Can anyone recommend a good "Consultant's", "Solutions Architect's", or "Top-Right Quadrant on a Silly Gardner Chart" overview of how Kubernetes competes or cooperates with Mesos? It feels like there's quite a bit of dense conceptual reading you have to plow through before you can even start to talk about what these things do.
- Mesos is a generalized, low level framework for distributing workloads over multiple nodes. It provides mechanism not policy. Therefore it requires quite a bit of up-front work to build something usable for any given application.
- Kubernetes is an opinionated cluster execution tool. It provides tools and a curated workflow for running distributed containerized applications. It's generally pretty quick and easy to get running.
- Mesos has a rich, resource-aware task scheduler. You can specify that your application requires X CPU units and Y RAM units and it will find the optimum node to run the task on.
- By contrast, the Kubernetes scheduler currently is rather dumb[1]. There's no way to specify the expected resource utilization for pods, and the scheduler simply tries to spread out replicas as much as possible throughout the available nodes.
People are (rightly) excited about things like Mesosphere which could allow the best of both worlds: the ease and API of Kubernetes with a powerful Mesos resource scheduler, not to mention nice-to-haves like a Web UI with pretty visualizations.
You can now cut me a check for 50% of the consulting revenue you get from this information. :)
1. The scheduler is intentionally simple and pluggable, to allow improvements easily in the future. My statements only apply to the current state of Kubernetes as deployed today.
The Kubernetes scheduler also does resource-aware scheduling. You're correct that it tries to spread replicas across nodes, but it only spreads them across the nodes that have enough free resources for the container (more precisely, Pod) that it's scheduling.
Currently resource requirements are specified only on containers, not Pods. The requirements for the Pod are computed by adding up the requirements of the containers within the Pod.
To be more concrete: Within the PodSpec type that you linked to, there is a field of type []Container. Within the Container type there is a field called Resources which is of type ResourceRequirements. ResourceRequirements lets you specify resource requirements of the container. The resource requirements of the Pod are computed by adding up the resource requirements of the containers that run within the Pod.
In addition to resource-based scheduling, we also support "label selectors" which allows you to label nodes with key/value pairs and then say that a Pod should only run on nodes with particular labels. That's specified in the NodeSelector field of the PodSpec (which you linked to).
The Kubernetes scheduler looks at "fit" and "resource availability" to determine the node a pod will run on. Nodes can also have labels like "high-mem" or "ssd", so you can request a particular type of server (via the the nodeSelector field). More details are in the link above.
The page you linked to describes a slightly different feature, namely the ability to restrict and override the resource requirements of Pods at the time they are submitted to the system. So it's part of the admission control system, not part of the scheduling.
Thanks davidooo - I was specifically referring to the section on "limits at the point of creation" which gives a practical example of using limits in a multi-namespace (multi-tenant) environment. (https://github.com/GoogleCloudPlatform/kubernetes/blob/maste...).
The new documentation you linked to has good explanations in it as well.
Mesosphere is a company, not a piece of software. I think you're referring to Mesosphere's dcos[1].
DCOS is some really nice packaging for marathon, chronos, etc, with a nice cli tool for downloading and installing new frameworks onto mesos. Personally, I find using Aurora a lot nicer.
That being said, I do think the kubernetes-mesos gives you far and above the best of both worlds. You get the developer story of kubernetes, with the ops story of mesos.
From an ops perspective, k8s is a bit clunky. I was actually shocked when I found out after bringing a new kubelet (worker node) online, you have to also update a service on the master. This was in a power training class on Kubernetes at this year's Redhat Summit in Boston. Really underwhelmed with the complexity of k8s compared to mesos, but they aren't an apples to apples comparison.
Can't speak for the cloud. When running on bare metal, in high availability mode, you need to edit the controller manager config, /etc/kubernetes/controller-manager, and update a line called KUBELET_ADDRESSES. If you don't, they won't be in the output of:
What you forgot is that it's not only easy to get started, you could also start REALLY REALLY small which doesn't work with ALL the other solutions. Kubernetes Master could run on a node with 512mb memory and it still works great. Your cluster doesn't die if the master dies it won't reschedule etc but thats ok mostly. the only thing what you need is enough etcd nodes to keep it up and running.
Docker Swarm seems to be the only one that supports one-off interactive containers that bind a TTY, like a Rails console (i.e. does the cluster support `docker run -it --rm busybox sh`). But its scheduling strategies[1] aren't as sophisticated as the others.
Marathon doesn't support linked containers[2], so if you're using Mesos and need linked containers, you probably will want to run Kubernetes on it and use pods.
Networking on AWS works fine with no additional networking as well.
Overlay networking is not required if you're running within a bunch of nodes that can see each other. Only if you get more complex will you require something, and there are quite a few solutions (Flannel, Weave, Calico, etc)
But most of them suck, and they suck even more when you configured them badly (badly in terms of you used an option which comes by default). However with the bigger vxlan adoption most performance issues are fixed, still, could have some improvmenents. I also think that IPv6 could fix a lot of these things...
As others have mentioned there are multiple options. If you want micro-segmentation (one network per app-tier) with fine-grain access control you can use the OpenContrail plugin https://github.com/Juniper/contrail-kubernetes. It has the added advantage that you have a tenant network span k8s, openstack, vlans, or anything else you can plug into a reasonable mid-tier router.
[Disclosure: i'm currently working on this project]
I think you just need to provide a flat networking infrastructure where all nodes get their own IP and can reach each other. So you can swap flannel for project calico or your own setup if you like.
Weave and Openvswitch are two other options. Many IaaS (gcp, aws) provide the required nobs and dials to configure this "natively" using their API so no extra SDN required if you are already running on a compatible cloud provider.
Kubernetes can run on Mesos as a Mesos service. Thereby giving you a more opinionated layout for your compute cluster, while running other peer Mesos services, such as Hadoop, Chronos And Marathon.
I'm afraid answers like this actually make the confusion problem worse (nothing against your comment, just an observation in general.)
If you're confused about the differences between similar-sounding products X and Y, the fact that "X runs on Y" or "Y supports X" has never made the situation any better, it only makes the line between X and Y even more blurred.
I think this is especially true of Mesos, because people have a tendency to attribute qualities to Mesos that are actually qualities of a particular Mesos framework like Marathon or Aurora. As it is, Mesos is more of an SDK than anything, giving you the tools to write an orchestration system. It comes with built-in ways to communicate with nodes over a message bus, the ability to look at your nodes as resources, etc... but all of the scheduling logic is up to the frameworks themselves.
I think Mesos has a perception problem because of this. They want to build up hype about what mesos is and can do, so they claim things like Mesos being able to schedule docker images and keep them running, etc... but that's really the job of something like Marathon that runs as a Mesos framework. But if they didn't claim such things, Mesos wouldn't seem very compelling.
To me, the biggest benefit of Mesos is what the gain would be if every datacenter scheduler was a Mesos framework (yarn/spark/kubernetes/marathon/fleet/swarm/aurora, etc), and Mesos was only used to maintain multitenancy on the same hardware. That's where the real advantages come from... if you want to try Kubernetes you shouldn't have to dedicate hardware to it, you should just install it on your existing mesos cluster that is already running the rest of your stuff. In this respect, mesos is only useful insofar as all the big cluster managers use it as their underlying substrate.
"X runs on Y" at least implies Y is "lower level" than X.
As I understand it, Mesos is analogous to an operating system kernel for your cluster, while Kubernetes is a CaaS (containers-as-a-service) layer on top.
>>> Mesos is more of an SDK than anything, giving you the tools to write an orchestration system
This is why Mesosphere built their DCOS; it recognizes that Mesos is a sharp-edged distributed systems kernel and needs to be packaged with convenience layers like Marathon and Chronos and "userland" tools (CLI, graphical UI, packaging system, etc) that make it a complete OS.
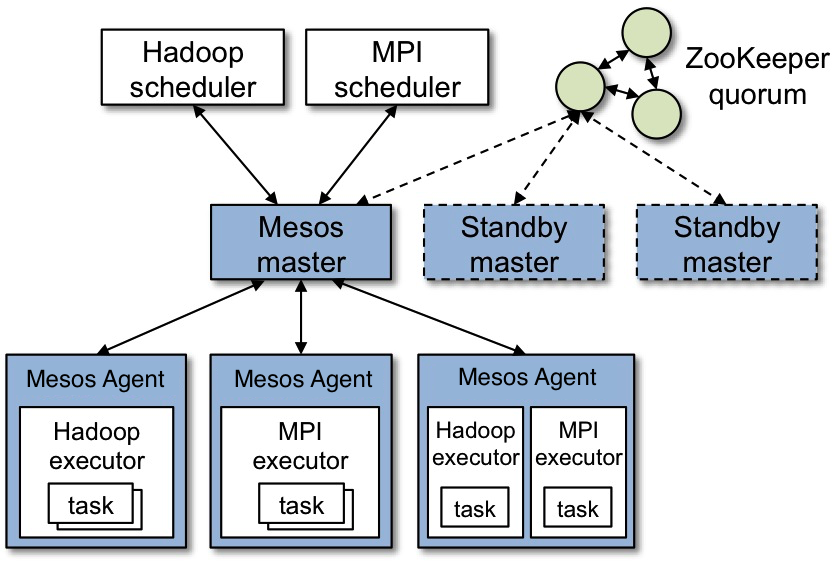
At their most basic level, Kubernetes [1] and Mesos [2] both use a client/server type architecture, where you install a client on many compute nodes, then the server part farms out jobs (in the form of containers) to these client compute nodes. Mesos does not do scheduling, and is pretty low-level in terms of interfaces, so you would typically run some type of software which talks to it via API, like Marathon [3], Aurora [4], or Hadoop [5]. Then Marathon/Aurora/Hadoop/etc tells Mesos to farm out compute jobs to these end client nodes (aka schedules). Complexity can quickly go up depending on your hosting environment, scale, and HA requirements. There is actually a really good high-level overview diagram of what a mesos/hadoop/zookeeper setup looks like here [6].
The stack looks something like this for Kubernetes/Mesos (top down):
- Kubernetes and Mesos (client/server packages depending on node type)
- Docker (container engine)
- OS (Ubuntu/RHEL/etc)
What are some use-cases?
- you have more work than can fit into one server
- need to distribute load across N+ nodes
- Google heavily uses containers (not k8s, but that inspired these patterns)
- Gmail/Search/etc all run in containers [7]
- Apple, Twitter, and Airbnb are running Mesos today [8, 9]
But, to answer your question, the main difference between Kubernetes and Mesos, is that Kubernetes offers an opinionated workflow, built-in scheduler, and patterns for how containers are deployed into this cluster of compute notes. The pattern is baked in from the start via Pods, Labels, Services, and Replication Controllers. It also helps to know that Kubernetes comes from Google, where they have been running containers in-house, so much of this workflow (pods, services, replication controllers, etc), comes from their internal use-cases. That's the 10,000 foot view.
One small correction: Mesos is a scheduler. It doesn't natively ship with any end-user framework to access the scheduling though (you are supposed to write your own framework which uses the Mesos API). Marathon is a generic end-user framework for accessing those functions and runs on top of Mesos.
I think it's also interesting to note that Mesos can be used as the Kubernetes minion scheduler backend. And for very large collections of compute nodes, this is reputedly a good choice (though I don't have any personal experience to back that assessment up).
In the parlance of Mesos, the Mesos kernel is an "allocator" (in that it assembles and allocates all of the compute resources) and the frameworks are the "schedulers" in that they request and consume "resource offers" (made by the allocator) and then schedule tasks to be run on those accepted resources.
Actually that isn't entirely true. mesos-execute will run any shell command and it shows up as a framework in the framework api/ui tab on the mesos master.
I know being the edgy you-don't-have-big-data guy is all the rage right now, but seriously? Most people can fit all of their work on one server? What kind of mom-and-pop shops are you working for?
I started JohnCompanies in summer/fall 2001, which was the first VPS provider. This was a fairly significant financial gamble that most people can fit all their work on even less than one server.
I've found that Kubernetes is a big hammer. If your problem can be backed by a web app, you should start with AppEngine. If you need specialty library support or wider computational space per instance, you can move your AppEngine app to ManagedVMs (which uses Kubernetes under the covers). If you need special, "grid-like" services where you need exquisite control over the entire stack, only then does it make sense to use raw Kubernetes and Docker. And you will spend a lot of time getting it right.
ManagedVMs don't use k8s under the covers afaik. However there's GKE (Google Container Engine), which goes on top of (at least 3) MVMs and that one does use k8s.
While it is true that going with a PaaS(-like) solution like AppEngine or Heroku is easy in the beginning it can get pretty expensive pretty fast and it limits you in the choice of languages, frameworks, and data stores you can use. This can in some instances bring technical debt with it that will pose a hurdle when growing.
Actually, using Docker combined with an orchestration layer like k8s is supposed to give the the ease-of-use of PaaS with the flexibility of IaaS (or MVMs), however, managing sth like k8s by yourself is not that easy and you will need quite a bunch of other tools on top, i.e. for monitoring and stuff, which paves the way for Container-as-a-Service solutions, like RancherOS, tutum, or Giant Swarm (disclaimer, I'm part of the latter company)
I've found Heroku to be about 10x the cost of AppEngine for the same kinds of apps and users. I don't even want to imagine what it would cost to create my own ec2 sprawl to do what AppEngine can do out of the box. As far as languages go, I've gone to production with AppEngine apps written in Python and Clojure. I've diddled with Go. Unless what you want is something like Node.js, which has its own limitations, I don't see this as a big problem. As far as Datastore is concerned, you can substitute the implementation of it using technologies like AppScale: Cassandra, Hypertable, etc. But I've never seen another structured storage solution in a fabric form that works as well as Datastore for 90% of my problems AT SCALE. YMMV.
EB is more like Heroku than it is like AppEngine. As far as I'm concerned, the thing that makes AppEngine amazing is Datastore and how easy it is to do monstrous, sophisticated Map/Reduce over your data. I haven't even started using Spanner/Dataflow yet. It's an amazing platform (that is not without its rough edges, mind you).
Since you're already here, any chance you can talk a little bit more about upcoming plans for managed vms? I hear there is a lot of investment in that area, but what will that mean technically going forward? How are things going to change so we can plan better?
I don't want to hijack the Kubernetes launch thread, but feel free to send me an email at dlorenc@google.com and I'll answer whatever I can. We have a lot of exciting stuff going out soon.
I've worked on what is ostensibly a Heroku competitor (Cloud Foundry).
I don't see where the limits on languages, frameworks or data stores comes in.
Languages are extensible in buildpacks, data stores are ordinary services. Heroku pioneered the 12-factor app model, Cloud Foundry lets people run it themselves.
The "limitation" comes from the notion that you code to a particular implementation with Heroku (or Cloud Foundry). If you want to change implementations, you must code to that new implementation. With a true aPaaS, the implementation can change, but your code goes against the same fabric-like API.
I definitely don't want this to come off as a sales pitch, but you can get started in one click using Google Container Engine (and $300 in free credit) as well.
Except: "Sorry, you aren't eligible for a free trial at this time. The free trial is for new customers only."
Apparently, the fact that I've been curious enough to experiment with other Google developer products in the past means I'm not part of the target audience.
Yeah, sorry if that came off as snarky; I appreciate the suggestion.
I guess I can understand the cost-cutting mentality that drives Google, AWS, etc. to limit these kinds of offers to "new customers" only. Just remember to consider what kind of incentives you're creating. By effectively punishing developers for being early adopters/experimenters, you're making them wary of signing up early for whatever new and interesting stuff you announce in the future.
It's an interesting problem - the issue is that our trials are both money & time based ($300 for 60 days). So technically you've "used" your trial even if you do nothing for 2 months.
We do appreciate the feedback and are looking hard at the right next way to solve this. If it wasn't for bitcoin miners and/or bot nets, this would all be a lot easier :(
Ah, interesting -- I thought it was for a year. Then I don't feel like I'm missing out quite so much, because I would have a hard time spending that much credit in 2 months anyway :)
Got a fairly quick response from Google Cloud Billing Support:
"Unfortunately, the system is developed by design to only apply the free trial credit to new email address creating a new billing account and we can't apply it for already existing emails." Bummer.
I actually find this a common issue with a presumed sales pipeline I encounter.
They think:
1. He finds us.
2. He's interested and signs up for a trial
3. We hopefully convert before the trial is over
What actually tends to happen
1. I find something that looks interesting
2. I sign up
3. Real work intervenes
4. Several months later I have some time to look again but my trial has expired.
To be fair most companies respond to a quick email but they could be proactive and do the following:
1. If no activity is detected after the first day pause the trial
2. Some time later send an email saying "We've paused your trial. Please choose either: 1. to reactivate it, 2. be reminded in another x weeks or 3. never hear from us again.
We were looking at this, but noticed that you have to one run cluster per availability zone. Any plans for being able to run a cluster across an entire region within GCE?
FWIW, I'd love to have Kubernetes clusters spanning a region with multiple regions/providers managed by Ubernetes. That would be the sweet spot for our particular usage case.
This is only one point of data for you, of course.
"Today, each Kubernetes cluster is a relatively self-contained unit, which typically runs in a single "on-premise" data centre or single availability zone of a cloud provider (Google's GCE, Amazon's AWS, etc)."
Agreed. That's the only reason we're not on Kubernetes right now. It really dramatically increases the amount of infrastructure we need to run when we're forced to run three Kubernetes clusters to run a single MongoDB replica set. But I love everything else Kubernetes is doing and so I'm very anxious to see that be addressed.
I might come across as ignorant but what is the relationship between Kubernetes and Docker, because when I was reading the article I tought of it as a Docker competitor, but further down in the comments, there is one that says they do different jobs.
Docker and Kubernetes works hand in hand. That is to say, if you choose Docker as your container format, Kubernetes runs Docker on every node to run your container. Kubernetes focuses on _what_ Docker should run, and how to move those container workloads around.
Docker also has Docker Swarm, which can be thought of as a competitor in some ways. But Google will be a heavy supporter of their container format for a long time to come.
So Kubernetes compliments Docker, but how it complements it.
I had tested Docker just for fun, thinking that maybe I could implement it in the way I work, and sure it is a super tool for developing (far better than Virtual Machines), but deploying was kind of nightmerish, for what I understood Docker wasn't at the time ready for being a deployment tool.
Does Kubernetes fixes or extends Docker in this way
Think of them as different layers. If you're a front end web dev, it's sort of like SASS vs CSS: the former is a layer on top of the latter that makes it more powerful/convenient/easier to use.
At the bottom of the stack (most low level) is the Docker runtime. It knows how to run containers on the local machine. It can link them together, manage volumes, etc but at the core it is a single machine system. (That's probably why Docker, Inc has developed their proprietary orchestration tools like swarm).
Layered on top of that are container-native OSes like CoreOS. CoreOS provides facilities for running distributed containers on multiple physical nodes. It handles things like replication and restarting failed containers (actually fleet "units"). This is a huge improvement over vanilla Docker, but it's still pretty low level. If you want to run a real production application with dependencies it can be tedious. For example, linking together containers that run on different nodes. How does container A find container B (which may be running on any one of N nodes)? To solve this you have to do things like the Ambassador Pattern[1]. Any complex application deployment involves essentially building discovery and dependency management from scratch.
Layered on top of this is Kubernetes (it runs on CoreOS but also Ubuntu and others). As said elsewhere in this post, k8s provides an opinionated workflow that allows you to build distributed application deployments without the pain of implementing things like low-level discovery. You describe your application in terms of containers, ports, and services and k8s takes care of spawning them, managing replica count (restarting/migrating if necessary) and discovery (via DNS or environment variables).
One of the very convenient things about k8s (unlike vanilla Docker) is that all containers within a pod can find each other via localhost, so you don't have to maintain tedious webs of container links. In general it takes the world of containerization from "Cool technology, but good luck migrating production over" to "I think we could do this!".
Kubernetes is a scheduler for Docker containers. So lets say you want the following:
1 x MySQL Master
2 x MySQL Slave
5 x PHP Server
1 x Monitoring Script
Each of those would be a docker container. Kubernetes would figure out which host to place them on and verify that they are running, rebooting them on another host if one of your hosts goes down.
Docker as an organization, is a competitor to Google and Kubernetes, but Docker as a tool is complemented by Kubernetes.
This is because Docker is building it's own scheduling/orchestration tools, which is what Kubernetes is for. However, as a container runtime, Kubernetes works great with Docker.
If anyone is interested, I just wrapped up a similar post for deploying containers to Giant Swarm from Wercker, no Docker required: I just got done doing a continuos integration post for containers using Wercker and Giant Swarm: https://github.com/giantswarm/swarm-wercker.
It's the cadence of the etcd read cycle chosen for kubernetes. They could do it much faster, but I guess there are engineering tradeoffs based on the size of the cluster and the speed of the network.
{kind=link}