This is an excellent tool to realize how an LLM actually works from the ground up!
For those reading it and going through each step, if by chance you get stuck on why 48 elements are in the first array, please refer to the model.py on minGPT [1]
It's an architectural decision that it will be great to mention in the article since people without too much context might lose it
Wow, I love the interactive wizzing around and the animation, very neat! Way more explanations should work like this.
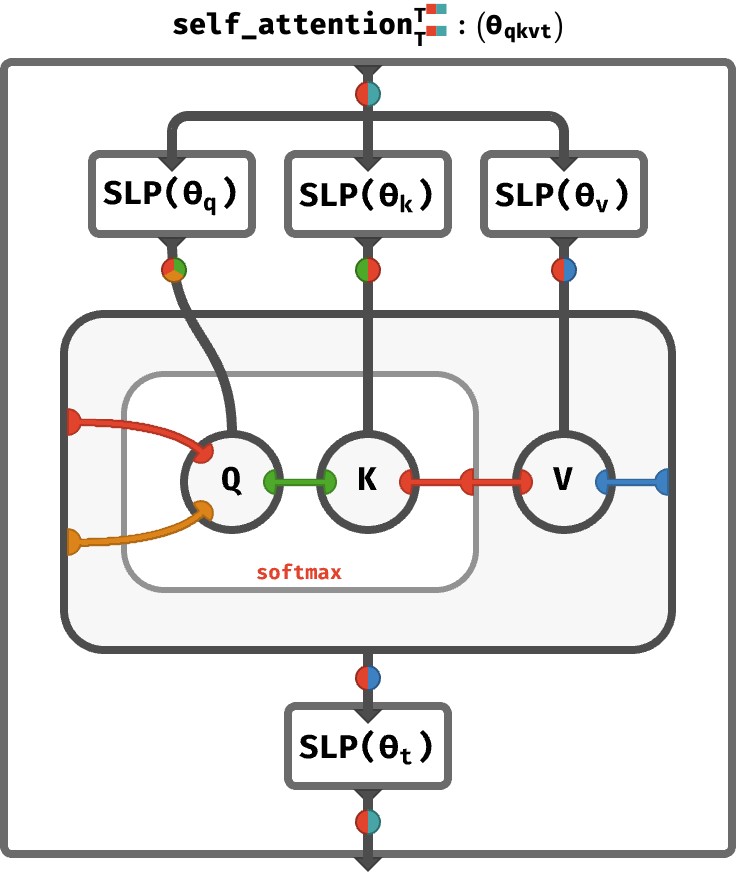
I've recently finished an unorthodox kind of visualization / explanation of transformers. It's sadly not interactive, but it does have some maybe unique strengths.
First, it gives array axis semantic names, represented in the diagrams as colors (which this post also uses). So sequence axis is red, key feature dimension is green, multihead axis is orange, etc. This helps you show quite complicated array circuits and get an immediate feeling for what is going on and how different arrays are being combined with each-other. Here's a pic of the the full multihead self-attention step for example:
It also uses a kind of generalization tensor network diagrammatic notation -- if anyone remembers Penrose's tensor notation, it's like that but enriched with colors and some other ideas. Underneath these diagrams are string diagrams in a particular category, though you don't need to know (nor do I even explain that!).
Are you referring specifically to line 141, which sets the number of embedding elements for gpt-nano to 48? That also seems to correspond to the Channel size C referenced in the explanation text?
That matches the name of default model selected in the right pane, "nano-gpt". I missed the "bigger picture" at first before I noticed the other models in the right pane header.
{kind=link}
For those reading it and going through each step, if by chance you get stuck on why 48 elements are in the first array, please refer to the model.py on minGPT [1]
It's an architectural decision that it will be great to mention in the article since people without too much context might lose it
[1] https://github.com/karpathy/minGPT/blob/master/mingpt/model....