Sometimes I feel like it's a minority position, but I think it strange all the efforts people go to in order to essentially make the git DAG look like a (lie of a) straight-line CVS or SVN commit list. Seeing how the sausage was actually made (no rebases, no squashes, sometimes not even fast-forwards) isn't pretty, but it is meaningful and will tell you a great deal about a project and its developers... I trust that. It's real and visceral and how software is actually made and you can learn from that or find things to explore in that jungle. Projects with multiple developers that yet have straight line commit histories and super tidy commits are aberrations and full of little lies...
Kudos to GitHub for providing this feature that a lot of people have asked for. I obviously don't plan to use it, but I appreciate that it's an option for those people that like their small, harmless lies. ;)
I actually disagree. Large teams that still have linear commit histories doesn't mean it is a lie. It means that the code review process is more important that the code writing process.
For example: I check out a repository, and create a local feature branch. I create a commit containing the tests for the new feature, then one for the first draft of the new feature, then two or three for bugfixes. Each commit is small, and self-contained, but importantly isn't standalone. If someone checked out the repository in the middle of my chain of commits, they wouldn't have a working product. Then I upload my change for code review. There's no point in reviewing each of my ~5 commits individually: they only make sense to the reviewer as a combined unit. And there's no point in landing them individually: they only make sense for the overall project history as a combined unit.
In a project with many developers (e.g. 1,000 like the Chromium project), every developer has different local practices. Some keep their work based on HEAD of master via rebase, others via merges. Some do test-driven development, some don't. Making the code review the atomic unit of work, rather than the messy string of local commits, helps the project enforce common etiquette, commit formatting, and readable history.
caveat: I was responsible for code review for 2000+ developers.
We only allowed squash commits on master because of what you're describing. That is the level where history "made sense". However, for code review, we wanted to support both styles, because there is an advantage sometimes to seeing the sausage being made. For instance someone will refactor something -- maybe change a method name. Then they apply that refactoring at all the call sites. Very conscientious developers would break this into two commits. We didn't want the first commit on master, but it made sense to review this way, because it was easier on the reviewers: change, effect of change on everything else.
I call this "telling a story" with your commits. There's a lot of value in that style if you have the time to do it.
The other style of commit-by-commit reviewing, where I see all of the work in progress commits, I don't find valuable at all and I _definitely_ don't want to see on master.
While this is "telling a story", the first commit will break your code for no good reason (i.e. if you rename a method, but not its usages, hell breaks loose). This make you lose one very useful features of git: the ability to binary search for the place where a bug was introduced - git bisect.
But so does squashing, which is one of a handful of reasons I hate most uses of squashing.
Only squash when it removes bug that only ever existed on your machine. Everything else should be recorded in the history. Forensics are important to the long term health of your project and you impoverish yourselves by scrubbing the crime scene.
> Everything else should be recorded in the history. Forensics are important to the long term health of your project and you impoverish yourselves by scrubbing the crime scene.
OK. So would you support an IDE that generated one individual commit per keypress? When I type "hello", that's five individual commits each changing a single letter.
That is the true history of what happened, and it's typically recorded in your IDE's undo log in memory, such that you can step back and forward through it. Are you OK with pushing this commit history to your project? That's the true history of what happened, after all, and it could be forensically useful.
When we commit code to share it with other people, we recognize that only a certain level of detail is relevant to them. The physical sequence of letters that I pressed isn't typically relevant to someone else. Rather, the logical set of changes is what affects them.
If you agree that a single commit per letter of keypress is undesirable then you agree with me in principle. There is a finite level of detail that makes sense to share, practically, with current source control systems, and what we're arguing about is how much to share.
I feel like this is important to point out because people frequently make this argument about the "true history" of source, and all that, while neglecting the fact that the commits they choose to ship are already an arbitrary simplification of the "true history".
So would you support an IDE that generated one individual commit per keypress?
That would actually be awesome, if the tools supported it. Imagine how easy it would be to find bugs with a bisect if it can drill down to the actual keystroke that introduced a bug.
Realistically, you'd want to back out a few notches though. Say, every time the dev hit Shift+Ctrl+B (or tabbed over to the browser or whatever signifies "build the project" in the environment in question), so that you get an indication that the current state of things was meant to at least compile and run.
But yeah, that's the value of source control. Being able to dig back in history to the exact spot where a bug was born. I can't understand all why so many people here would want to scrub that away.
I am told that Google's filesystem for their dev workspace is somewhat similar to capturing every single keypress as an immutable layer forever.
Apparently introducing interesting problems when people create a log file one byte at a time, up to several hundred megs. (just 100000000 files for one little project, oops)
> OK. So would you support an IDE that generated one individual commit per keypress? When I type "hello", that's five individual commits each changing a single letter.
Not OP but - conceptually? Yes. I've written file formats which preserve undo/redo history, for example. The caveats:
1) I don't want to inadvertently leak my password. This is an issue with things such as local bash command history buffers as well, and unreviewed autocommits in general. You could say it's too useful - to the wrong people!
2) My tooling needs to be built around a different level of granularity as the default. I'm not OK with single letter commits cluttering up my git log, for example. Having them around to drill down into if I need them? Sure.
Per-letter detail is so granular that even undo/redo systems will often squash history states together. Observing your exact typing Cadence / the extra evidence of initial authorship is niche enough that I'm quite willing to sacrifice that level of detail for the sake of performance, maintainability, or basically any and every other excuse you can think of.
> When we commit code to share it with other people, we recognize that only a certain level of detail is relevant to them. The physical sequence of letters that I pressed isn't typically relevant to someone else. Rather, the logical set of changes is what affects them.
I have never seen a codebase with perfect commits. The ones that always give me trouble wrapping my head around are the squashed "logical set of changes", where the set size is way too damn big. Reverse engineering a saner overview from a series of tiny commits is way easier.
And the physical way something was done does matter at times. I'm going to pay way more attention to "whitespace cleanup" commit done by a human than "whitespace cleanup" commit done by vetted tools, for example. In whitespace significant languages, the former may trigger a full code review. Similar concerns with a lot of refactorings, actually.
> If you agree that a single commit per letter of keypress is undesirable then you agree with me in principle.
Per the above, I can only agree with you in practice :)
> There is a finite level of detail that makes sense to share, practically, with current source control systems, and what we're arguing about is how much to share.
Agreed. But I haven't found a single, solitary codebase, where I'd ever argue "less". I can't even recall a single, solitary commit where I'd have ever argued "less". Commit directly to mainline to fix a single character typo? I'll be annoyed if your changelist description was too terse! I want to see:
I've seen a codebase where a majority (read literally: >50%) of the commits were "good enough". It was beautiful.
A coworker of mine shared he'd collected stats on who made the most commits/day to test a hypothesis. Due to some outliers, he'd decided against it, but thought I'd find the stats amusing. Out of ~50 people (~15 programmers), I (the most recently hired programmer) topped the chart. Second place? The build server account (thanks to nightly build scripts.) I was indeed amused.
(Don't look at the OpenOffice.org years, they literally took a whole bunch if development work from SVN branches and then merged them in as a single commit and put in single line descriptions with internal tracking numbers and odd project management codes... utter disaster! And of course the branches are now all lost...)
How about I just look at the latest ~33h directly on that page ;)
I like the scope of a lot of those commits, although a few are still chunkier looking than I'd like - take that with a grain of salt, though, as I don't have a good enough feel for the codebase to reasonably estimate how much more they could be chunked up. Pretty much everything has a review link, which is nice. I'd expect more back and forth in the comments, but perhaps that's handled out-of-band.
I have lots of nitpicks with the actual changelist descriptions where I'd want things to improve. "Clean up" could mean just about anything - I must go to diff (and expand the context) to understand e.g. https://cgit.freedesktop.org/libreoffice/core/commit/?id=945... properly. I'd be inclined to instead write:
officeipcthread: Cleanup RequestHandler::Enable: Early bail, remove aDummy (just use aUserInstallPath directly), move declarations.
Now I know scope, and the types of changes (refactoring worth reviewing if looking for breakage, not just ignorable whitespace / comment changes.)
I'd lean towards linking a screenshot of at least the new version of UI when the file being modified "isn't human readable" (read: is modified with something other than a text editor, even if I can totally read it) which would apply to e.g. https://cgit.freedesktop.org/libreoffice/core/commit/?id=72c... .
Ah... sberg's one commit message that could be more descriptive :-) That NSS commit has two very experienced reviewers, but fair point! wrt screenshot linking, I guess a link to the LibreOffice bugzilla would be nice.
Thanks for the info, that's really quite insightful. Appreciate you taking the time to give it!
> My tooling needs to be built around a different level of granularity as the default. I'm not OK with single letter commits cluttering up my git log, for example. Having them around to drill down into if I need them? Sure.
And that would be nice to have, a vcs that allows you to fold and unfold commits to different levels of granularity.
Wanna have only a straight line history with all feature branches squashed? There you have it. Just need some of them like that? Sure enough. What if you want every time the file was saved? Not a problem, just configure it to commit automatically.
> Only squash when it removes bug that only ever existed on your machine. Everything else should be recorded in the history.
You can squash into master without losing the history of the code review with git. This gives you the best of both worlds, a more accurate history than the one you propose, and a master that isn't broken.
I've often wondered if it would be possible to design a source control system that could track this lineage. Kind of like, "inside" of a commit would be a hidden history that you could unpack if you wanted to. "This single commit is actually the squash of these other commits made by this guy". "This commit is actually the rebase onto mainline of this commit a guy made when his machine was behind". The commit would look like normal to the current source control CLI, by default, but would reveal this hidden level of detail if you inquired "How was this commit made?" - then you'd get the reflog.
I've wondered if support for a feature like this could finally resolve the "debate" between merging and rebase. The people who like having the full history (whatever that means) would have it, and the people who care about logical changes would see it by default. The cost would be that the repo history would indeed have the full level of detail, but you could imagine supporting a cleanup operation that erases this "origin" information for commits that are sufficiently old, or else simply doesn't pull the info by default and fetches it only when necessary.
(You can kind of simulate this using merge commits, by only looking at one parent, but it doesn't really work out well in practice.)
FWIW, the OpenOffice.org guys had this insane workflow where they squashed all commits into one commit and then out a summary of all the changes into the commit message. Then they scrubbed the private branches.
That methodology is an extreme example of where squashing does NOT make sense.
Have you used Phabriactor? This sounds an awful lot like a Diff in its terms. "master" is a linear sequence of Diffs being landed, with Diff number in the commit message. You can paste that diff number in the web UI and see the individual commits that were part of it.
> You can squash into master without losing the history
This is otherwise known as a merge. A single atomic change to master, referencing only the final files, with the first parent referencing the previous master that was also "not" broken.
It has only one change: A second parent, referencing the more accurate history.
If we start without M, and start with master=R2, temporary-feature-branch=R5, I expect the following outcomes:
"squash" will leave us with master=M, and the graph R1 -> R2 -> M. Once temporary-feature-branch is deleted, R3-R5 are forever lost.
"merge" will leave us with master=M, and the graph R1 -> R2 -> M, + R2 -> R3 -> R4 -> R5 -> M
"rebase" will leave us with master=R5, and the graph R1 -> R2 -> R3 -> R4 -> R5. Once temporary-feature-branch is deleted,
The first case loses the history of the code, and thus can't be what we're talking about.
If you call the second case "squash" I find that very confusing. It's also not what github is referring to when talking about "squash your commits" in the parent article, they're talking about the first case. Now, git confuses the issue a bit too - perhaps I should be labeling the second case a "non-fast-forward merge", but I'd still find that clearer than "squash without losing the history."
That's why you can "skip" a commit during git-bisect[0].
I had to find when a bug was introduced, and guess what? it was inside a single massive commit touching hundreds of files. I prefer atomic commits with good messages, thanks.
You can upload multiple different versions of a single code review, and reviewers can diff both against the base and against previous versions of the review. This is helpful for showing "stories", responses to comments, and for "my original commit got reverted, so here I've reuploaded it, and then also uploaded the fix, so you can clearly see what's different this time".
> The other style of commit-by-commit reviewing, where I see all of the work in progress commits, I don't find valuable at all and I _definitely_ don't want to see on master.
This is the style I use for code reviews.
There's not a lot of tooling to support it, at least with GitLab, but git-playback [1] is kind of interesting.
I try to shoot for meaningful individual commits, squashing to get the intent of each change (more or less) self contained. I've found it really helpful if I ever need to `git bisect` to find what introduced a bug, I get a small(ish) commit that only affects a single module. Very helpful when debugging code I wrote last year.
In that sense it would be cool if git supported something more like "branch collapsing," which could be used instead of squashing a branch and rebasing that on master. It should be possible to "view" a branch as if it were a single commit on master, with its own comments etc (from the merge commit perhaps) and then expand it. Perhaps this is just a UI problem..
I do think this is mostly a UI problem. As someone else suggested in this thread sites like GitHub which show only a linear list of commits should probably default to something more like `git log --first-parent`.
There also sounds like a need for `git bisect` to be smarter about DAG traversal, in that it seems to treat the branch as if it were a flattened linear list rather than taking advantage of the merge structure of a branch. This also sounds like something that should be relatively easy to make smarter.
How did you - on that 2k+ developers project - deal with the fact that sometimes someone is working on a change in a feature branch (a) that the an other developer also needs for her feature branch (b)?
Would you move the commits that need to be shared away from the features onto a seperate branch (c) and then .. ?
I am really curious how you handled these sort of situations at that scale!
> It means that the code review process is more important that the code writing process.
If that were true, the optimal solution is PRs with individual commits that all pass testing. I find it much easier to review a series of small changes for logical correctness than mashing them together into a single PR. Github recently added this as a feature, so I'm not in a completely invisible minority there.
And then, when the review is over, having discreet commits makes git bisecting down to the commit that broke the system more granular.
Absolutely. If someone formulates their PR such that every commit in the chain is small, easily reviewable, and passes all tests, that's fantastic! That makes reviewing code, searching history, and bisecting all easier.
Unfortunately, that's not the 90% case that I see. Most of the time a multi-commit PR contains N-1 commits of incremental development and one final one that fixes all the tests and typos and removes debugging print statements. Neither the project nor the author benefit from having those intermediate commits integrated verbatim.
If people generate N-1 commits with a final one to clean things up, maybe people should learn about git stash and making some WIP branches, then squashing commits themselves or better yet, keeping their own history clean, instead of submitting PRs full of crap.
I know, it might be too much to ask of people... oh well.
Just because you smash away at code for hours doesn't mean that's how your commit history should look. You can revise history in ways that are beneficial instead of destructive.
Yeah, and that's why you squash all the intermediate commits first. If all your commits on master are useful and meaningful individually, bisect works great.
> Neither the project nor the author benefit from having those intermediate commits integrated verbatim.
Sure they benefit. You can see the thought process that went into the commit. If there's something that seems weird or out of place you can see how it evolved into existence. That can be exceptionally useful.
>If that were true, the optimal solution is PRs with individual commits that all pass testing. I find it much easier to review a series of small changes for logical correctness than mashing them together into a single PR.
This is too myopic and explains how you can end up with good code, but bad architecture. A good review ensures both.
I like my PRs to be about high level goals, and I want them made of lots of commits I can review. The commits themselves can be the result of re-basing (which is fine within feature branches) and maybe not truly chronological.
I agree with what you're saying, good code review and good code writing aren't mutually exclusive. However, the truth of the matter is that code review is a far more clearly defined moment in a workflow than writing good code (which is more of a habit than an actual action). As such, it is far more efficient for a team to accept reality and squash after PRs (which is now first possible), instead of relying and keep correcting all your coworkers when they don't properly squash commits before pushing.
«Making the code review the atomic unit of work, rather than the messy string of local commits, helps the project enforce common etiquette, commit formatting, and readable history.»
I agree that code reviews should be important, and key to understanding the history of a project at a more useful timescale. I just disagree that they should be "atomic" and that a reviewer (even, or especially, a later code archeologist) may not have reason to inspect or dive into smaller units within code reviews.
Where I think that we may agree is that I feel that even if they shouldn't necessarily be "atomic", I agree that code reviews should probably be first-class objects when talking about and dealing with source control. In git, you can use --no-ff merges today as a useful approximation of code review boundaries (especially with PRs and GitHub's default --no-ff and including linking PR #s). It might be nice to see code reviews or other aggregates of commits/commit graphs be truly first-class citizens of git in some manner.
I agree with you, and I prefer the --no-ff merge option for submitting reviews, but I think the argument for it would be a lot stronger if 'git bisect' supported a --first-parent flag the same way that 'git log' does.
Yep, the key to understanding git (why there's mutable history, etc.) is to understand that because of its history (designed by Linus) it's not designed to make day-to-day developers's lives easier, but to serve foss project maintainers and release engineers.
People who review code for inclusion in a project, want to track meta-progress on issues, want to pin versions for release, etc., mutable history means they can squash fixups or fix your whitespace for you, rebase changesets onto other changesets, have history that reflects the project management strategy, etc.
Also it is very likely that my feature branch isn't really complete during all the little commits I make. The commits are useful to me, but don't often indicate intent too much. The whole thing put together may be easier to diff when a few years in the future someone tries to figure out what happened there.
Regarding your example - why would you commit any of the 5 little commits, If they didn't complete the task, and also are breaking the product? wouldn't it be better to commit only when you completed the task you were working on? (I mean, if the task is made out of sub-tasks, then I would also commit each subtask or milestone that I feel is important, but this is not the case here)
Sometimes, having a snapshot is useful even if it's not a snapshot of a completely functional system. "Hmm, this doesn't seem to be a workable approach here; let's commit, checkout an earlier version and branch off that." It's not necessary to push all these experiments (or even keep them in the end), but it might be useful to have them, at least for the moment.
>Seeing how the sausage was actually made, ... it is meaningful and will tell you a great deal about a project and its developers... I trust that.
...tidy commits are aberrations and full of little lies...
...small, harmless lies.
Interesting choice of words.
Here's another way to think about squashing private commits for public consumption: programmers do not install keyloggers and upload their entire keystroke history including every Backspace and Ctrl+Z used in their text editor to the repositories. And, most of us wouldn't care about seeing it.
Whether John typed "x = 218^H^H73" or "x = 273" is a meaningless distinction and irrelevant noise. Those spurious ^H Backspaces are equivalent to the twitchy multiple commits in private branches. We really don't want to see them. Think of private noisy commits as an extended workspace of a text editor. If squashing those commits is a lie, the Backspace key without an audited keystroke log is also a lie.
Side note: The other comment downthread about keeping all private commit history for "git bisect" is a red herring. Sometimes a commit will deliberately have broken syntax -- e.g. make a quick commit before getting up to grab a soda -- it won't be CI test worthy. Besides, an automated CI server's cpu cycles can point to an upstream integration/test/qa branch instead of a programmer's private branch.
«If squashing those commits is a lie, the Backspace key without an audited keystroke log is also a lie.»
In a world with infinite storage space and a good UX on top of it, I could absolutely see a case where it might be amazing to have a source control integration with the full undo stack of my editors. VCR roll through someone's efforts Twitch style and grab a box of popcorn as you drinking game your way through their typos...
That said, I definitely will rebase/squash local WIP stuff on local-only branches on my own machine, as I see fit. Yeah, I see those as harmless lies because I really didn't build it that way, but sometimes that's what makes me feel better about publishing that work.
I appreciate you trying to push this conversation towards it's extreme, absurd ends, but I also realize that there are a lot of aesthetic judgments here and I for one lean towards keeping more of the little pieces and the interesting digressions like here's where I totally "brb grabbing a soda" the whole branch and sometimes you taking that break means easier commits for me to review when I'm reviewing your code (whether a code review in a PR immediately, or a research effort down the line) as maybe I need a review break there too. I appreciate not everyone feels the same on this topic.
>you trying to push this conversation towards it's extreme, absurd ends,
I didn't think of my example as absurd hyperbole. People actually do use "git commit" on their local unpublished branch as another form of Backspace/Ctrl+Z/Ctrl+S. And just like every text-editor Ctrl+S keystroke is not meaningful, every "git commit" is not meaningful either. A lot of commits are just the programmer's personal unhygienic work-in-progress scratchpad stuff. It's not CI or "git bisect" worthy.
>I for one lean towards keeping more of the little pieces and the interesting digressions like here's where I totally "brb grabbing a soda" the whole branch
I won't dispute that you like whatever you like (VCR-playback of every keystroke mistake) because we're all different. However, I'm pretty sure most busy programmers reviewing pull requests will not appreciate having to wade through all the commits about "cleaned up whitespace" and "savepoint before soda run."
I think it is hyperbole given the surrounding context of this article/thread is mostly speaking to squashing commits after a review has happened in a PR. I say that not as a judgment, I like hyperbole and admit my top-most comment was intentionally hyberbolic too. Hyberbole is a good conversation to have sometimes.
A commit to git is a named snapshot of a file tree. That's it. All the other "worthiness" we ascribe to a commit is communal. A person's unhygienic work-in-progress can give you insight into their thought process or their work ethic. Why did this person give me this particular named snapshot of their file tree? I expect they are tell me (or future them) something and I can respect that artifact and preserve it, just as easily as you might angrily suffer from it and destroy it.
CI or "git bisect" "worthy" are orthogonal considerations and also vary between communities and needs.
If there is something we can agree on here: yes, all commits are not created equal. Even all commits aren't worth preserving equally. That said, I think there are tooling solutions here far beyond "destroy that what you dislike".
Just to be clear, your premise of "give me" is flawed because not every "commit" was meant as a capital "C" Commit-a-Logical-Unit-of-Work. Instead, many commits in private local history are a more mundane commit-as-a-backup-checkpoint-savepoint. The "savepoints" are like "^H Backspace". Asking "why the programmer gave you those particular savepoints" is like asking "why did he gave you those ^H Backspace keystrokes". It's a nonsensical question.
The confusion is that the same "git commit" command is used for 2 very different semantic purposes:
(1) git commit -m "fixed bug #23984" --> as Logical-Unit-Work
(2) git commit -m "wip" --> as meaningless backup/savepoint like Ctrl+S save
The type (2) was for the programmer's internal purposes of safety backups, cleaning up whitespace, typos in comments, reflexive muscle memory of saving often, etc. They have no semantic meaning to "give you". Type (2) commits can have deliberate broken syntax and they're not meant to be built or be bisected.
Type (2) commits should never be discouraged because saving work often (including broken midstream work) is a good habit but from an outsiders perspective of the reviewers upstream, they are way too noisy. The spurious commits could be less than 30 seconds apart with no compile/build step in between.
Anything not stored on the system of record cannot be counted on to exist at any point in the future.
From a strategic standpoint, thinking of that data as anything other than 'destroyed' would be a grave error of judgement. From a retention standpoint the difference between 'could' and 'did' is profound.
> Anything not stored on the system of record cannot be counted on to exist at any point in the future.
That's an issue with GitHub itself, not an issue with the method of squashing commits before merging into master. See gerrit as a prime example of separating reviewing code and your master branch.
If you have an issue with people deleting branches that were intentionally preserved to save history that was then squashed onto master, that's not the fault of anyone who squashed their commits but left them preserved on a branch.
As a code reviewer looking at a pull request, why aren't you just looking at the entire diff instead of individual commits? How is squashing to a single commit and looking at that different than just viewing the entire diff for lots of little commits?
> you trying to push this conversation towards it's extreme, absurd ends
I would remind you that you are the one introducing morally charged terms like "lying" when describing rebasing. The fact that you cannot conceded even that those who disagree with you are at least morally good actors is the source of the extremism in this conversation.
I would encourage you to seek hard to understand how it could be that morally good people still conclude that rewriting project commit history is a desirable thing, rather than concluding that they're engaged in self/external deception. At the very least, your conversations about the topic will become more productive.
It's inherently deceptive. Instead of thinking through problems to produce their solutions in an ordered, clear fashion, they make a big spaghetti mess, and then hide the sausage-making in a squashed commit that throws away work that may in fact, be very useful later on, all to present the illusion that they arrived at the visible conclusion without misstep.
That's deceptive, wasteful, and has more to do with ego or shallow ideas about "cleanliness" than it does with usefully recording our work processes.
The kind of work you're thinking of is generally what you put in comments.
Someone reading the code will not be reading the commit log. If there's gotchas in the code, they should be expressed in comments, not in the commit log.
The commit log, on the other hand, should always be readable for devs, especially newcomers to the project, to get an idea of how to develop small and concise features and how to contribute. Smaller, cleaner and always-buildable commits also make for very easy git bisects.
Git isn't here to record your personal history with the code, it's here to provide developers with an understanding of how the project evolved. It's not deceptive to arrange your commits to make them clean, it's part of creating a clear, understandable, easily-reviewed unit of change.
What you're missing is that "gotchas in the code" are not always known when the code is being written.
Very often, you have to piece together what happened and why from the record of what people actually did.
There's no such thing as "personal history" with the code in the context of SCM commits. It's all project history.
This new idea is both deceptive, and honestly, shocking. No SCM system previously has ever been used to actively encourage discarding history, and decades of using these SCM systems ought to have adequately demonstrated why that history matters.
>There's no such thing as "personal history" with the code in the context of SCM commits. It's all project history.
Yes, there absolutely is "personal history" with DVCS.
Your rigid mental model for "SCM commits" is relevant for older tools like cvs/svn with lock-checkout-checkin-unlock procedures. The "commits" in those centralized SCMs are a Really Big Deal.
DVCS is different. When a programmer decides to "fork" a public repository, he copies it to "local" harddrive and it becomes a personal repository. From that fork, the programmer can also create an unpublished branch and that branch is another level of personal scratch space. The commits in this type of environment are not a big deal. With git/dvcs, it shifts the Important Action from the "commit" to the "merge/fast-forward" step. That's why many programmers rebase to optimize how that step looks.
The concept of "personal history" is built-in into the ethos of how Git and DVCS works and it's been a separate concept from "public project history" since day one. The programmer can certainly choose to share every untouched line of personal history but he doesn't have to. Same concept as not sharing a recording of memory buffers and a log of every keystroke from the text editor. Most of us don't care to see any of that.
>our collaborative processes just because changes are staged locally first.
The keystrokes of ^H Backspace are not a "collaborative process". The idiosyncratic persistence of RAM buffers of a text editor is also not a "collaborative process". Why do you think "git commit" on a local unpublished repo is collaborative? I can only guess that it's because the word "commit" is in "git commit"? Well, syntax is not semantics.
>I'm very aware of what DVCS is.
I think many people with your position know the commands syntax of DVCS but don't actually grok the "draft work" philosophy of DVCS. Therefore you assign label of "collaborative process" to unrelated concepts such as the typing habits the programmer happens to execute on his laptop's harddrive. Unfortunately, the programmer persisting his editor's RAM buffers to disk happens to use the command "git commit" which distorts the thinking and causes people to label that action as "collaborative"!
The "pull request" and "merge" is collaborative. The raw "git commit" is not.
Except it's not lying. If the unit of work is good, then watching the developer go backwards and forwards and making mistakes that stop the software from even compiling isn't even helpful - in fact, you can sometimes get multiple of these errors stack up in a row. Trying to bisect, even with bisect skip, is painful in these cases, and it doesn't even help with code reading.
The general rules of Linus Torvalds are the only real sane ones in this situation, at least IMO:
1. For a clean commit, make sure you rebase only on your private history. If the branch is public and in any way used by anyone else, then unfortunately it's not something that can be considered "private" any more (at least not unless you give strict warnings that no serious work should be done on the code in the branch until it is finalized).
2. Once your code is committed into a public branch or into the master branch, then you can't change it. No rebasing on this code!
3. Do NOT rebase other people's code, even if it is very messy. If you pull in messy code, then complain about their messy code or try to avoid depending on it. Which basically means that developers that collaborate need to practice pushing and merging clean code.
I said elsewhere that the only use of squash that I strongly agree with is to remove bugs and other dumb mistakes.
What I disagree with strenuously, to the point of anger, is having a code as where every line of blame tells me only who made a change and what feature it was for. And I know too many people who think of every feature or pull request as a single commit.
THAT is lying, and I mean that in the judgement-passing definition of the word. You're fucking up the version history intentionally, and you should be stopped.
I'm not in the habit of reading code for fun. I have a job to do, and I want to do it. If I'm looking at the version history it's pretty much only for two reasons. Maybe I know for a fact there was a clever bit of code in this file and it's gone now, so I need to find it. Was it deleted or did you split isn't off into another file? I like those but they don't happen to me very often.
More often I'm reading blame because of a wtf moment. I can't think of a logical reason why the code looks the way it does, but I need to make a change and so I need to know if the person who wrote it was trying to do accomplish something or just confused.
Commit a8bcdef by dingus Implement feature #532
That tells me what changed, who changed it, how it changed and when, but I've lost the why. I know, you probably think "feature 532 is why, duh" but it doesn't tell the story of the intermediate states and why for instance they changed 'users > 1' to 'users >= 1'.
And if there is one class of commit should absolutely and under no circumstances ever ever be squashed it's any commit where you reformatted code. If a line changes and its part of a commit for a feature I'm going to assume that method body was all you, and stop looking. If you 'wrote' it but the commit message is "pretty print" I know I have to go pull a blame on the parent version to keep digging.
Ah, yeah - I agree with that last bit about formatting changes - even if I have probably unintentionally violated that in the past.
However, if you have changed users > 1 to users >= 1 and there is some sort of intrisic logic to it, surely a. you put that reasoning into the commit message, and b. you add a comment into the code briefly explaining the significance?
I don't know about you, but I'd prefer to know about why this is significant within the code, rather than have to dig through the blame logs of a version control system!
Early versions of Microsoft Word kept the undo history in the .doc file. I remember reading about a few cases where someone wrote things like "my boss is an ass", erases it and then sends the report to the boss, boss accidentally clicks undo too much and guess what he sees.
> It's real and visceral and how software is actually made...
It's also extraordinarily cluttered, and it really gets in the way when someone later want to do a 'git bisect' to track down when a bug was introduced.
When I'm working I do frequent little commits just to capture and back up my broken stream-of-thought experiments. None of those are going to be relevant to people who work with this code in the future; how does it benefit them to impose my haphazard process on them?
Of course if there's a way to break up my final commit into more meaningful smaller commits, I do that rather than one monolithic commit.
For example if I clean up some whitespace issues, add some new comments to old code, and implement a new feature, I'll put those in three separate commits even if I originally did the entire change at once. In this case you'll see more commits in the public history than I originally had.
Or if I check in a new version of some external library, add an API call that uses it along with its tests, and add UI code that calls the API, those may be separate commits in that order.
My goal is to make the public history useful to future developers.
I'm curious about these workflows where history matters so much, because people using them must be doing very different things than I do. I use 'git blame' every now and then, 'git show' more frequently, 'git bisect' practically never. I think I would spend at least two orders of magnitude more time squashing commits than I ever have to spend dealing with the consequences of a non-squashed history.
I did a rebase once because there was a big mess I was trying to clean up in order to make a merge work. I would be surprised if anyone has ever cared about the details.
I don't think anyone does `git bisect` all that often, but... when you need to do it, you hope the history is clean. Otherwise, figuring out what went wrong and where can be a nightmare.
But squashing makes git bisect even harder, since the chunks are bigger. If you have a very granular history then you can see exactly what 15 line change caused the breakage
(though the counterpoint is that maybe there are parts of the granular history that are just busted for other reasons)
Agreed, I certainly don't advocate squashing more commits than necessary! The granular, the better. As I mentioned, I'll often tease apart separate commits out of something that I originally stuffed into a single commit: whitespace changes, add some comments, fix a bug, all separate even if they started out as one commit.
I just don't find it useful to see every commit when someone uses Git like I do, committing all sorts of intermediate broken work while experimenting. Especially not commits that are going to be broken regardless.
You make a good point about bisecting. (Although I guess if you're too overzealous with rebasing you'll arrive at the commit you're looking for and it will be huge. Balance in everything yadda yadda yadda.)
To me this still sounds like a display problem more than a data problem. The viewers could implicitly hide non-tagged commits and then you can expand them out to see the details if you should need.
What frustrates me is that there are mechanisms to deal with this problem that maintain the DAG and history (cleaned or not), but people jump to the solution of destroying the process behind the code rather than use them.
In particular, I would kill for support for basically the `git log --first-parent` option in viewing the history of a branch on tools like github and gitlab. Rather than squashing your branch, you make your merge commit have a meaningful commit message (which you do anyways for a squashed commit) so that you don't always have to be viewing the tangled web underneath.
There should be no practical difference between a squashed commit and a merge commit from the perspective of the branch that commit is on (they represent the exact same change from parent to child), but the tooling insists on giving you the most complicated possible view all the time so there is a tangible difference.
Couldn't disagree more. Having worked extensively on teams on both sides of this issue, I can experientially state that a well-done git rebase and commit strategy is much more useful and helpful.
In terms of feature branches:
The individual engineer is free to do individual commits in their branch as they need to in order to keep track of their work. Before they submit a pull request, they should rebase and squash all of their commits into a single one that thoroughly describes everything in the feature that is being committed. When used in conjunction with tools like Phabricator, Arcanist, and commit templates, the workflow is very smooth.
When another team member goes to code review their pull request, rather than having to examine multiple individual commits there is only a single one to examine and comment on.
Master history:
Rather than cluttering up the mainline history with 'Did this', 'Did that', 'Merged: Did this', 'Merged: Did that', 'Reverted: Merged: Did this' etc, you get a series of commits that articulately describe what each commit was for. In the event you need to revert a feature because it breaks something, its much easier to revert that single commit than trying to hunt through all of the individual commits from an engineers feature branch. And in that case, if you revert one of the commits from the feature branch it could break something else.
I agree that a well-done git rebase and commit strategy is much more useful. However, squashing everything will (most likely) lead to gigantic commits that are hard to reason about.
A better approach would be to create multiple small commits that work and are self contained. It's ok for commit N to depend on the preceding commit, but each N should be able to stand on its own.
If devs rebase everything before pushing and push often (therefore also rebasing often), conflicts will happen a lot less often. Devs can also use their private branches for temporarily saving all WIP, squashing/rewording only what makes before submitting the PR or pushing to master.
I'm only arguing that what you see as clutter, I see as potentially interesting history, and a mess of merges and reverts are more interesting than people give them credit. It can tell you quite a lot about a project. (Did you learn from reverting 'Merged: Did This' anything about why it shouldn't have been merged? Did you miss something in 'Merged: Did that' that didn't quite merge easily? That's easier to find/diagnose with smaller more often merges than big evil merges...)
Anyway, to each their own, and I appreciate your preferences differ from mine.
that's more of how squash was applied in the situation ... If they had huge commits then while squash might break it up a bit that's a problem with how the people did their work.
Myself I like to do PR and merges with code that can be logically comprehended quickly and doesnt break the build.
a lot of that is due to being emphatic to people that are doing the reviewing. I know they don't know the context as they aren't in the code so I'm showing them a snippet of it, say a new method in s single commit. Then another commit for another method. Finally a third one that actually does some new functionality by combining the two.
I figure that's good enough for people to see that unit tests passed on the two methods and that the system started getting errors after the last commit so to look there for faulty logic.
isn't pretty, but it is meaningful and will tell you a great deal about a project and its developers... I trust that.
Here is a (made up), but generally realistic git log
git log | grep -i WIP
mon 5pm - WIP, going to work on this from home
tue 4:45pm - WIP, going to work on this from home
wed 2:30pm - WIP, meeting
wed 5pm - WIP
thu Noon - WIP, working from the cafe on my laptop
fri 5pm - WIP, working from home
sat 3pm - WIP, heading home sick for the day
Does it really matter to anyone, and count as anything but noise to know that I committed my work in to the repository just so that I could work on it from a different computer. I can't imagine how low the signal to noise ratio would be if every person on the team did this.
It does tell me a great deal about your development habits, yes.
Maybe not information that I care to do much more than skim, of course, unless I'm your manager looking for reasons why you might be working from home too much. :) (That said, there's probably some cool deep learning applications here...)
Some of the information, for instance, is that maybe you are working on pieces too large at a time and should find more ways to break them into smaller units of work that you can more easily commit in logical piece at a time rather than "snapshot dumps" between computers.
Like I said, from a hyberbolic standpoint, how the sausage is made isn't pretty and is full of garbage sometimes, but it is informative.
I'm a manager, and I'd be happy to see commit messages about working from home. My team would never write commit messages like this, they are of negative value to the team. I would ask them to squash. If I saw these commit messages pushed, the employee would get a warning.
I can relate to that. I don't like those WIP commits on a feature branch (when the program is crippled or even doesn't compile or doesn't pass the tests, when the code is filled with temporary "printf" debug messages, etc.) to be in the history of the master branch.
Ideally, every commit that I'm making should be preferably not big, but logically complete and working. The problem is that sometimes I want to work on another branch and I have to commit in the middle of the work so I can checkout into the other branch in which case (without a squashing merge) the "offending" WIP commit would end up in the master branch's history.
I can't trust git stash anymore. I mistyped something and it blew away a lot lot lot of work. So now I just commit stuff. If I want to get rid of the commit, I can follow it up with a reset.
Not true. From the git stash man page: "If you mistakenly drop or clear stashes, they cannot be recovered through the normal safety mechanisms."
Git stash is more dangerous than other git commands, and I've personally witnessed more people losing work with stash accidents than with commit accidents. There may be plumbing commands that can get you there like fsck but the fact of the matter is you are better off committing or branching, from a safety standpoint.
That said, I've been happy to debate the larger implications that there are UI/UX tweaks/story-telling that could make even the work-in-progress non yet published stuff more appealing to publish without needed to mutate it from its as-developed states... But yes, I was mostly speaking to published commits.
I think I would go insane with commit messages like that. Sorry, but they have very little value - I'm afraid that it's not important to know that you've gone out for a meeting, a coffee or sick. Commit messages in a mainline tree should be reserved to explain what you've done, and nothing more.
I would hate to have done a bisect to land on your commit "WIP, heading home sick for the day" as the one that caused the bug. By all means, create a WIP branch and if you can then push this WIP branch to the main repo, but please use commit squashing into logical units of change when merging into the feature branch or main trunk!
Git was designed for those type of low-friction wip commits in private/local/unpublished branches. Many programmers have a concept of "savepoints". Think of "git commit" as an "implementation detail" of that savepoint. Those savepoints were intended to extend the programmer's mental scratch space and never meant for public consumption. Therefore, squash/rebase is a logical followup step to consolidate meaningless savepoints into a meaningful commit.
A private "commit" in git does not have the same semantics as the lock & checkout type of commits in svn/Perforce. Programmers should not be discouraged from making cheap commits as often as they want even with nondescriptive titles because those commits weren't meant for public dissemination anyway. Being judgmental about those wip commits makes no sense.
What annoys me is that so many people take the position that there's no other way to improve the experience except for building an hazardous and error prone system into the core workflow of a tool that should ideally deal primarily with immutable history, rather than building better tooling to manage that complexity and present history in a useful way other than a raw list of commits. I mean, who would build such tools, and isn't managing complexity hard? Oh wait, it turns out we're developers, and managing complexity is the core reason of existence of all software engineering. It's really rather silly.
But it's a lot easier to convince devs that using tools with bad UI elements is hardcore and makes them look smart instead of demanding improvements.
Yeah, I definitely agree. Especially coming from a source control system before git where mutability was extremely hard (and likely to cause, deep, terrible problems) so a lot of great work had been put into making it less likely you would even need to mutate things down the road, such as good interactive defaults to help lead you through exactly what was going into a patch....
Certainly there are a lot of people that seem prefer imperative mutability, and more power to them, but maybe we learn from all of this and build better tools too.
What do you propose? If you want to err on the side of commits that show a clear unit of change, with a clear commit message and you make a syntax error by accident, do you seriously think it's a good idea to force a dodgy "oops, syntax error" commit into the mainline code branch?
I agree that code once committed to master should be immutable, but your own private commits should be maleable. It's not a matter of feeling superior or trying to look smarter, it's just really commonsense that you should try to submit easy to understand code changes and remove as much unnecessary extraneous rubbish as possible.
I absolutely agree that private commits should be malleable and sometimes you do want to just pretend that you wrote things smartly the first time...
That said, there are certainly ways to better handle the "Oops, syntax error" style of commits than blowing them out after the fact. Some of that is better acknowledging the existing DAG structure of git and realizing that you don't need to 'depth-first search' the commit log every time you look at the commit log. Tools could default to views more like `git log --first-parent` and then let you expand out from there, for instance.
There's also the idea of better drawing lines between the code work and "story telling work" of a commit. Certainly today you could do all your work in progress in a branch and then `git merge --no-ff` it into another branch and there tell the completed story of that commit set after all the "dust has settled" on the stuff that was done in the heat of progress.
It's as much a matter of tooling support and community support (we all make mistakes so we aren't going to dunce cap anyone for making mistakes) as it is a technical problem.
I think we can see that "not all commits are equal" and maybe we want a system for "color these commits as work in progress" followed by "here's the final story for these commits, color it as presentable and ready for code review". I think it's an interesting discussion to continue to have and an opportunity to really think what we want in our source control tools and how they can better help us tell the stories of the code we are working on, for our reviewers and even maybe for our code archeologists.
They're not full of little lies. Projects insist on squash-before-merge to help developers keep their sanity.
Imagine working on a fast-changing block of code with 20 or so other people concurrently. If all 20 of those peoples have patches submitted to master for review, and all of those patches have multiple commits each, then every time one gets merged, the others will have to rebase to its changes and fix conflicts for _every single commit_ while the fast forward plays out. It's a horrible experience. It prevents desirable code from getting in as contributors drop out due to the browbeating.
Squashing commits can be the difference between tediously fixing something once vs. tediously fixing it 20 times. No one needs to know that you changed your mind about calling that struct "ConfigOpts" before it was ever introduced upstream.
«the others will have to rebase to its changes and fix conflicts for _every single commit_ while the fast forward plays out»
I'm mostly sort of advocating a "rebase none of the things" approach. Fix conflicts only when they happen in a branch (the GitHub PR system very nicely doesn't let you merge branches that conflict with your target branch and with CI information even better it won't let you merge branches that don't build). It's really not a bad experience.
Sometimes the scaffolding should be left in place to help show others how to build things; other times, it was put up and taken down so many times that the learning from the first few attempts isn't worth it.
I would probably be much happier not squashing stuff if you were able to bisect cleanly to points between branch merges. I don't think that's even theoretically possible; which means that when you're bisecting it's quite possible to pick up half-baked mid-branch points that you have to recognise for the broken rubbish they are - lots of false positives there occasionally, and makes bisect a lot less useful. On a repo with nice squashed commits, you tend to be able to narrow down to the feature very quickly - of course those commits then tend to be bigger etc., but I find that less of an issue.
Maybe bisect needs a flag like --start-with-merges to focus it's efforts on -no-ff merges?
Also, what if there was a tool on top of bisect that could better utilize GitHub PR JSON to target the search pattern? That could even save you some time in the case where you already have CI information attached to your PRs...
There was a patch submitted in 2011[1] to do roughly that, but it got diverted into a different purpose and then seems to have disappeared. It certainly seems like it must be possible to have a git-bisect that can deal with branches.
«Have you ever tried following a change in a repo that came from an unsquashed PR?»
I have a self-congratulating black belt in source code archeology. With the right tools, most of which are on GitHub, even, such as good commit range diffing, smart uses of tags and branches, and knowing how to navigate the DAG from merge commits (more reason to -no-ff) you have a lot of power in your hands.
«What's truly meaningful IMO is a git log that reads like a product change log»
I appreciate that point of view, but I don't share it. A product change log, I feel, is a bit of marketing/PR that needs some time, love, and editing; I find a git log is for catching snapshots of raw progress and more often useful in seeing what your co-developers are up to, as they are working.
Absolutely, not every team follows the same preferences, so with any style/aesthetic choices, be sure to know what the team zeitgeist is. (I'm not a monster, I play well on teams, I promise.)
As someone who has spent a lot of time tracking down the origin of source code changes -- and the reasons for them, and the implications of the change -- by reviewing commit logs, I can think of little worse, short of no commit history at all, than trying to derive anything remotely useful from a commit history that has been condensed down to a product change log.
Even commits that lack good commit messages provide valuable information in the form of insight into the author's cumulative thinking/process.
Ugh, the thought of scouring through commits with messages like "fixed", "oops", "done" is like fingernails on a chalkboard to me.
What I read is a LACK of thought process, when you can't squash and justify your changes susinctly
Do you see the commit history as a piece of living art, a representation of the community and culture that has produced it, or do you see it as a tool?
I'm an engineer, and I see the commit history as a tool. When I want to know what a block of code is for and why it was written the way it was, the commit history (if it is clean and granular) will tell me a lot about that, and will point me to authors, issues, features, and requirements where I can learn more. I don't care about the process of producing the code, I care about the end result. I get enough exposure to the process when I'm writing my own code.
I suppose I see commit history more interesting as works of art and archeology. Code history will be read more often than it will likely ever be interacted with. Like the scuffs in the marble, the fingerprints and brush strokes and little hairs in watercolor and oil painting, there can be beauty in the little flaws.
I've had it put to me that an Architect deals solely with the art of a project and a Scientist deals solely with the science and theory; it's the work of an Engineer to deal in the practical middle where art meets science (meets the real world).
Sometimes it is easy to overlook (or to want to overlook) the little bits of humanity in the machine; the various sorts of creative chaos in the vast ordered systems; the parts of the code that are art.
There's no easy answers to much of this thread, because it is art, it is aesthetics. There's no "right" answer, just "this looks good and pleasing to me and my team" and working to find that practical Engineering border space between the unwavering art of the Architect and the similarly unwavering logic and discipline of the Scientist.
There's definitely some merit in keeping the original intent of commit messages even when "committing early and often", but at the end of the day a pull request is supposed to tell some kind of story. When you `git blame` or `git log` a particular file, aren't you more interested in the higher-level changes than a single developer's own miniature storyline of how it got that way?
I'll give you another analogy...If I'm composing a song, and you're not particularly trying to learn how to write songs, what is more relevant to you, the end result or the various drafts and early versions that made it to that end result? For the majority of people who aren't interested in learning the mechanics of songwriting, the "journey" is definitely not as interesting as the destination. For nerds like you and I, that's part of the fun! So I try to keep the original intent of my commits, and preserve their messages in a bullet-pointed list format, to show the individual changes that were made in addition to a higher-level overview of the overall change to the project.
TLDR: Project-level changes are not the same as individual changes, and while both should be represented in commit messages, the project-level changes are overwhelmingly more useful in the future. Git is not about code storage, it's about code communication. It's about developers on the same team communicating with both prose and code in tandem.
If you rebase your unpublished work on top of some recent changes, that is in no way a "lie". Doing it via a merge is completely uninformative, in fact. Oh, George was working, by complete coincidence, at the same time, on something completely unrelated and that had to be merged against my change. Whoa, inform me more softly there, I can't take the raw cognitive overload!
Multi-parent commits complicate the use of git. When a commit has a single parent, we can pretend that it's a delta: a patch. (Like it fscking should be in a decent version control system based on some sort of patch theory!) When we "show -p" that commit, we get a diff, which is against its one and only parent. Multiple parents also complicate certain situations. They rear their ugly heads and create an ambiguity. For instance, consider git cherry-pick. If a given commit has just one parent, we can pretend that it's a delta and "git cherry-pick" it. If it has multiple parents, the ugly truth is revealed: a git version isn't actually a delta. If you want that change, you need to specify the parent!
The parent of a commit should be the thing that the work was actually based on: the work that the developer took and massaged to create the new baseline representing the commit. When you have multiple parents, only one of the parents actually meets this definition. The others are arbitrary nodes in the system which are just installed as the parents.
Speaking of trust, I have a really hard time taking seriously the argument that squashing or rebasing is "lying". If you'd stuck to meaningful, I'd consider it seriously. But "lying"? This may be git's biggest flame war, this is an old and tired debate, and calling it "lying" is an over-the-top ham-fisted value judgement of a technical workflow that is a personal choice with legitimate reasons to go either way.
Also, Linus endorses cleaning up your WIP commits before pushing.
I don't find "seeing how the sausage was made" simply of interest. It's often very instructive.
Often there will be counter-intuitive bits of code that make sense in "git blame" if you see the original, small, commit that they were created as part of. If they're part of a 1000+ line feature bomb, you lose that important context.
This was only recently, but for a while I tried keeping my commits to as small as possible in LibreOffice so that I didn't break the build. Unfortunately this caused major issues in backporting fixes, so I changed my practice.
Whilst my small commits were squashed, it shows that even well formed smaller commits that are part of a larger change can often be problematic.
Keeping your commit history clean is important. When I'm bisecting, I don't want to see coding errors like typos and syntax errors, they literally get in the way of the bisect. And when I'm reading through a source file, I'd like to each commit to be significant, or at least entirely relevant to a change. Minor syntax error changes, whilst they can still sneak into the master repository, should be few and far between.
Basically, it also encourages unit testing, rechecking your code, continuous integration, and a raft of other good and best practices around coding. And your colleagues will thank you.
Merge squashing is actually a pretty decent way around this - I'm going to use it as my workflow now. I'll make frequently code commits on a seperate branch, then squash down into another branch, then push this.
I'm with you. At least for most professional environments.
It's weird. Git was made for something very specific, Linux kernel development. It made a lot of decisions to support that environment. However most of us don't work in that type of environment.
If you have a private repo for your job you're in a very different environment. At my job mutating history is the opposite of what I want. I don't want people mutating history. Ever!
Part of the problem, in my opinion, is that Git encourages tiny commits. I might take it a step further and say that Git mandates tiny commits. Too tiny in my opinion. When that's forced upon you a clean mechanism is required. But I'm not sure it isn't sweeping another problem under the rug.
But I'm weird. I'm a game developer. We all use Perforce. It just works. You can't fuck it up. You can't ruin history. You can't get stuck. Artists and designers can be trained to use it from scratch in 5 minutes. It's so easy to use there aren't tens of thousands of blog posts desperately trying to explain how easy it is use.
I'm from a Git background but we use Perforce at work. I wish there were blog posts desperately explaining how simple P4 is because I can't understand how to use it for software development.
To me it seems like a big dump of files like a network mount with locking and some kind of history. But how the hell is one supposed to write software with it?
It has complicated tools for sharing incomplete work. I don't know how you do code reviews but we have a Perl script for that(!).
In other words: if you think p4 is simple and git is not, it's because of your background.
I can teach an artist or designer everything they need to know about Perforce in 5 minutes. I can spend a year helping and they still won't be comfortable with Git. Every studio needs a Git expert to help people when they have a Gitastrophe.
Perhaps your issue here is that P4 is too simple. You check a file in and it's there forever. Sync latest, change things, check in, voila! Once in P4 there is literally nothing you can do to permanently screw things up.
Binary files are locked so only one person can edit at a time. Text files can be merged. New users may need help resolving conflicts. I recommend Araxis Merge.
Code review tools always exist on top of source control. There are different tools that integrate with Git, Mercurial, SVN, Perforce, etc. What did you use at your old job that you were happy with?
I do have at least some good news for you. If your company is running a semi-recent version of the Perforce server you can use Git with it. You can work 100% in Git if that's what floats your boat. https://www.perforce.com/gitswarm
The point about artists I totally get. Git isn't designed for that. But similarly I'll argue that Perforce isn't designed for programmers, or at least a group of programmers spread far and wide (geographically and/or otherwise). I'm sure even p4 works great if you're quite close to the people you share the depot with.
From my point of view, Perforce is designed from completely the wrong standpoint. The "big dump of files" paradigm makes everything strange in software development. In particular, I find it needlessly difficult to share incomplete work that isn't ready to be merged (In Git, you just commit and push, in P4, you use something else, like the shelf for that).
In contrast with the "big dump of files" paradigm, Git is "create patches and share them". The beauty of this is that "sharing" part works without some dedicated, blessed server and changesets are easily shared over e-mail or any other medium.
I must agree with you that the Git UI is quite bad, inconsistent and not easily discoverable (ie. not something for artists). But the concepts of Git are well-defined and elegant and are thoroughly explained in the README in the first commit[0] of Git(!). To mitigate the issues with the bad UI, I've always found the Git manpages to be fairly clear and useful (but not everyone agrees).
What comes to using Git client with Perforce server, I'd use it if our monorepo workflow wasn't completely incompatible with that.
For me, software development has always been about creating and sharing patches, and that's why Git makes sense for me.
That's a fair assessment. Git and Perforce are designed for very different things. For video games, and especially non-coders, Perforce is clearly better imo. Git is made for very wide, open source projects. Private software projects fall somewhere in between. Some projects may skew one way or the other.
I'm fascinated by your use case because for my professional work I've never created or shared a patch. I just submit the new code and that's it. Possibly to some branch. More than likely straight to main. Merging heavy branches sucks. Even in Git.
But I definitely understand where you're coming from here. There's a heavy learning curve moving from SVN to Git. It's just a radically different way of thinking. You have to break your brain and reshape it. Moving from Git to non-Git is much the same.
When I worked on a Unreal Engine 3 game we often talked about doing things the Unreal way. The Unreal way sucked. It was stupid. Objectively wrong even. However it was important to do many things the Unreal way. Because if you did it your way that would only cause pain and suffering down the road. Because if you change a few bits to be your way then eventually they'll try to interact with bits that do things the Unreal way and it's bad times. So you grit your teeth and do it the Unreal way. If you use Git you gotta do it the Git way. If you use Perforce you gotta use it the Perforce way. As painful as it may be.
> I'm fascinated by your use case because for my professional work I've never created or shared a patch.
I do driver development, and often times we're debugging an issue where toggling some hardware (or software) "mode" can make an issue go away or appear. These are the patches we end up making and sharing with coworkers but never merging. We need to be able to do quick and dirty hacks but we can't be putting that kind of stuff anywhere near master branch. I'd say 4 out of 5 patches I write never get merged (and they're usually really short patches, the code itself wasn't of any measurable effort).
Moving from SVN to Git (or darcs/hg in my case) was certainly a big move. But I guess if you were coming from diff/patch/email/shell script background (like kernel before bitkeeper), it was probably very intuitive :)
You can shelve a changelist in P4. And any other user can unshelve it. I'm not sure how different that is from creating/sending patches? Especially if done from the cmdline.
This has been a fun, educational HN thread. Thanks for sharing!
I agree with you. In fact I think the reason we have to do squashes and lose fidelity is because the git model is broken.
There is not technical reason a source control tool could not offer multiple 'views' into the commit history. A high level linear view which you can zoom into to see the underlying commits and merges. Why do I have to lose the latter to see the former?
Bzr+launchpad does this nicely, I think. The underlying history of the merged-in branch is there, and you can look at it, but by default it looks like a single atomic change.
I'm not a big fan of clean history for the reasons you state. However, there is at least one big benefit of a clean history in the master branch: any commit can be checked out and assumed to have working code. This means you can use git bisect. Git bisect allows you to programmatically search through your commit history to identify when a certain behavioral change happened. If you have commits like "wip, not sure why the app wont start yet" in your master's history, you cannot leverage tooling like bisect. Let the sausage be created at the branch level, and keep master clean </0.02>.
(A) how important the commit is and (B) how many lines of code are changed.
Squash makes sense usually when you have have a branch with multiple small commits that affect the same thing. Doesn't make sense to squash 2 commits affecting large parts of the application just because your commit has to be squashed before merging.
I understand the point of view that it's useful to see what "actually" happened. But the other way to think about it is like this: at some point, when a developer in the future wants to understand how #master evolved over time, should the burden of linearizing the history rest with that developer (making sense of a complex graph), or with people who make changes to #master when they make them?
Projects that use a rich code review tool like Gerrit, such as Android, OpenStack and wikipedia keep the truth in the code review tool.. but the actual git tree is kept minimal and clean.
If you want to dig into the actual commit, and the dirty truth under the surface - use Gerrit.. you can even use git itself to pull down the truth.
I'm expecting this github feature to be the same, the pull request probably keeps the truth somehow.
I see this as a tooling problem. Why use two tools when you can use one? Why is "code review" not a first class citizen in your source control world?
I don't have all the answers of what the tooling should be, I just think this is as a good an opportunity to discuss it as any.
GitHub's long-standing --no-ff merges at least are one way of preserving the code review and it's internal changes directly into the git DAG. This mostly works except for tools like git bisect that treat the DAG as if it were a straight line, rather than making use of the fact that the system already supports complicated graphs.
Furthermore, along the questions of why use two tools to navigate the code repository: I sort of wish that things like GitHub PR comments and code annotations made their way somehow into nodes in the git DAG.
To me, the advantage of squashing is that it makes your changes atomic, like database transactions. If you need to back or forward port your functionality to another branch, it's easy. You just cherry-pick a single commit and you're done. If you don't squash, then it's not nearly as easy to automatically move features from one branch to another.
This discussion needs to happen because git is fundamentally flawed. There should be no way to change the history but at the same time you should be able to hide the immaterial commits. (Yes, bzr had this. I still mourn over the demise of bzr.)
+1 for the last paragraph. As long as more people are becoming developers. This convenient feature did save a lot of headaches. At least, it saves time to those who don't want to get deeper into Github.
Squash isn't for linear history. That's the rebase vs merge-master-downstream debate. Squash is for getting your wip commits out of history, that kind of thing.
Many of us believe there's no such thing as a throw-away "WIP" commit, and if there is, the work should be better broken up and managed by the developer so that they're committing fully considered incremental progress.
The easiest time to catch a bug is when it's hiding in a 10 line diff, especially before you commit it.
It gets progressively more difficult as the scope of the changeset grows.
> to essentially make the git DAG look like a (lie of a) straight-line CVS or SVN commit list.
Err, it doesn't make it look like the "lie of a" straight line, it makes it into a straight line. Whatever the other developers do, I move the project forward one ball of functionality at a time when their changes are useful to mainline.
When you use software, why do you run a "release" instead of whatever happens to be in the dev's directory when they leave for lunch? Don't you feel dishonest getting the version without the bugs?
> Seeing how the sausage was actually made (no rebases, no squashes, sometimes not even fast-forwards) isn't pretty, but it is meaningful
Perhaps if I was going to hire you it'd be interesting to glance at how you work with nobody looking. Do you keep your desk tidy or not?
But it's absolutely irrelevant to the final project and as such, it shouldn't be stored.
> I trust that. It's real and visceral and how software is actually made
You should read Tracy Kidder's _The Soul of a New Machine_, it's a good read about sausage.
But it's not how you should work because you have choice now.
Yes it tells the story. Does it help to understand the history of the code? Not necessary. I care most about what, when and where came from, not some fiction around that.
I appreciate you using the word "fiction", but I think you have it backwards. The cleaned up post-facto linearization and "cleanup" is writing a fiction, telling a story about the changes rather than actually being the changes. This is great and I realize that that has its uses to build good stories about what our code is.
I'd like to think, however, and I think that this is my larger point in this thread, that maybe we could build better storytelling tools that don't delete/mangle/mutate the actual history so that we can see in the same repository both the story and the raw facts.
This is a bad idea masquerading as a good idea. Before making a pull request (or doing any sort of merge), you should rebase against upstream master (or whatever you're going to push to). However, keeping distinct atomic commits that change one and only one small thing, when possible, is much preferable if bisect or blame is used. If you have broken or poorly written commits, use fixup, reword, squash, etc. in rebase -i.
Using fast-forward (and possibly only allowing fast-forward) is a good idea. Squashing entire pull requests that may change multiple things into a single commit is a very bad idea.
If someone prepares a pull request with a well-structured series of commits, making a logical series of changes, where the project builds and passes tests after each commit, then those commits shouldn't get squashed.
However, I frequently see people adding more commits on top of a pull request to fix typos, or do incremental development, where only the final result builds and passes, but not the intermediate stages, and where the changes are scattered among the commits with no logical grouping. In that case, I'd rather see them squashed and merged than merged in their existing form, and having a button to do that makes it more likely to happen.
> It's also the case that you lose the code review if you force push to a PR's branch after adding in a typo fix and squashing locally, right?
Not as far as I can tell; I've force-pushed pull request branches many times, and the code reviews seem to stick around. (Perhaps they wouldn't if the code changed more drastically, like files disappearing; I haven't tried that.)
I used to feel the same way (and still do to some degree). However I think the issue is more nuanced. I agree that rebasing beforehand is a good idea. But I can see the value in keeping commits on the master branch corresponding to specific features or bug fixes (which presumably map to PRs).
I think the argument can be made that if you don't feel comfortable performing a squashed merge of a PR, then that PR contains too much work and should be split up. However, I don't think there's an easy rule to decide in either case.
Small PRs are an issue because PRs are dependent on other users and can't be dependent on a prior PR.
Let's say we're adding an interface/typeclass/protocol and a concrete implementation. I'd say these should be two separate commits, as they're adding two different things. An interface doesn't require a provided implementation to work. But, if we were to create those as two separate pull requests, it would be more work for the project maintainers, and the initiator wouldn't be able to create the PR for the concrete implementation until the interface PR was merged - the concrete PR can't be added as a dependent PR of the interface one, or something to that effect.
Since you can "compare" almost anything on Github, small commits aren't really an issue, just view a larger-scope comparison to get an idea of the whole PR.
Another way to put this might be that commits are for individual code changes that build up to a pull request, which is a conceptual change?
This pinpoints the major problem exactly. Without dependencies between PRs there's really no sane way (with this feature enabled) to submit a series of commits while expecting those commits to remain separate.
Oh, and I object to the general sentiment in the responses to your post that seem to value drive-by/inexperienced contributors over the "experts". Yes, we definitely should make things as easy/simple as possible for new contributors, but NOT at the expense of adding a gotcha for expert contributors. The experts are what keep a project going over many years instead of just releasing version upon version of trivial spelling fixes.
(And, btw, the default "merge" option for GitHub PRs also sucks. It should be possible to simply disallow non-FF merges and to force all merges to be FF. EDIT: Interestingly, this seems to be about the only workflow explicitly forbidden by the new rules... unless, of course, you're willing to merge everything manually using your local copy of the repo and pushing from that to GH.)
Yeah, it is also the obvious thing that is missing in the review stage of a pull request - viewing all the content and all the diffs separately but on one page, in a serial way that corresponds to the actual order they will show up when you do git log, all on the same page.
This is something that Gerrit supports natively: you can have a Gerrit CL that depends on another CL. It's unfortunate that Github doesn't support any equivalent.
> Before making a pull request (or doing any sort of merge), you should rebase against upstream master (or whatever you're going to push to)
See, and maybe this is because I'm just dumb or something, but I have never gotten rebasing to work for me. Ever. Every single time I do it I read at east 3 articles about it so I don't screw something up, I attempt to do it and ultimately I lose a bunch of work.
I just don't get it. I can write web, mobile and desktop apps and I like to think I'm pretty good at it. But I'm one of those people who constantly have commits of merges in their code because for whatever reason I just can't get my head around making rebasing work correctly.
Am I the only one? Sorry for the derail but it's bothering me that I've never gotten this to work correctly and I feel otherwise normally smart. ¯\_(ツ)_/¯
1. Always use the "upstream" branch as your rebase target - "git rebase -i master", or " git rebase -i origin/master". This is almost always what you want, and picking the wrong base is the most common error I've seen when teaching people rebase -i
2. Use autosquash! https://robots.thoughtbot.com/autosquashing-git-commits. If you have trouble with the text-editor interface you get when you run rebase -i, this will both handle its usage, and in the long run give you some visual examples of how the interface is supposed to be used. If you're really into this, set the config option "rebase.autoSquash true" to avoid the extra command-line flag.
3. If you mess up and realize in the middle, git rebase --abort.
4. Use the reflog after the fact for both finding and undoing mistakes: git diff branchname branchname@{1} to check for unintended code differences, and git reset --hard branchname@{1} to undo the rebase.
Thanks! I get the feeling I should give up on using a GUI for most of my git usage as doing many of these seems awkward or impossible with the GUI. That's probably part of my problem.
For what it's worth, I pretty much exclusively use git through Eclipse's EGit UI. I do a lot of rebasing, as we use Atlassian's "centralized" workflow. [0] It's interactive rebase interface is pretty good. If you haven't used it, maybe try loading a repo into it and see how you do.
Yeah. I'd recommend that. Personally, I found that I didn't really understand git until I did it all from the command line. YMMV, but that's what made it all click for me.
I think the advice to rebase runs up against the business pattern of pushing your branch as soon as you create it (git-flow and a lot of jira/stash integrations work like this). Also some teams want to see evidence of your commits as you make them, which means pushing as you commit.
If you have a branch and it's already pushed, rebasing just feels kind of funny and can sometimes cause a lot of problems if anyone else has checked it out.
If you have a branch and it's local only, then merging from mainline into your branch and selecting rebase instead of merge is relatively painless.
One trick that's worked ok for me in a private repo is, before starting to edit the fix-spline-reticulation branch (which has a handful of separate logical changes, fixes discovered midway through a later change that really belong in an earlier change, and temporary debug code that was never meant to go into the product) for publication, to do
git branch fix-spline-reticulation.0
(or .the-next-sequential-number). Then no matter how badly the "rebase -i master" goes, there's a branch tag pointing at the original state, and
will destroy the failed attempt and restore the branch to its earlier state. (Note that if you decide in the middle of the rebase that you're losing, "git rebase --abort" will undo anything you've done so far; you need the backup only if you regret the rebase after you're finished). It also makes it easy to "git diff my-feature.0..my-feature" and confirm that all the changes in the edited history add up to the same as the real history.
Sometimes I do this in the middle of development to move all the changes intended for the product ahead of the temp debug stuff in case I suspect the debug code is causing problems. Keeping the debug code in the dev branch even after the cleanup rebase makes the diff to check the rebase easier (then, of course, the merge should take the commit just before the debug).
Best never to do let anything but the cleaned-up branch hit a shared repo.
> See, and maybe this is because I'm just dumb or something, but I have never gotten rebasing to work for me. Ever. Every single time I do it I read at east 3 articles about it so I don't screw something up, I attempt to do it and ultimately I lose a bunch of work.
Rebase takes a little bit of practice, but everyone who's using git owes it to themselves to learn it by heart. It's almost like having superpowers compared to any VCS which doesn't have rebase.
My advice[1] would be to simply create some dummy repository (perhaps just copy an existing repository with some real code) and going through various scenarios described in the git-rebase man page (using some trivial changes). If something blows up, don't worry, you can always just start from scratch.
The key to making rebase work for you is: 1) understanding the underlying model of git[2], and 2) practice, practice, practice. With enough practice you'll get a good feeling for which "type" of rebase works best in a given situation.
[1] In addition to the excellent advice given by others in this thread.
[2] It may look like it's really all based on snapshots of files, but the workflows are definitely mostly centered around patch-based thinking.
I know that I probably swear in church since git is the current de facto standard for version control but this shows that gits usability is way too low. Why do I have to invest so much time to understand the inner workings of a tool that should just help me collaborate with my coworkers?
I've given up on understanding git and use gitflow and the built in tools in Intellij Idea for all my branching/merging/committing needs.
Because this is a quite advanced feature, and creating an interface for it is inherently hard. IIRC, the IDEA interface for interactive rebase ends up looking exactly the same as the text-mode one.
Version control is hard, simple as that. Git actually makes a great job at keeping simple stuff simple, but if you need some of the more complex stuff... well, I guess you could always go back to pen, paper and a secretary (aka: make someone else do it for you).
This is completely unnecessary. Everything git does, git can undo as long as your working tree is clean when you start the rebase. git reflog and git reset are your friends, if you want to "get back to where I was before I started this awful merge".
In tricky situations, I always commit work done. Then I attempt to do potentially harmful work. Note that afaik you can't lose commits in your history (they may be hidden, but reflog to the rescue). If I am very unsure whether something will work as intended, I place a dummy branch (a tag will do as well) onto that safety commit which will make it easier to find it back (in that case you don't need to resort to reflog). I never lost work once committed even when I painted myself into a corner. Note as well that rebase -i will always create a new commit rebased onto the entry commit. Going back to where you started is always possible.
I think that GitHub's pull-request-based model is fundamentally broken. Gerrit's model, where every commit is quasi-independent (and hence must pass tests) and you can easily edit without force-pushing anything or losing review history, is superior (though not perfect) in almost all cases. (Exception: merging a long-running feature branch where all the commits in the branch have already been reviewed.)
This is GitHub's attempt to solve the problem without really changing anything. It won't really change anything. Since pull requests routinely contain a mixture of both changes that should be squashed (fixups) and changes that should not be squashed (independent changes), this just means that you get to pick your poison.
I used to strongly believe what you do until my company started using Phabricator, which forces the squash workflow on you. It makes your history more useful, not less. The pull request is the appropriate unit of change for software. Make small commits as you develop, then squash them down into a single meaningful change to the behavior of your software.
As a git novice I wonder, doesn't a proper workflow do the same thing? When I submit a feature branch it might have a lot of ugly commits. However, once I merge it to an integration branch there is one nice commit explaining what I did.
When coworkers create Pull requests I don't go through all of their commits and changes along the way. I just look at the diff so, I don't see the need for them to squash it first.
Sometimes yes, sometimes no. Merge commits are nasty imo and I'm glad we can now forbid them outright, but a full squash isn't always the solution either.
Lots of back & forth. All the commits are related, and the PR is there to land all of those commits at once. I could land some of them right now (as they're safe to land), but keeping them in the PR keeps everything related in the same place (and none of them are required until that last commit lands).
A PR mirrors a "patchset" on mailing lists. You don't always want to squash all of it.
What you do want to avoid is a situation like this:
Where the original author creates their original commit and doesn't know how to --amend + push --force to the PR, and you end up with a ton of commits which you don't want to land all at once.
To clarify, pull requests shouldn't be squashed before review. They should be squashed when they get merged in, like this GitHub feature does. The granular commit history is useful during code review. It is not useful as a future developer trying to evaluate how the behavior of the program changed over time.
Right, sometimes. Pull requests are not necessarily a "unit of change" like you mentioned, though. For example, the first link I gave should not be squashed. But I don't want it to create a merge commit either.
I'm a little underwhelmed with the feature, it looks like it's either "squash everything" or "make a merge commit". There's no option to rebase & merge and/or selectively squash.
Exactly. In order for always-squash to work, then every PR must be the smallest possible atomic change. But often times certain features don't degrade to nice small atomic changes. It's sometimes useful to see that as a development process smell and consider using feature flags and other things to incrementalize the development, but sometimes the cleanest thing to do is just have a series of commits. I don't see a good reason to take this option off the table since source code history management is truly a craft in its own right.
FWIW, I prefer a carefully curated rebase and then merge --no-ff so that you can still see the branch and get at the branch diff trivially, but the history is still linear for practical purposes so bisecting is clean, etc.
Interesting. It's the first time I hear a fairly solid argument in favour of --no-ff. My main argument against it is keeping a clean commit log on github itself (and the default git log), as it's an entry point for new contributors.
I think your first link should be squashed once the code has been reviewed. When looking back on history, commits are most useful when they're a list of behavior changes in the software. That pull request "exports meshes as OBJ." That's what's useful for future developers, not "add Transform fields." Leaving those in your history makes it harder to work with, not easier. If someone cares about the back and forth that happened within that behavior change, the pull request is always available.
"Add transform fields" may not be a very descriptive commit message, but those fields are fully independent from the OBJ exporter. They are the implementation of unity's Transform class. This implementation was stubbed before, it happens to be needed for an OBJ exporter to go through, but has nothing to do with the exporter itself.
It seems like it'd be nice to have two levels of granularity exposed in views of a source control system's history, basically corresponding to pull requests and commits. So you could drill-down to individual commits as needed, but would normally be able to work at the PR level.
I suppose it does, though at least the tool my org uses doesn't write good descriptions on the merge commits that are created upon merging in a PR — they're just like "Merge pull request 190 from …" when I'd prefer it to be named for the changes that are actually in that PR. That's good to know that exists, it could be useful. Thanks.
But the PR isn't retained (afaik) in the repo's history as a distinct entity (I'm talking about git proper here, not extra tools like GitHub, etc). In the end, git just has commits. [Edit: as prodigal_erik points out, perhaps merge commits are really what I need to be looking at.]
Sure, it's a terrible feature to always use. And it's likely to be of little use to contributors who know how to use Git well. But in large open-source projects, often new contributors make a small change that needs a few minor corrections. Eliminating that final back-and-forth ("squash please") is a huge win for maintainers.
There's no guarantee that every individual commit of a feature branch is meaningful, or even builds. It also makes the history of the master branch a lot harder to read when it has tons of commits representing the minutiae of the feature's development.
It really depends on each individual's workflow. I tend to use lots of "in progress" commits (each time things are "green"), and as I go, I regularly squash the commits, so in the final pull request I typically have several commits (and if I wasn't squashing it would have been a dozen). If I do feature and a refactor, they are always separate commits, it's easier to review these and bisect if something turns out to go wrong.
Some people might do similar things but they might not assure each commit is green, and they never squash anything (so you end up with non-meaningful commits).
As @3JPLW said, I see when it can be useful for opensource maintainers to have the option to squash someone's commits, when the change is small, but there are many commits (due to a review ping-pong etc)
1. branch off master
2. work, commit, push, test (on CI server)
3. decide it's time to ship
4. rebase -i, push, test (again)
5. git checkout master && git merge --no-ff feature_branch
(make the merge commit message a summary of the feature)
master ends up being a list of feature branch commits, bookended by the merge commit which introduced the feature. Getting the squash commit diff is as easy as 'git diff feature_branch_merge^..feature_branch_merge'.
Squashing entire pull requests that change multiple things into a single commit is a bad idea, yes. But uploading and asking for review on such wide-reaching pull requests is a bad idea in the first place.
Using fast-forward without squash is also a bad idea in many cases: the string of commits may contain multiple points that don't actually build or pass tests, even if the final commit in the chain fixes all that. There's no point in landing those broken commits, and doing so will confuse bisection tools.
Fast-forward with squash, and enforcing reasonably sized code reviews as a matter of culture, is the best of all worlds in my opinion.
Rebasing seems to clutter the Github PR's commit history and diff with all the commits to master that were made between the time the branch was cut and the time the rebase happens. But it doesn't do that if you merge in master. I never understood this.
It's a bad idea because it's a bad implementation. If it allowed you to select what to squash, defaulting to the behaviour of git rebase -i --autosquash master then it would be a clearly good feature.
This is a presentation issue masquerading as a data issue. If somebody suggested deleting data because a report was ugly, they'd be laughed out of the room.
Give us tools to mark commits as unimportant or group them together as a meta-commit object for history purposes.
> If somebody suggested deleting data because a report was ugly, they'd be laughed out of the room.
If somebody suggested keeping data that showed every step of a person writing a report, they'd be laughed out of the room.
It's gray area that varies significantly by feature complexity and team dynamic. I find it frustrating when someone merges a branch with 1 real commit and 3 more one-line commits or trivial fixes that should have been in the first.
So that's essentially what mercurial's evolve extension does. Which is pretty useful in some circumstances, e.g. if you have a review tool where you want to support rewriting history in a nice way (the typical approach to this in git tools is either a) don't meaningful support history rewriting, b) require manual ceremony for each history rewrite, or c) add unique ids to each immutable-across-rewrites commit).
Whilst it's clear that retaining the pushed history can be useful in some cases, I don't understand the notion that disallowing history rewrites helps retain useful data in general. Developers can make commits for all kinds of arbitary reasons e.g. they reached the end of the day, or had to switch branches to work on a different patch. That doesn't seem like a particularly useful thing to record. To take it to an extreme, I wonder if any of the people who think that the precise commit history gives useful information about how a feature was developed have configured their editor to commit on keystroke, since that seems like the logical conclusion of that position (and indeed is effectively what tools like etherpad do). I suspect not because, actually, being selective about the information that you keep is rather helpful. During rebase we see the developer as curator, selecting the most useful representation of a set of changes for the benefit of future readers. or, to use your analogy, if someone suggested removing meaningless data from a report to focus attention on the most important points, then they would certainly not be laughed at, but praised.
Of course GitHub's implementation is too blunt a tool to be really useful, but hopefully we will eventually get something better.
I hate squashing branches. There's a lot of value in commit messages; they're educational and are a form of documentation. It's on the developer to squash the "oops" commits, during a rebase, rewriting the commit message so it has some value when going back in time to look at changes.
I'd love to see a commit linter, that points at commits with text like "oops" and "fix my derp" to suggest possible commits to squash.
Git history shouldn't resemble a hot mess, but the evolution of code should be pretty granular. I'd take the hot mess over full squashing, though.
If I feel like the history of a branch is important, I add a git tag to the branch head before rebasing. I have a naming convention for these tags.
Then I usually do a rebase -i on to the main branch.
Perhaps I'm greedy, but I'd like also an additional option to rebase without squashing ...
Also, it's not clear if it is possible to disable the merge button completely. I prefer to use the command line to rebase and fix the details in the commits, but the big green "merge" button is always too tempting and it's easy to press it by mistake.
This is a huge issue for me both with GitHub and Atlassian Stash.
On both you even cannot see when the branch was started, and you can merge fine as long as there were no merge issues.
Then you run gitk and it looks like a spaghetti-horror, with trivial branches being started 200 commits ago.
I don't necessarily need a "rebase&merge" button but at least info about the shared ancestor with master.
This is a feature I've wanted for such a long time. While it's perfectly feasible to do through the command line, I've always found myself having to force push to update the history on github's side of things.
I typically did it through git rebase -i HEAD~N, so maybe someone here on HN knows of a better way to squash a commit whenever you're updating remote history. Albeit, it seems that updating remote history with a squashed commit isn't entirely attractive behavior and that's why I was forced to force push.
Two things you can do differently, if you feel this would be appropriate.
Instead of git rebase -i HEAD~N, I typically use git reset --soft HEAD~N followed by git commit.
Instead of git push --force, use git push --force-with-lease. This only updates the remote if the remote's current state is what you expect. For example, it will fail if someone else has pushed to the same branch in the meantime.
Usually I'll do git rebase -i origin/master (or upstream/master, or wherever in branched off of on the first place). Doesn't require me to count up to N commits, and also does an actual rebase.
But yeah, force push is kind of inherent to the process - you're rewriting history, no two ways about it. Usually for my own forks of projects, though, I'll go into .git/config and add a 'push' option with a + in front of the refspec - this enables force pushing always. This really only works and is safe for workflows where there's a distinction between your own personal GitHub account and the upstream that has the authoritative copy - you really don't want to rewrite history by accident on the latter.
Oh god no. I made the mistake of moving a team to squashed commits once. The lack of individual commits poses large problems down the line. 2 nonstarters come to mind:
1: Completely ruin your ability to git bisect any bug injected in your branch. Instead of getting a 10 line commit, bisect will point you to hundreds or thousands of lines instead.
2: All code will blame to a single person. Code with 6 people on a large branch? Want to git blame the code to see who wrote the function that is weird looking so you can ask questions? Too bad.
Do not squash branches on teams. One of the biggest mistakes of my professional career.
This is for a "pull request", namely an individual logical change. Your two points don't apply. If you're dealing with whole branches with multiple developers, stick with merging, but this isn't that.
point 1: merge smaller features more often. Multi-thousand line PRs suck no matter if they're squashed or not.
point 2: As people mentioned, this is for PRs done by individual people, usually squashing their local history. If multiple people were working on the branch, they should have been PR-ing against that branch (squashing the commits), then you merge that branch to master (you may rebase it, but not do significantly destructive stuff).
Even then, these are features to use with critical thinking. If your PR is really large, massage the history to be relevant and meaningful for git bisect purpose. Use full squashing when it was a local work full of "My hands are typing words" commits of no relevance.
I swear, we're in an industry full of people making 6 figure salaries, who treat their job as if it was a call center script to follow. If you're an engineer, use your head and engineer solutions around the tools you have.
Your experience sounds horrible, but you were clearly doing something very stupid.
Squashing is a tool to use with discretion. You squash two or three 5 line wip commits together. And I'd never squash changes from two authors (except perhaps whitespace or comment fixes).
A feature branch needs cleaning up before publishing. These bug and typo fixes needs to be squashed in the branch, but the history should preserve a sequence of commits corresponding to atomic changes because it tells a story.
A commit should be small enough to make it easy to check if the change is correct. It should be self contained so that it can be moved arround, cherry picked, etc.
This is why the local commit history should be considered as a draft of the story, and the one published should be the official one aimed to be easily readable, verifiable and manipulable.
Any plans to allow for squashing but with a merge instead of a fast-forward or fast-forwards without squashing?
CI will still run against the hypothetical merge commit, no? I wonder if there are edge cases where merge vs squash+fast-forward would result in different conflict resolutions and different trees, so master could end up with a tree that didn't have tests run against it.
> master could end up with a tree that didn't have tests run against it
Isn't that already the norm? I.e., most projects run CI on an unmerged PR, then merge to master, then run CI on master to see if the merged tree is actually good. Are there projects which test a PR's post-merge tree before updating master? That would be nice, but I don't know of any tools which support that workflow, and it wouldn't scale forever since it would involve a serial merge queue.
Travis CI for example and I'd imagine most CI servers run tests on the `MERGE_HEAD` of the PR which like lotyrin said is the hypothetical merge commit. If a PR is opened from latest master, CI runs on `MERGE_HEAD` which is the same with the merge commit after the PR is merged. But if something was pushed to master after the feature branch was branched off then it's not the same commit. That's why it's recommended to run CI after merging again. But by default tests are not run on the PR HEAD which is the tip of the feature branch.
Call me naive, but wouldn't this problem be best solved by requiring that commits represent meaningful and working increments of work?
I use 'git add -p' judiciously and only commit when having reached a point where something can be usefully said to be in some way "done". Sure, it's not perfect, and occasionally I end up having to do some cleanup of miscellaneous printf statements, debug values or typoes in subsequent commits, but this is something that should really be avoided if possible.
Waiting until you have something useful has other drawbacks. For example, it might take many hours or days to get to a 'useful' and 'done' state - I don't want to go hours or days without saving my work in a manner that is easy to retrieve if something goes wrong.
Besides the obvious 'hard drive failure' or 'laptop stolen' situations, there are also more frequent situations where 'oh shit, I went down a totally wrong path there - let me back up a bit and try that again.' Git commits are little save points that let me do small experimentation and go back if I need to.
Very good points. I guess I've just been too lazy to learn advanced rebasing / commit aggregation. Maybe I should, so I can more effectively take advantage of the upside while not polluting my commit history with intermediate crap.
I'm waiting for the code review tool that takes a massive squashed PR and cuts it up into a series of clean, atomic commits that can be reviewed individually.
I believe Phabricator supports this workflow. Create a revision for a code change - as more commits are made, update the revision with those changes. Users can see what changes were made between commits and hold discussions on them. When it's ready, landing can (optionally) squash the diffs into a single commit upstream. The main history will be linear and more-complete changes, while detail about the development of the change is retained in Phabricator revision.
Yeah, this is dumb. Being able to effectively bisect large projects depends on having smaller commits. If your commits are all huge, your bisect will hit some 500 line patch that does 5 different things -- it'll easily quadruple the debugging time. Not to mention that having small self-contained commits is a good thing.
This, as rebase, is a great idea for people who would rather use SVN instead, but have to use git for some reason or another.
I mean, if you want your history simplified into a linear squashed series of commits, why the hell do you use VCS which models a history as acyclic directional graph in the first place?
Maybe I'm missing something, but I've never understood the point of cleaning up commit history. The only time I ever look at commit history past a few days is if I want to know when something broke (in which case I WANT every part of the history, even the messy bits), or if I'm trying to refresh my memory of what I've done for the year (for performance reviews or whatever) in which case I guess it's marginally useful, but it's pretty easy to skim over "fix build" and such.
As this thread approaches 300 posts I'm wondering when we're going to get out of this Git Tarpit we've somehow got ourselves into?
To be charitable: Git seems to be a good tool designed for Problem A, being widely used for Problems B,C,D for which it is a fairly poor choice.
I _think_ we got here through some mix of "but it's really fast!"; "I can do _anything_!!"; "But Linus says its great!"; "I don't need to pay for a beefy server any more!"; "New _must_ be good, right?".
In any event, how do we get out the ditch and back to work making software vs. trying to reason about the unreasonable? I personally, for the kind of projects I'm involved with (small teams, all paid by the same piper, with aligned clear goals and competent coders), had perfectly satisfactory revision control systems since around 2000 (except when required by employer to use Clearcase..). It would be nice to get back to that future.
Annoying: you can't turn off both. If your project has a workflow where the webui merge should not be used (e.g. using signed merges) there is still no way to achieve that.
I contributed a little to JUnit and they ask you to squash your commits before making a pull, it took some time to do it, it's so confusing/wierd using regular GIT.
Awesome! Phabricator got me addicted to the clean history of squashing commits and the logical changes staying together in source control (as opposed to grouping in a PR).
It seems to me that the scope of this article is pretty narrow (in a good let's avoid a flame war way). And it describes one of the few scenarios where I think squashes are beneficial.
But then the conclusion doesn't quite add up. if I want to remove all the merge mess from a PR don't I actually want to rebase the PR, not merely squash the history? Or dos I miss the point he was making?
This is such a nice feature. Thank you for working on it. Keeping history clean is important, especially in enterprise solution where you have to keep support multiple releases. You want to select certain commits/features in one version. With merge/squash, you would get a cleaner history, and it is easy to pick commits you want.
I believe there should be more open communication and a record the public can fall back on while these developers make their improvements. Something in their face. Too many times did I track back and see unprofessional comments being made and things being done that seemed downright suspicious.
if it were up to me it would be alot harder to get a developers license and you would have to meet regulatory standards and have degrees to uphold your professionalism while acting as your own developer it seems to me that alot of developers have taken things into their own hands and are trying to make a quick buck any way they can get it. don't be surprised if you tell your mother or father or sibling to look at what licenses they have agreed to on their phones and they find alot of outdated unassigned licenses to back up their privacy. it seems to be an epidemic and how are we going to stop it?
This obsession with "clean" history seems to me nothing short of insanity. Source control has one job: to record the history of code in order to be aid in figuring out what happened when things go wrong. If everything always went well, we'd just have great merge tools and throw away the history.
I can understand a desire to filter out stages of a project by different levels of review (I just ran the build and tests passed so I committed vs a bunch of people reviewed it so I merged), but that people solve that by deleting or rewriting history to be something different from what actually happened is just nuts.
Is it just that git makes it easier to change history than to add metadata for filtering? Why have we not seen presentation tools to solve this problem rather than what seems like a ubiquitous readiness to alter and throw away the messy but accurate facts about what happened?
Because the lack of squashing actually makes finding bugs harder. Which checkin with the status "change i to l" or "whoops, typo" was the bug in?
It's a lot easier when an entire changeset has a single checkin into master, because then when you're doing your bisection there are a far few changes to bisect.
The key principle is that the software should always correctly work at any point in the chain of commits, so you must squash commits that are "oops, fix X in previous commit".
Once that is satisfied, commits should be as small as possible, so that information about the grouping of changes is preserved.
After completing a feature (or part of one) I often "squash" manually by performing a mixed reset from the tip of the in-development branch back to a good parent commit.
This leaves all of the feature's changes in your working copy, which you can then stage by line/hunk and individually commit in clean, atomic pieces with the benefit of already having written the final code.
This removes the in-progress commits like a Squash, but pieces of code can still be brought in as individual easy-to-review commits. And it's potentially easier to understand / perform manually than rewriting history via a git command that would do the same thing.
This is great! But what about fixups? I often prefer a fixup to a squash when the commit in question was a WIP or something, and I don't have any desire to preserve the message in the final commit.
This is wrong at so many levels. Of course we don't care about "progress" or "woops I fucked up" commits, but people also do commits for things like coding style, and these commits should be keep separated from the others, and DO NOT warrant a separate PR. If it is about changing all tabs to space in a file, for instance, different PRs will be hard to work with, because of conflicts. Also, people who write WIP commits should learn how to squash them themselves, and give them a meaningful commit message.
Usually when squashing branches locally, all the changes are set to myself as the author, effectively losing history of who did what in the feature branch. How does Github handle this?
Additionally, the lack of the commit history for that branch often caused merged conflicts when merging the same branch again (if it had additional new fixes, for example). That's why I switched to using git merge --no-ff.
If it were very easy to do, I would definitely do a git squash, as it keeps history very clean. I just don't want to have the problems listed above.
I think squashing commits makes sense if you're working in a big team and/or on a complex/large project - The main advantage of it is that it speeds up the QA process because it cleans up all the back-and-forth (exploratory) changes that tend to happen during development.
If you squash properly, each commit will represent a small standalone feature.
Squashing is not an alternative to merge workflow. It's what you do to clean up before you integrate your work (whether by rebase or merge). You've just made seven changes, which should just be three: git rebase -i HEAD~7, squash away. Okay, now you have three. rebase them on top of new work in the upstream branch, or merge? Separate question.
This is great news for us as we prefer this flow. However, we actually mostly merge via our custom tool which uses GitHub's API. I can't find anything in the documentation about whether these options apply to API merges or if there's any query params that can achieve that behavior from the API. Anyone know anything about this?
I personally like this and it fits well with my team's workflow (though I am a bit concerned it will prevent engineers from learning to do these things with git). There are pros and cons for sure but I think if you are losing a lot of resolution by squashing then the scope of your pull requests might be too big in the first place.
The option to avoid merge commits when merging pull requests misses the point, but apparently many users demanded it for some reason, so Github implemented it.
Here's how merge commits, rebasing and isolated small commits work:
You branch your topic off master and make many commits while working on it. This is all local.
Once you're ready to publish for review/integration, you squash fixup and backup commits into a coherent patch set, where each and every revision builds and works. This is where you can rebase and squash for good reason. Now you can push to Github.
If you, like Phrabricator, create a single big commit with all changes lumped together, then it's impossible to bisect and follow the thought process behind changes. Try to git-bisect linux.git vs a repo that's been managed with Phabricator and its mega commits.
With small commits that each make one coherent change, you can easily include relevant explanations in the commit message, which is much harder to achieve with a single mega commit. Further, it's very simple to follow along the development process of changes with separate commits. If you have one big diff, it's hard to understand the changes of a branch, whereas reviewing small commits with an explanation in the message and the overall reduction in diff size makes it much, much easier to understand for reviewers.
With separate small commits you review each step and finally arrive at the complete feature implementation at the end. For someone who has to review code they didn't write this saves a huge amount of valuable reviewer time for actual reviewing than trying to reverse engineer the steps taken in a big diff.
Moreover, with multiple commits, you can easily approve of some of the commits, while requesting improvements for others.
Gerrit implements this well and the process is what linux and git and other projects use when reviewing big patch sets. Set is the important word.
Finally, why do you want merge commits? Unless you always make a single mega commit ala Phabricator or the new Github feature, having merge commits provides a very practical way to see that a set of commits landed via foo-branch-X. If you've ever viewed a git log graph, that's the interesting integration points, which you will lose if you omit merge commits. In a merge commit you can also include extra stuff as part of the merge commit itself, so it's not just useless metadata.
Do any VCSs have a notion of a commit of commits? If you could group a series of sequential commits into one commit on trunk it seems like you could have the best of both worlds: an overarching commit for your change and a series of how the sausage got made.
Rarely do conversations around these parts get as heated as they do when git process comes up. As I read through these comments, only one thing surfaces: everybody organizes their shit differently. If you're here trying to sell your process, why?
A bit OT but a feature I would love to see in git is to be able to see which branch a commit came from. Especially for shortlived branches which we prune periodically on the server (git branch -r --contains won't work as a result)
no reason why developers should not be reliable for their work. if you ask me there should be a process to handing out open licenses and from what I have seen apache gives any one the right to do what they want. I would love to see stricter laws when it comes to third parties and open source licensing, including the chatter back and forth.
Actually Bitbucket Server (née Stash) already supports squashing and a variety of other pull request merge strategies. They're just configured[0] per repository, project or globally rather than an explicit option at merge time.
If everyone on your team actually knows how to use git, much better to let them rebase their commits and mark out a series of clean, atomic commits which introduce the feature you're reviewing. If you have people who are incompetent at using git on your team, this feature will help protect your history from them.
This unfairly places the blame for Git's utterly shitty UX on the part of the users. When you have thousands of users who struggle to use a tool correctly, it's the tool's fault, not theirs.
I've been using Git for years, work professionally full time on an open source project that lives on GitHub, maintain several open source projects with a number of committers and generally live and breath Git and GitHub all day.
I still fucking hate rebasing and get tripped up by it on the few times I end up having to deal with it.
> I still fucking hate rebasing and get tripped up by it on the few times I end up having to deal with it.
When I had no understanding of what was going on, I didn't like it either. Now that I use it frequently, I understand it better, so I don't hate it anymore.
I like running `git rebase <main-branch>`, where <main-branch> is typically master, in my-new-thing branch because it lets me deal with any conflicts from upstream one by one.
I also like running `git rebase -i` in my-new-thing when I have a bunch of commits with redundant messages that I want squashed into a single commit before I push the changes. Basically anything that requires messing around with a range of commits is a good use case for `git rebase -i`.
Why do you hate it so much? There's really not much going on that you should have to hate. To me it's like a bunch of small, compartmentalized merges.
Genuinely curious, why the love for the `git rebase -i`? I find it much easier and more intuitive to squash a set of linear commits on a branch using `git reset --soft HEAD~n` where n is the number of commits to go back and "undo". Then make one more commit and you're off to the races. Note: this is not useful if force push is disabled and you've already pushed some of the commits to the remote (feature) branch.
In addition to bpicolo's point below, things quickly break down if your commits have file removal or renames. I've gotten bitten more than once and now always resort to git rebase [-i] to avoid this.
The problem is that the tool is both great and terrible. It's basically like a Formula-1 car: ultimate performance, but with huge potential for disaster in the hands of someone who doesn't know what they're doing. It doesn't help that the tool has been growing organically over time, leading to a really confusing UI. Also, it's extremely versatile, but that's both a blessing and a curse, as people can develop totally different and incompatible workflows.
Maybe people need to create some command-line front-ends to git which force users into particular workflows and subsets of the commands, and which clean up the UI, much like how almost no one uses TeX, but instead they use front-ends like LaTeX.
Git is a great data structure with a pretty bad tool to manipulate it. That said, what MBlume said is that one should learn to use the tools one uses (and if you're using Github, you're using git), which is not a defense of git in itself.
Git's usability is a mess. I wouldn't judge anybody on their ability to use Git.
Being subjected to Git at work makes me long for the days when I used Lotus Notes for email. Sure Lotus Notes is a usability disaster, but at least you get the sense they were trying to make things work. And, to be fair, it got slightly better each version. Using Git makes you feel like it was developed by people who simply hate you and want to see you fail.
Confirmed as not a joke. (The change is subtle as you have to click the green Merge button before being presented with the ability to choose a merge type via a combo button/dropdown component.)
This comment breaks the HN guidelines by calling names, and unfortunately a number of your other comments have done this as well. Please post civilly and substantively or not at all.
Everyone is a bit of a stretch -- the OP might have been a bit insulting; but he has a point.. hacker news can be somewhat of an echo chamber, and I think people assume Git is (or should be) a lot more widespread than it actually is. A lot of large companies still use perforce for large repository support, a lot of people still use subversion because it's simpler and they don't need a DVCS, etc. Having been the "git guy" at a lot of places, I can definitely tell you that you can't just hand-wave away its usability problems, it definitely has a cost on peoples' time that other systems don't. (I rarely have to answer other peoples questions about P4, for instance)
Well having managed 1000+ clients a few jobs ago, I can tell you the majority of companies these days use Git. With the proper hooks and gitflow I never found I had to tell users much once the workflow was understood.
At my last job we had about 40 devs in India spread out in different cities. We re-wrote much of Android and our Git repos were massive. This meant devs needed a local repo and couldn't be expected to work with a remote other than commits. Only once with all these random developers did history become a mess and we had to rebase and clean things up. I think a lot of people fail to understand how to implement Git properly and are making it overly complicated for daily use.
> I can tell you the majority of companies these days use Git
The majority of companies you've interacted with use Git.
I'm guessing you're in the web development sphere. If you were in the game development sphere or the large-company sphere, things might look very different to you.
Look, I like git, I use it for my personal projects. But I'm also watching the company I work for transition to it, and I've watched people use it in past jobs, and I can tell you that I've seen a lot of smart engineers become entirely frustrated with that system.
At the moment we're on perforce, and while I think git is objectively better than perforce, we have a lot of engineers that are completely happy with perforce and are annoyed with the transition. And you know what? I can't blame them. Git does a lot of things better, but not necessarily things that make these peoples day to day life easier, and they've (correctly) concluded that this transition is going to require them to learn something difficult that won't really give them any direct benefit.
The idea that git is universal I think comes from the success of github. And more power to them, it's great. But while git is fantastic for open source projects, it's not universally perfect in every context. It's really really hard to use, and if you don't need any of the benefits that a DVCS provides it's not irrational to conclude it may not be for you.
The problem is, are we developers or source code librarians?
My git workflow is pull, commit, push. I don't rebase or branch or anything else because it completely distracts me from what I'm doing as a developer. YMMV.
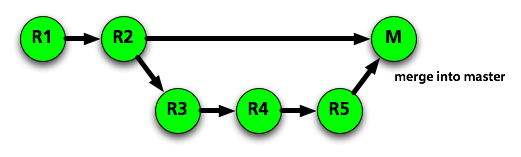{kind=link}
{kind=link}
Kudos to GitHub for providing this feature that a lot of people have asked for. I obviously don't plan to use it, but I appreciate that it's an option for those people that like their small, harmless lies. ;)