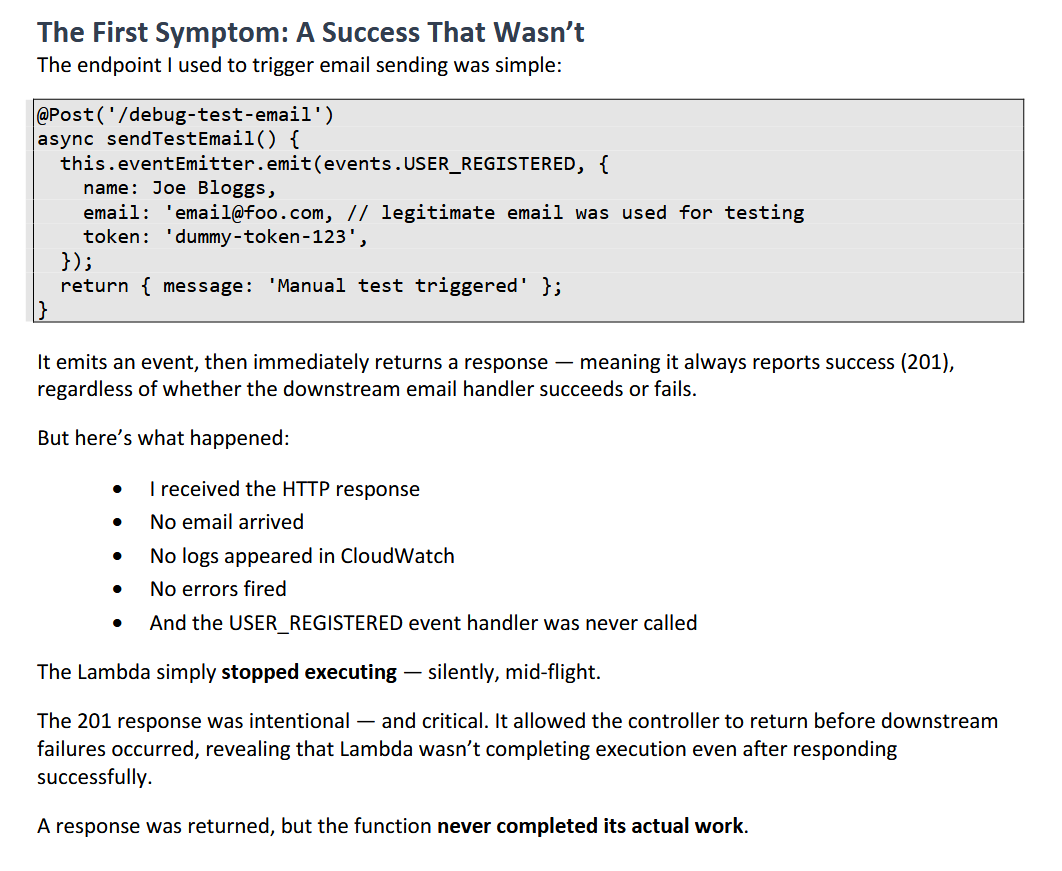
> It emits an event, then immediately returns a response — meaning it always reports success (201), regardless of whether the downstream email handler succeeds or fails.
It should be understood that after Lambda returns a response the MicroVM is suspending, interrupting your background HTTP request. There is zero guarantee that the request would succeed.
It took me a couple reads of the PDF but I think you're right. The author creates an HTTP request Promise, and then immediately returns a response thereby shutting down the Lambda. They have logging which shows the background HTTP request was in the early stages of being sent to the server but the server never receives anything. They also have an error handler that is supposed to catch errors during the HTTP request but it isn't executed either. The reason for both seems quite obvious: it's completely expected that a Lambda being shutdown wouldn't finish making the request and it certainly wouldn't stick around to execute error handling code after the request was cancelled.
As an aside I find it strange that the author spent all this time writing this document but would not provide the actual code that demonstrates the issue. They say they wrote "minimal plain NodeJS functions" to reproduce it. What would be the reason to not show proof of concept code? Instead they only show code written by an AWS engineer, with multiple caveats that their code is different in subtle ways.
The author intends for this to be some big exposé of AWS Support dropping the ball but I think it's the opposite. They entertained him through many phone calls and many emails, and after all that work they still offered him a $4000 account credit. For comparison, it's implied that the Lambda usage they were billed for is less than $700 as that figure also includes their monthly AWS Support cost. In other words they offered him a credit for over 5x the financial cost to him for a misunderstanding that was his fault. On the other hand, he sounds like a nightmare customer. He used AWS's offer of a credit as an admission of fault ("If the platform functioned correctly, then why offer credits?") then got angry when AWS reasonably took back the offer.
I don’t know about node but a fun abuse of this is background tasks can still sometimes run on a busy lambda as the same process will unsuspend and resuspend the same process. So you can abuse this sometimes for non essential background tasks and to keep things like caches in process. You just cant rely on this since the runtime instead might just cycle out the suspended lambda.
Absolutely, I do this at $dayjob to update feature flags and refresh config. Your code just needs to understand that such execution is not guaranteed to happened, and in-flight requests may get interrupted and should be retried.
TiTiler does exactly that. Geospatial rasters are stored in S3, and the lambda retains a cache in memory of loaded data from S3. So if the same lambda execution is used it can return cached data without hitting S3.
Uhhmm… it seems both you and @frenchtoast8 are misrepresenting the code flow. The author doesn’t return early, the handler is async and explicitly awaits an https.request() Promise. The return only happens after the request
resolves or fails. Lambda is terminating mid-await, not post-return.
That’s the whole point and it’s not the behavior your comments describe.
Page 5: "It emits an event, then immediately returns a response — meaning it always reports success (201), regardless of whether the downstream email handler succeeds or fails."
This is not the right way to accomplish this. If you want a Lambda function to trigger background processing, you invoke another lambda function before returning. Using Node.js events for background processing doesn't work, since the Lambda runtime shuts down the event loop as quickly as possible.
> Looking at (this section)[https://will-o.co/gf4St6hrhY.png], it seems like you're trying to queue up an asyncronous task and then return a response. But when a Lambda handler returns a response, that's the end of execution. You can't return an HTTP response and then do more work after that in the same execution; it's just not a capability of the platform. This is documented behavior: "Your function runs until the handler returns a response, exits, or times out". After you return the object with the message, execution will immediately stop even if other tasks had been queued up.
They did (in a typical non-fault admitting way). They didn't escalate to Lambda engineering team, then said that this is a code issue, and that they should move to EC2 or Fargate, which is the polite way of saying "you can't do that on lambda. its your issue. no refunds. try fargate."
OP seems to be fixated on wanting MicroVM logs from AWS to help them correlate their "crash", but there likely no logs support can share with them. The microVM is suspended in a way you can't really replicate or test locally. "Just don't assume you can do background processing". Also to be clear, AWS used to allow the microVM to run for a bit after the response is completed to make sure anything small like that has been done.
It's an nondeterministic part of the platform. You usually don't run into it until some library start misbehaving for one reason or another. To be clear, it does break applications and it's a common support topic. The main support response is to "move to EC2 or fargate" if it doesn't work for you. Trying to debug and diagnose the lambda code with the customer is out of support scope.
I know for a fact that’s not true. You must have misunderstood the issue.
This is one of the main technical differences between Azure Functions and Google Cloud Run vs Lambda. Azure and GCP offer serverless as a billing model rather than an execution model precisely to avoid this issue. (Among many other benefits*)
Both in Azure and GCP you listen and handle SIGTERM (on Linux at least, Azure has a Windows offering and you use a different Windows thing there that I’m forgetting) and you can control and handle shutdown. There is no “suspend”. “Suspending nodejs” is not a thing. This is a super AWS Lambda specific behavior that is not replicable outside AWS (not easily at least)
The main thing I do is review cloud issues mid size companies run into. Most of them were startups that transitioned into a mid size company and now need to get off the “Spend Spend Spend” mindset and rain in cloud costs and services. The first thing we almost always have to untangle is their Lambdas/SF and it’s always the worst thing to ever untangle or split apart because you will forever find your code behavior differently outside of AWS. Maybe if you have the most excellent engineers working with the most excellent processes and most excellent code. But in reality all Lambda code takes complete dependency on the fact that lambda will kill your process after a timeout. Lambda will run only 1 request through your process at any given time. Lambda will “suspend” and “resume” your process. 99% of lambdas I helped move out of AWS have had a year+ trail of bugs where those services couldn’t run for any length of time before corrupting their state. They rely on the process restarting every few request to clear up a ton of security-impacting cross contamination.
* I might be biased, but I much much prefer GCR or AZF to Lambda in terms of running a service. Lambda shines if you resell it. Reselling GCR or AZF as a feature in your application is not straight forward. Reselling a lambda in your application is very very easy
It may just be such a basic tenant of the platform that no one thought to. You stop getting billed after lambda returns a response so why would you expect computation to continue? This guy expected free lunch.
I don't see that on the main AWS Lambda pages. It just says that you pay for what you use. It would make sense that the time billed would be until there is no more code to execute.
Fair enough, I guess this just seems like a bold assumption to make since an explicit handler function is a cornerstone of lambda, rather than being able to run module level code and having the end self detected.
So many times I've caught myself thinking "I don't want to understand this shit, I just wanna fix it," as I've grudgingly opened up whatever docs I've avoided reading; almost as many times as I've wondered "what fucking moron wrote this code" before immediately `git blame`ing myself.
Based on the way the document is written, it seems very likely that several people did realize exactly what the misunderstanding was and try to explain it to them.
I remember interviewing a guy who worked at Amazon - he commented that he started trusting AWS much less after getting to know some of the developers who worked on AWS.
Yep that. We are a fairly high spend customer which gives us direct access to engineering managers there. Some of the non-core products are run by what looks like two guys in a trailer protected by a layer of NDAs and finger crossing. Had some pretty crazy problems even with their core stuff over the years which absolutely knocked my confidence.
At the same time, I've had two separate Apple SREs in the last 5 years tell me that I should never trust their cloud services.
If you can't see it and can't control it yourself, then you accept these things silently.
My distrust for this goes as far as the only thing actually being subcontracted out for me is Fastmail, DNS and domains and the mail is backed up hourly.
No AWS employee knows “AWS well”. AWS has a huge surface area. If you work on one of the service teams - ie the team that maintains the different AWS services - you are very much unlikely to know the entire AWS surface area and be focused on your team and surrounding services.
It use to be the case if you were interviewing for an SDE position, you were specifically told not to mention specific AWS services in the system design rounds and speak of generic technologies.
There is a "post-invocation phase" for tidying up. It's not long, and it's enough for things like Datadog's metrics plugin to send off some numbers. Yet it will fail, if you have too many metrics. It's fuzzy.
If I'm reading this correctly, then AWS Support dropped the ball here but this isn't a bug in lambda. This is the documented behavior of the lambda runtime.
The document is long, and the examples seem contrived, so anyone is free to correct me but as I understand it the lambda didn't crash, after you returned 201, your lambda instance was put to sleep. You aren't guaranteed that any code will remain running after your lambda "ends". I am not sure why AWS Support was unable to communicate this OP.
If you are using Lambda with a function URL, you aren't guaranteed that anything after you return your http response remains running. I believe Lambda has some callbacks/signals you can listen to, to ensure your function properly cleans up before the Lambda is frozen, but if you want the lambda to return as fast as possible it seems you are better off having your service publish to an SQS queue instead.
This document is bizarre. The author is so confidently verbose about something they are clearly misunderstanding, and have been told as much dozens of times. It’s humbling, in a way, to think of times I’ve felt this strongly about something and to consider the possibility I could have been this wrong.
It's never a slam-dunk with AI-generated content, but some of the signs I notice are:
- Constant bulleted lists with snappy, non-punctuated items.
- Single word sentences to emphasize a point ("It was disciplined. Technical. Forensic.")
- The phrasing. e.g. the part about submitting to Reddit: "This response was disproportionate to the activity involved: a first-time technical post, written with precision, submitted to the relevant forum, and not yet visible to any other user." Who on earth says "written with precision" about their own writing?
To be clear, I don't think it's a fabricated account. I also don't think it was a one-shot. OP probably iterated on it with GPT for quite some time.
This has GPT written all over it: "That’s not just a runtime bug. That’s a reliability risk baked into the ecosystem."
For whatever reason, it constantly uses rhetorical reclassification like “That’s not just X. That’s Y.” when it's trying to make a point.
In GPT's own words:
```
### Why GPT uses it so often:
- It sounds insightful and persuasive with minimal complexity.
- It gives an impression of depth by moving from the obvious to the interpretive.
- It matches common patterns in blog posts, opinion writing, and analyst reports.
```
I think that last point is probably the most important.
This guy is obviously the most senior person in a small startup.
To me personally, calling yourself a CTO with a CV entry that amounts to what an L5 in a FAANG does in a half, is a bit ridiculous. What title would HN recommend for such a position, instead?
The whole site is sketchy. A PhD and a JD. All these high level positions at well-known places. A website with very vague claims about heroically saving things. Almost no google presence other than this site. And 4 LinkedIn connections. Maybe I'm just cynical, but it's pegging my BS meter.
Nope, BS meter is correct. You can find the 2017 commencement documents for New York Law School online and David Lyon is not on the list of JD graduates...
> I am not sure why AWS Support was unable to communicate this OP.
Maybe we should be asking why the OP was not able to hear what AWS was telling them. I think there is a fairly troublesome cognitive bias that gets flipped on when people are telling you that you're wrong — especially when all your personal branding and identity seems to be about you being right.
Yep. I've ran into this using Bugsnag for reporting on unhandled exceptions in Python-based lambda functions. The exception handler would get called, but because the library is async by default the HTTP request wouldn't make it out before the runtime was torn down.
I sympathize with OP because debugging this was painful, but I'm sorry to say this is sort of just a "you're holding it wrong" situation.
> If I'm reading this correctly, then AWS Support dropped the ball here but this isn't a bug in lambda. This is the documented behavior of the lambda runtime.
AWS Support is generally ineffective unless you're stuck on something very simple at a higher level of the platform (e.g. misunderstanding an SDK API).
Even with their higher tier support - where you can summon a subject matter expert via Chime almost instantly - they're often clueless, and will confidently pass you misleading or incorrect information just to get you off the line. I've successfully used them as a very expensive rubber ducky, but that's about it.
This level of arrogance is just crazy. Think of the hundreds of better-qualified, but worse-at-bullshitting people who would have been better in every single position this guy has ever worked in. Embarrassing for this guy and the company to throw money at his own ignorance.
If you want to really ruin your morning, read the resume linked elsewhere. The amount of nonsense is insane. These people deserve to be called out. I can’t fathom the level of arrogance it takes to continually prompt an LLM to write this, presumably constantly coaxing it along with “make it sound more dramatic and accusatory and presumptuous”.
`This wasn’t a request for clarification. It was a reset — a request for artefacts that have already been delivered, multiple times, across prior case updates, call notes, and debug summaries. The very same package AWS previously reviewed. The same logs they had already quoted. The same failure they had already confirmed.`
While the author is probably correct in this being a platform level bug (I have not ran the code to confirm myself though), they should stop being so angry at a corporation doing what corporations do which is run a big bureaucracy and require extraordinary amounts of extra communication. One of job requirements of a principle engineer, often making hundreds of thousands if not millions of dollars a year, is to communicate across levels because it is so hard to do this effectively without being angry or losing your cool.
`As a solo engineer, I outpaced AWS’s own diagnostics, rebuilt our deployment stack from scratch, eliminated every confounding factor, and forced AWS to inadvertently reproduce a failure they still refused to acknowledge.`,
I do not think that a solo engineer would have the economic clout to get AWS to pay attention to the bug you found. Finding a bug in a system does not imply any ability to fix a bug in a bureaucracy.
Plus, given the tone of the article, I have a funny feeling that the author may have rubbed people in AWS the wrong way, preventing more progress from being made on their bug.
But, a wise fellow once said, "all progress in this world depends upon the unreasonable man".
It's not a platform level bug. It's as-designed, as-documented behavior. Return a response and Lambda suspends.
They seem to want a fast response with background processing of a potentially slow task. The answer on Lambda (and honestly, elsewhere) is having this function send the payload to a queue, and processing the queue with another function.
Yes you’re right. I wrote the parent comment and then someone else also mentioned the lambda is returning before background processing. I missed that one!
What a tremendous waste of resources. As a startup engineer and leader your job is to build value for customers and investors as quickly and effectively as possible, knowing the privilege of their participation with you is fleeting. The time spent in those meetings or writing this vitriolic pdf would have gone a long way towards shipping features, even if you had to survive with a suboptimal approach for a while. Time isn’t cheap and this cost a fortune.
This is a simple misunderstanding of the Lambda execution lifecycle, but it's maybe not a great look for AWS support, that no one there was able to explain the problem to this guy.
I guess it's possible someone did explain it to him, and David hasn't mentioned that in his diatribe.
I actually witnessed almost exactly the same thing happen in my org recently. AWS support was far _too_ nice and actually did escalate to the service team (or claimed to).
There was a few days of back and forth which should have been resolved by saying "please read the how lambda works" section of the documentation.
It's been several years at this point, but I used to be a cloud support engineer for AWS (i.e. the first line of defense against support tickets). We were trained to always be kind to the customer, even if we're frustrated with them, so a response like "please read how the lambda works" probably would've gotten me reprimanded. Customers can rate your response from one to five stars, and if I remember correctly, anything less than four required a written explanation to your manager as to what went wrong.
That job was a glorified call center; I didn't last very long.
> I guess it's possible someone did explain it to him, and David hasn't mentioned that in his diatribe.
Not just possible. Quite likely. It seems very clear the answer was "yes, that's how it works on Lambda, and it is not going to change" and this person said "but I want it to work the other way on Lambda".
The title should have been: AWS Lambda Works as Expected – An Application Architectural Bug [pdf]
If the designer expects a reliable system that guarantees processing of the request after the return of the status, they cannot rely on a server to not crash the moment the response was sent to the wire. Serverless enforces this well, yet people try to force their view of infinitely reliable infrastructure, which is not based in reality.
It is possible to talk even to a runtime engineer, but you need to be on their enterprise plan and spend millions per year with AWS. It may sound brutal, but AWS prioritizes based on the account size.
Given the AWS Active mention, the author may be living off free AWS credits and has a modest spend afterwards.
Not sure if a seven-week investigation is the best use of engineering resources at early startups. Once you hit the limits of PaaS platforms, going EC2/Fargate/Kubernetes seems like a more pragmatic option. AWS Lambda is not for async jobs; once you return HTTP, it's done. Not convinced this is a bug.
However, he did manage to get to the front page of Hacker News, and the write-up is quite decent (minus the AWS blame part).
Whilst this is a combination of user error and shitty support (not unexpected) I’ve seen Amazon directly not understand how their own lambda stuff works before. There is a pretty horrible bug in one of their higher level products that used lambda because they didn’t know that an execution environment can be reused between invocations. Their software assumed entirely incorrectly that it was stateless resulting in us having to, as the first line in the lambda, clean up the previous invocation’s data on the filesystem. After 3 years they haven’t fixed this as far as I am aware. Getting the actual engineers who wrote this on a call was unproductive as well suggesting it would take months to sort out. We built our own in the end.
Given that many commentors on here and reddit have already explained his mistakes, yet he has entries in his CV documenting this "bug report" and "publication" of the incident, I don't really see any evidence whatsoever that AWS didn't explain to him his mistaken understanding of how Lambda works or that they provided shitty support.
I'm not convinced AWS support didn't tell him exactly what the problem was and he ignored it. There's no reason to believe he's a reliable narrator here.
I would suggest taking this down and hope it silently goes away. If you're a fractional CTO for a startup that spent a week on this, then spent god knows how long to rearchitect for Azure based on this... The startup might find this actionable.
Some devil's advocate- AWS receives many support requests that initially go to customer support engineers (in call center environments) who act as first defense for pointless simple issues. But you still have ones escalated to actual engineers and technical teams, costing hundreds or thousands of dollars. There are times when its like actual service issues and bugs etc but the number of times you have a long thread between a support engineer who does not even understand what the customer is misunderstanding (because of arrogance like this, and the customers continuing assertion they are not wrong) can go on for days/weeks and is just monumental waste of time when the answer is read the docs.
This post is a good lesson on humility, and why emotionally-heated blog posts might not be a great idea, no matter how satisfying, and you should possibly stick to dry technicalities instead. If OP had just written up their experience without all the sneering and potshots at Amazon support, people would've just gently corrected them. But as it is they look like a tremendous asshole, and certainly not fit for a CTO role, either temperamentally or skill-wise.
The poor guy has obviously wound himself in knots over this for several months. He went through all this, obviously really bothered by the impersonal Corporation, "solved" his problem by moving to Azure, but then wrote up this massive rant.
Sounds like he needs a holiday at the least.
The mere idea that reddit has a special Amazon protection team that is the cause of his account suspension is ludicrous.
I didn’t bother to read this incredibly long write up past the introduction. But other commenters are asserting that the author expected their Lambda function to continue executing an async task after returning an HTTP response, despite numerous attempts by AWS staff to explain why that wouldn’t work. If true, that is _hilarious_. Easily one of the best stories of misguided anger/hubris/Dunning-Kruger I’ve ever heard. That’s like expecting a local function to continue executing after a `return` statement. It’s such a simple, basic principle of the platform they were trying to use.
But one thing bothers me…wouldn’t the author have encountered the exact same behavior in Azure? I guess I really will have to read this paper to find out.
Azure functions don't operate in the same way, they are more like AppRunner's architecture. They then layer on the Lambda billing model.
It was typical Azure strategy of rushing out a product to show they have all the same features as AWS. It may have improved since I last touched it in 2018.
Taking a step back, this is an interesting reality of choosing platforms. Lambda ain't Node.js. Yes, it runs JavaScript, but that doesn't make it Node.js. JavaScript-land is full of frameworks and platforms that let you do less work in exchange for using a particular set of patterns or architecture.
This also shows the best and worst of AWS: things are documented, but not always when/where/how you need them. You will still need to learn a few things the hard way when getting your toes wet (so use those "innovation tokens" sparingly).
I work at lambda, and my team would be the one to engage with OP, it most likely would have been me actually to investigate this.
The fact that support didn’t engage us seems odd as we have gotten engaged for far more silly stuff.
However, in this case you should have awaited for the response from event emitter.
The lambda execution model clearly does not allow you to run things past the response as execution is frozen by the sandbox / virtualization software. From there, you’ve most likely caused a timeout when issuing the request.
AWS has a clear policy of not providing support for user application code. I’ve never worked at a company that had enterprise level support with a dedicated TAM. It might be different there.
However if it is worth anything I did work at AWS for 3.5 years (AWS ProServe). I knew almost immediately what the issue was as soon as I read the article and knew it was documented and expected behavior.
Having worked with Lambda since it was announced over 10 years ago, it was also clear to me. However, I can also understand if one was new to it and read zero documentation about its execution model, they might be confused. I'd expect someone with experience to ask "am I really the first person to encounter this 'obvious bug'?" though.
Please correct me if I'm wrong but lambda model is when server responds then there shouldn't be a background task or any compute after that point otherwise how would lambda know when to stop or there wouldn't be a difference between lambda and VM.
Then watch…AWS will fix it and not tell you at all. Similarly, I found that Azure Functions were saving secrets in plaintext in the SCM blade even though the Function App itself was using Key Vault References!
I throughly documented the issue, reproduced it with fresh infra, filed a bug bounty, etc. Only to have Microsoft say “It’s the intended behavior” and “That’s not applicable for a bug bounty”, etc. Next month I checked the SCM area again…yeah, plaintext secrets were miraculously redacted. That’s the last time I hunt bugs for you MS!
While I have no empathy or patience for Amazon’s support model, you’re really asking for it when you write backend code in Node.
I get that some big businesses are using JavaScript on the backend, but I’ll bet almost every single one would be better off switching to a type-safe, compiled language.
{kind=link}
> It emits an event, then immediately returns a response — meaning it always reports success (201), regardless of whether the downstream email handler succeeds or fails.
It should be understood that after Lambda returns a response the MicroVM is suspending, interrupting your background HTTP request. There is zero guarantee that the request would succeed.
1: https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtime-...
reply