This is an excellent tool to realize how an LLM actually works from the ground up!
For those reading it and going through each step, if by chance you get stuck on why 48 elements are in the first array, please refer to the model.py on minGPT [1]
It's an architectural decision that it will be great to mention in the article since people without too much context might lose it
Wow, I love the interactive wizzing around and the animation, very neat! Way more explanations should work like this.
I've recently finished an unorthodox kind of visualization / explanation of transformers. It's sadly not interactive, but it does have some maybe unique strengths.
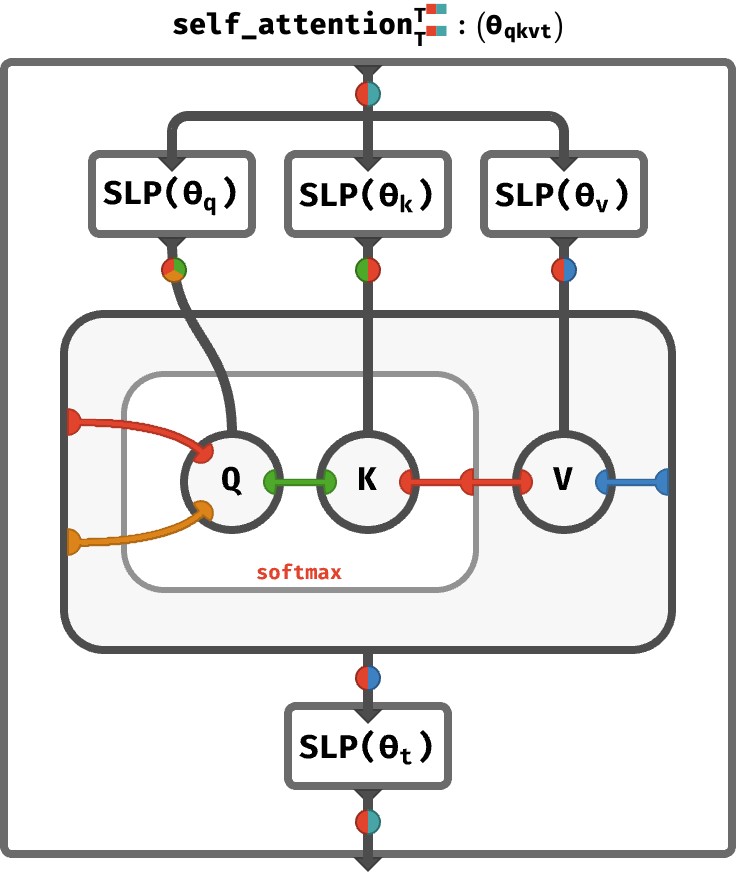
First, it gives array axis semantic names, represented in the diagrams as colors (which this post also uses). So sequence axis is red, key feature dimension is green, multihead axis is orange, etc. This helps you show quite complicated array circuits and get an immediate feeling for what is going on and how different arrays are being combined with each-other. Here's a pic of the the full multihead self-attention step for example:
It also uses a kind of generalization tensor network diagrammatic notation -- if anyone remembers Penrose's tensor notation, it's like that but enriched with colors and some other ideas. Underneath these diagrams are string diagrams in a particular category, though you don't need to know (nor do I even explain that!).
Are you referring specifically to line 141, which sets the number of embedding elements for gpt-nano to 48? That also seems to correspond to the Channel size C referenced in the explanation text?
That matches the name of default model selected in the right pane, "nano-gpt". I missed the "bigger picture" at first before I noticed the other models in the right pane header.
The visualization I've been looking for for months. I would have happily paid serious money for this... the fact that it's free is such a gift and I don't take it for granted.
What a nice comment!! This has been a big failing of my mental model. I always believed if I was smart enough I should understand things without effort. Still trying to unlearn this....
Unfortunately you must look closely at the details to deeply understand how something works. Even when I already have a decent mental heuristic about how an algorithm works, I get a much richer understanding by calculating the output of an algorithm by hand.
At least for me, I don't really understand something until I can see all of the moving parts and figure out how they work together. Until then, I just see a black box that does surprising things when poked.
It's also important to learn how to "teach yourself".
Understanding transformers will be really hard if you don't understand basic fully connected feedforward networks (multilayer perceptrons). And learning those is a bit challenging if you don't understand a single unit perceptron.
Transformers have the additional challenge of having a bit weird terminology. Keys, queries and values kinda make sense from a traditional information retrieval literature but they're more a metaphor in the attention system. "Attention" and other mentalistic/antrophomorphic terminology can also easily mislead intuitions.
Getting a good "learning path" is usually a teacher's main task, but you can learn to figure those by yourself by trying to find some part of the thing you can get a grasp of.
Most complicated seeming things (especially in tech) aren't really that complicated "to get". You just have to know a lot of stuff that the thing builds on.
99% persperation, 1% inspiration, as the addage goes...and I completely agree.
The frustration for the curious is that there is more than you can ever learn. You encounter something new and exciting, but then you realize that to really get to the spot where you can contribute will take at least a year or six, and that will require dropping other priorities.
Andrej Karpathy twisting his hands as he explains it is also a great device. Not being sarcastic, when he explains it I understand it for a good minute it two. Then need to rewatch as I forget (but that is just me)!
Could as well be titled 'dissecting magic into matmuls and dot products for dummies'. Great stuff. Went away even more amazed that LLMs work as well as they do.
Another visualization I would really love would be a clickable circular set of possible prediction branches, projected onto a Poincare disk (to handle the exponential branching component of it all). Would take forever to calculate except on smaller models, but being able to visualize branch probabilities angularly for the top n values or whatever, and to go forwards and backwards up and down different branches would likely yield some important insights into how they work.
Good visualization precludes good discoveries in many branches of science, I think.
(see my profile for a longer, potentially more silly description ;) )
This is really awesome but I at least wish there were a few added sentences around how I'm supposed to intuitively think about the purpose of why it's like that. For example, I see a T x C matrix of 6 x 48... but at this step, before it's fed into the net, what is this supposed to represent?
A lot of transformer explanations fail to mention what makes self attention so powerful.
Unlike traditional neural networks with fixed weights, self-attention layers adaptively weight connections between inputs based on context. This allows transformers to accomplish in a single layer what would take traditional networks multiple layers.
In case it’s confusing for anyone to see “weight” as a verb and a noun so close together, there are indeed two different things going on:
1. There are the model weights, aka the parameters. These are what get adjusted during training to do the learning part. They always exist.
2. There are attention weights. These are part of the transformer architecture and they “weight” the context of the input. They are ephemeral. Used and discarded. Don’t always exist.
They are both typically 32-bit floats in case you’re curious but still different concepts.
“To weight” is to assign a weight (e.g., to weight variables differently in a model), whereas “to weigh” is to observe and/or record a weight (as a scale does).
affect (n). an emotion or feeling. "She has a positive affect."
effect (n). a result or change due to some event. "The effect of her affect is to make people like her."
affect (v). to change or modify [X], have an effect upon [X]. "The weather affects my affect."
effect (v). to bring about [X] or cause [X] to happen. "Our protests are designed to effect change."
Also:
cost (v). to require a payment or loss of [X]. "That apple will cost $5." Past tense cost: "That apple cost $5."
cost (v). to estimate the price of [X]. "The accounting department will cost the construction project at $5 million." Past tense costed. "The accounting department costed the construction project at $5 million."
I think in most deployments, they're not fp32 by the time you're doing inference no them, they've been quantized, possibly down to 4 bits or even fewer.
On the training side I wouldn't be surprised if they were bf16 rather than fp32.
None of this seems obvious just reading the original Attention is all you need paper. Is there a more in-depth explanation of how this adaptive weighting works?
The audience of this paper are other researchers who already know the concept of attention, which was very well known already in the field. In such research papers, such things are never explained again, as all the researchers already know this or can read other sources, which are cited, but focus on the actual research questions. In this case, the research question was simply: Can we get away by just using attention and not using the LSTM anymore? Before that, everyone was using both together.
I think learning it following it more this historical development can be helpful. E.g. in this case here, learn the concept of attention, specifically cross attention first. And that is this paper: Bahdanau, Cho, Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate", 2014, https://arxiv.org/abs/1409.0473
That paper introduces it. But even that is maybe quite dense, and to really grasp it, it helps to reimplement those things.
It's always dense, because those papers already have space constraints given by the conferences, max 9 pages or so. To get a better detailed overview, you can study the authors code, or other resources. There is a lot now about those topics, whole books, etc.
There is a lot more. Just google for "deep learning", and you'll find a lot of content. And most of that will cover attention, as it is a really basic concept now.
To add to the excellent resources that have already been posted, Chapter 9 of Jurafsky and Martin's "Speech and Language Processing" has a nice overview of attention, and the next chapter talks specifically about the Transformer architecture: https://web.stanford.edu/~jurafsky/slp3/
It’s definitely not obvious no matter how smart you are! The common metaphor used is it’s like a conversation.
Imagine you read one comment in some forum, posted in a long conversation thread. It wouldn’t be obvious what’s going on unless you read more of the thread right?
A single paper is like a single comment, in a thread that goes on for years and years.
For example, why don’t papers explain what tokens/vectors/embedding layers are? Well, they did already, except that comment in the thread came 2013 with the word2vec paper!
You might think wth? To keep up with this some one would have to spend a huge part of their time just reading papers. So yeah that’s kind of what researchers do.
The alternative is to try to find where people have distilled down the important information or summarized it. That’s where books/blogs/youtube etc come in.
Embeddings are sort of what all this stuff is built on so it should help demystify the newer papers (it’s actually newer than the attention paper but a better overview than starting with the older word2vec paper).
Then after the attention paper an important one is:
I found these notes very useful. They also contain a nice summary of how LLMs/transformers work. It doesn't help that people can't seem to help taking a concept that has been around for decades (kernel smoothing) and giving it a fancy new name (attention).
“Convolution” is a pretty well established word for taking an operation and applying it sliding-window-style across a signal. Convnets are basically just a bunch of Hough transforms with learned convolution kernels.
I struggled to get an intuition for this, but on another HN thread earlier this year saw the recommendation for Sebastian Raschka's series. Starting with this video: https://www.youtube.com/watch?v=mDZil99CtSU and maybe the next three or four. It was really helpful to get a sense of the original 2014 concept of attention which is easier to understand but less powerful (https://arxiv.org/abs/1409.0473), and then how it gets powerful with the more modern notion of attention. So if you have a reasonable intuition for "regular" ANNs I think this is a great place to start.
softmax(QK) gives you a probability matrix of shape [seq, seq]. Think of this like an adjacency matrix with edges with flow weights that are probabilities. Hence semantic routing of parts of X reduced with V.
where
- Q = X @ W_Q [query]
- K = X @ W_K [key]
- V = X @ V [value]
- X [input]
hence
attn_head_i = (softmax(Q@K/normalizing term) @ V)
Each head corresponds to a different concurrent routing system
The transformer just adds normalization and mlp feature learning parts around that.
Just to add on, a good way to learn these terms is to look at the history of neural networks rather than looking at transformer architecture in a vacuum
This [1] post from 2021 goes over attention mechanisms as applied to RNN / LSTM networks. It's visual and goes into a bit more detail, and I've personally found RNN / LSTM networks easier to understand intuitively.
1) When you zoom, the cursor doesn't stay in the same position relative to some projected point
2) Panning also doesn't pin the cursor to a projected point, there's just a hacky multiplier there based on zoom
The main issue is that I'm storing the view state as target (on 2D plane) + euler angles + distance. Which is easy to think about, but issues 1 & 2 are better solved by manipulating a 4x4 view matrix. So would just need a matrix -> target-vector-pair conversion to get that working.
You know what, I think the panning being pinned to a specific plane is actually great, it means you actually pan across the surface of the object instead of mostly moving it out of the viewport like in this example:
This pinning to one single plane works really well in this particular case because what you are showing is mostly a flat thing anyway, so you don't have much reason to put the view direction close to the plane. A straightforward extension of this behaviour would be to add a few more planes, like one for each of the the cardinal directions and just switch which plane is the one the panning happens in, might be interesting to try for a more rounded object.
To me the zoom seems to do what is expected, zooming around the cursor position tends to be disorientating in 3D anyway, though maybe I didn't understand what problem you complained about.
This looks pretty cool! Anyone know of visualizations for simpler neural networks? I'm aware of tensorflow playground but that's just for a toy example, is there anything for visualizing a real example (e.g handwriting recognition)?
Rather than looking at the visuals of this network, it is more better to focus on the actual problem with these LLMs which the author already has shown:
With in the transformer section:
> As is common in deep learning, it's hard to say exactly what each of these layers is doing, but we have some general ideas: the earlier layers tend to focus on learning lower-level features and patterns, while the later layers learn to recognize and understand higher-level abstractions and relationships.
That is the problem and yet these black boxes are just as explainable as a magic scroll.
For decades we’ve puzzled at how the inner workings of the brain works, and thought we’ve learned a lot we still don’t fully understand it. So, we figure, we’ll just make an artificial brain and THEN we’ll be able to figure it out.
And here we are, finally a big step closer to an artificial brain and once again, we don’t know how it works :)
(Although to be fair we’re spending all of our efforts making the models better and better and not on learning their low level behaviors. Thankfully when we decide to study them it’ll be a wee less invasive and actually doable, in theory.)
Is it a brain, though? As far as I understand it it's mostly stochastic calculations based on language or image patterns whose rule sets are static and immutable. Every conceivable idea of plasticity (and with that: a form of fake consciousness) is only present during training.
Add to that the fact that a model is being trained actively and the weights are given by humans and the possible realm of outputs is being heavily moderated by an army of faceless low paid workers I don't see any semblance of a brain but a very high maintenance indexing engine sold to the marketing departments of the world as a "brain".
The implementation is not important, its function is. It predicts the most probable next action based on previous observations. It is hypothesized that this is how the brain works as well. You may have an aversion to think of yourself as a predictive automaton, but functionally there is no need to introduce much more than that.
It's still a neural network, like your brain. It lacks plasticity and can't "learn" autonoumously but it's still one step closer in creating an artifical brain
This is a great visualization because original paper on transformers is not very clear and understandable; I tried to read it first and didn't understand so I had to look for other explanations (for example it was unclear for me how multiple tokens are handled).
Also, speaking about transformers: they usually append their output tokens to input and process them again. Can we optimize it, so that we don't need to do the same calculations with same input tokens?
This is a phenomenal visualisation. I wish I saw this when I was trying to wrap my head around transformers a while ago. This would have made it so much easier.
Same here. I blame the popularity of Next.js. More and more of the web is slowly becoming more broken on Firefox on Linux, all with the same tired error: "Application error: a client-side exception has occurred"
Next.js was never really broken for Firefox for Linux in my experience.
Through some "hidden" settings, disabling JS, and proably quite many plugins can brake things.
The only thing which tends to be often "broken" for FF in my experience is often CORS and Mic/Camera APIs, ironically in case of CORS 100% because of bugs in non standard compliant websites and for Mic/Camera it's more complicated but most common websites simply refusing to work with FF without even trying (and if you trick them into believing it's no FF often working just fine...).
This shows how the individual weights and vectors work but unless I’m missing something doesn’t quite illustrate yet how higher order vectors are created at the sentence and paragraph level. This might be an emergent property within this system though so it’s hard to “illustrate”. how all of this ends up with a world simulation needs to be understood better and I hope this advances further.
Thanks, I assumed that was the case, but they didn't make that explicit. Then the question is, is the world simulation running at the highest order attention layer or is it an emergent property of the interaction cycle between the attention layers.
I've wondered for a while if as LLM usage matures, there will be an effort to optimize hotspots like what happened with VMs, or auto indexed like in relational DBs. I'm sure there are common data paths which get more usage, which could somehow be prioritized, either through pre-processing or dynamically, helping speed up inference.
This does an amazing job of showing the difference in complexity between the different models. Click on GPT-3 and you should be able to see all 4 models side-by-side. GPT-3 is a monster compared to nano-gpt.
Very cool. The explanations of what each part is doing is really insightful.
And I especially like how the scale jumps when you move from e.g. Nano all the way to GPT-3 ....
Honestly reading the pytorch implementation of minGTP is a lot more informative than an inscrutable 3d rendering. It's a well commended and pedagogical implementation. I applaud the intention, and it looks slick, but I'm not sure it really conveys information in an efficient way.
I feel like visualizations like this are what is missing from univeristy curricula. Now imagine a professor going trough each animation describing exactly what is happening, I am pretty sure students would get a much more in-depth understanding!
Isn't it amazing that a random person on the internet can produce free educational content that trumps university courses? With all the resources and expertise that universities have, why do they get shown up all the time? Do they just not know how to educate?
It's an incentives problem. At research universities, promotion is contingent on research output, and teaching is often seen as a distraction. At so-called teaching universities, promotion (or even survival) is mainly contingent on throughput, and not measures of pedagogical outcome.
If you are a teaching faculty at a university, it is against your own interests to invest time to develop novel teaching materials. The exception might be writing textbooks, which can be monetized, but typically are a net-negative endeavor.
Unfortunately, this is a problem throughout our various economies, at this point.
Professionalization of management with its easy over-reliance on the simplification of the quantitative - of "metrics" - along with the scales (size) this allows and manner in which fundamental issues get obscured tends to produce these types of results. This is, of course, well known in business schools and efforts are generally made to ensure graduates are aware of some of the downsides of "the quantitative." Unsurprisingly, over time, there is a kind of "forcing" that tends to drive these systems towards the results like you describe.
It's usually the case that imposition of metrics, optimization, etc. - "mathematical methods" - is quite beneficial at first, but once systems are improved in sensible ways based on insights gained through this, less desirable behavior begins to occur. Multiple factors including basic human psychology factor into this ... which I think is getting beyond the scope of what's reasonable to include in this comment.
Have you considered the considerably greater breadth of content required for a full course, as well as the other responsibilities of the people teaching them such as testing, public speaking, etc.
This is the result of a single person on the internet, who was not chosen randomly. it's not a fair characterization to call this the product of some random person on the internet. You can't just choose anyone on the internet at random and get results this good.
Also, according to his home page, Mr. Bycroft earned a BSc in Mathematics and Physics from the University of Canterbury in 2012. It's true that this page isn't the direct result of a professor or a university course, and it's also true that it's not a completely separate thing. It seems clear that his university education had a big role to play in creating this.
I second the reply about incentives. Funding curriculum materials and professional curriculum development is often seen as more of a K-12 thing. There is not even enough at the vocational level.
If big competitive grants and competitive salaries went to people with demonstrated ability like the engineer of this viz, there would be less stem dropouts in colleges and more summer learning! Also, in technical trades like green construction, solar, hvac, building retrofits, data center operations and the like, people would get farther and it would be a more diverse bunch.
You're betting on the hundreds of top university cs professors to produce better content than the hundreds of thousands of industry veterans or hobbyists...
Why does YouTube sometimes have better content than professionally produced media? It's a really long tail of creators and educators
This isn't new. Textbooks exist for the same reason, so we don't need to duplicate effort creating teaching materials and can have a kind of accepted core cirriculum.
Because Faculty are generally paid very poorly, have many courses to teach, and what takes up more and more of their time are the broken bureaucratic systems they have to deal with.
Add that at research universities, they have to do research.
Also add in that at many schools, way too many students are just there to clock in, clock out and get a piece of paper that says they did it. Way too few are there to actually get an education. This has very real consequences on the moral of the instructors. When your students don't care, it's very hard for you to care. If your students aren't willing to work hard, why are you willing to work hard? Because you're paid so well?
I know plenty of instructors who would love to do things like this, but when are they going too? When are they going to find the time to learn the skills necessary to build an interactive web app? You think everyone outside of comp sci and like disciplines just naturally know how to build these types of apps?
I could go on, but the tl;dr of it is: Educators are over worked, underpaid and don't have enough time in the day.
{kind=link}
For those reading it and going through each step, if by chance you get stuck on why 48 elements are in the first array, please refer to the model.py on minGPT [1]
It's an architectural decision that it will be great to mention in the article since people without too much context might lose it
[1] https://github.com/karpathy/minGPT/blob/master/mingpt/model....