> is that for a long time it was the only viable configuration format
Actually, this is not the case. We had INI format for simple stuff and XML (protected with entire schema) for complex things many years ago, which worked. Yet, we wanted something readable (like INI), but able to express complex types (XML).
I don't think Toml is a viable replacement - for me, it has an INI-level of simplicity with even worst hacks to have nested structures. But, give it time and you'll have another YAML.
But yes, YAML is confusing for edge cases (true/false, quoting), but I'm going to find a powerful replacement that is not XML. Maybe EDN can jump in, but for anything more complex, I'd rather have a Lisp interpreter and structures around than any of mentioned and upcoming formats.
Thinking that JSON is a suitable replacement, imagine writing Ansible or k8s stuff in it; that would be fun ;)
> Thinking that JSON is a suitable replacement, imagine writing Ansible or k8s stuff in it; that would be fun ;)
Writing in YAML doesn't feel much better. YMMV but I've been on teams using Pulumi for k8s and the developer experience has been significantly better. I can automate, type check, lint, click through to definitions the same way I do with other typescript.
Pulumi is a young product with many rough edges but it's already been a game changer for me.
"Comments":
{
"Name": "This is the name of the customer",
"Age": "This is the age (0 to 1000) of the customer"
}
or
"Values":
[
{"Name":"Age", "Value":"20", "Comment":"This is the age of the customer"},
{"Name":"Name", "Value":"Mr. Foo Bar", "Comment":"This is the name of the customer"}
]
... just fucking don't, generate config in your configuration management tool of choice and then serialize it to YAML. You get all of the advantages (nice to read)and none of the disadvantages (need editor or it is PITA)
That is actually only the case for yaml 1.1; the 1.2 spec (circa 2009!) eliminated this forest of boolean encodings, leaving only `true` and `false`: https://yaml.org/spec/1.2.0/#id2602744
If you aim to be "human-friendly" (and that is, as I understand, the raison d'etre for YAML), there is a subtle semantic difference between "true" and "on" (and "false" and "off") and as a human it may be nice to express that semantic difference.
As for that semantic difference, if we expect the light source to have one of exactly two states (that is, "not a dimmable light"), we probably want to express that as "lightsource: on" rather than "lightsource: true".
And that is where the friction between "humanfriendly" and "computer-friendly" starts being problematic. Computer-to-computer protocols should be painfully strict and non-ambiguous, human-to-computer should be as adapted as they can to humans, erring on "expressive" rather than "strict".
I am also not sure if I am happy or sad that the set of configuration languages in the original article didn't include Flabbergast[1], which was heavily inspired by what may be simultaneously the best and worst configuration language I have seen, BCL (a language that I once was very relieved to never have to see again, and nine months later missed so INCREDIBLY much, because all the other ones are sadly more horrible).
Its something of a tradeoff space that is always there you either have things that look the same be implicit (eg is 1 and 10000000 the same type? How about 1 and 1. ? How about 1 and -1?, how about 1 and moo? 1e2 and 1f2?
You can have things be explicit and verbose (have explicit unambiguous identifiers on every value), or you can have things magic and then surprising in something like this.
Rails also made a similar decision to basically auto convert what would be the string true to the Boolean value true in many cases. It's not obviously right or wrong, it's just a choice that has tradeoffs.
I think my own sensibility is that it's actually reasonable for something like yaml to allow you to choose to omit quotes and if you do then it's automatic typing: 1e2 is a number and 1z2 is a string. If you want it to be a string you can put quotes on every value if you want, exactly like you would in json, choosing unquoted for things that are strings is choosing the automatic typing case.
But these other values like y and n being autotyped as bool are suspect autotype behavior to me: even once you've accepted unquoted is autotyped you are more likely to be caught off guard by this than by 0 vs true vs 0z.
I'm nose deep in an Oracle to Postgres conversion at the moment and from that experience, among others, I can absolutely assure you that although booleans are definitely simple they are also most definitely a very sharp edge case.
It does. If I define struct to contain boolean, Go yaml parser will always parse it to boolean
If I define it as any other type, it will parse it as that type. So any conflicts like in the article just don't happen, or at worst, produce error in parsing.
Static typing in this case acts essentially as schema
XML did everything and it's perfectly readable if it's formatted and structured well. This zoo of different markup/object/whatever languages we have to deal with now is largely a mistake.
This is confusing because XML is the archetype of what I would consider unreadable. If I got a prompt in a programming language design workshop to intentionally design something unreadable for humans, I would start thinking about XML and see where it leads me. Can you name any language any more unreadable than XML to help me?
I look at this and I see a visually-well-organized hierarchy of objects with properties and children. It's a sideways tree diagram. I honestly don't get what's supposed to be unappealing about it.
> Can you name any language any more unreadable than XML to help me?
Most of the other markup languages depending on the usecase. The "redundant" tags everywhere like </Address> in XML are very helpful if you're in the weeds of a big document that's taller than your viewport - you still know exactly what you're looking at and where in the hierarchy you are, as opposed to JSON or YAML which I find much easier to get lost in.
Anyone can pick up a (properly-named) XML document and tell what it means at a glance, but JSON is easily a mystery unless you know the implicit schema beforehand.
Maybe there's some minor friction to get past looking at XML because it's a little visually busy before you learn how to parse it out? Is that all there is to it?
I understand where you’re coming from because it’s true XML is going to perform the functions required without all the problems implicit with YAML’s “readable” syntax…
But I have worked with some very complex XML and I feel you’ve chosen a simpler to read example.
I have seen very complicated XML from Microsoft’s own configurations that is so large, long, and complicated that it is very hard to follow
XML is a mistake. 80% of every XML document is just redundant noise because the IBM lawyer who invented the SGML syntax had never heard of S-expression.
The "redundant" noise makes it more human-readable in my opinion. If you're in the weeds of a big XML document that's larger than your viewport, being able to see that you're at the end of a </Address> helps you keep your place, as opposed to something like JSON which I find much easier to get lost in. Even if it's not that big I appreciate the extra rails on the XML making it easier to keep my place.
I consider this a fallacy. The condition you are given is not a common occurence. In the event they do occur, the solution can be found in your editor or viewer. It does not make sense to inject spurious junk into what is designed as a data interchange format, in which includes network information interchange.
There's probably a name for this kind of fallacy that exaggerate the effect of a problem and the resulting contortions that were engineered around it.
Writing documents with S-exprs will get very tedious once you have to deal with stuff like whitespace and such that will inevitably show up when you're dealing with text documents. SGML is specifically optimized for those use cases, which is why it is so much more awkward to use when all you want is serializing some random structured data.
We are talking about a configuration language here, which is never about markups. Also, most of the so-called whitespace problem in Ansible or k8 configs comes from embedding config that's not YAML. In these cases you need a path or URI for the processor to resolve before applying, not inverting the entire configuration language to cater to 1 uncommon use case.
The point of my original comment was precisely that SGML was optimized for text documents. I agree that adopting it for configs was a mistake, but the complaint that "IBM lawyer who invented the SGML syntax had never heard of S-expression" doesn't make any sense in that context.
What XML replaced was a combination of custom designed (often binary) formats and HTTP query-string like syntaxes. It is quite verbose compared to either of them, and explodes both your bandwidth and serialize/deserialize times, but it is arguably easier for your new co-worker to guess that the address line 2 goes in <address2>...</address2> rather than prefix tagged with 13, or worse yet at offset 42-61.
I got used to XML, tho I never could quite understand XSLT and the desire to program in it. I got used to json, but yaml I just can't bring myself to parse. YAML is 90% stuff you can't guess and just 10% data. And why so many?
> Thinking that JSON is a suitable replacement, imagine writing Ansible or k8s stuff in it; that would be fun ;)
k8s via helm is often templated via go template strings; which works by creating an unreadable and unhighightable mess, introducing lots of its own bugs.
INI has no spec, and there are many variations all slightly incompatible with each other, kinda like Markdown. YAML is really the only sane configuration language that lets you denote nested structures while keeping them look nested.
Basically, all of the problem identified in the article can be dealt with 1 rule - always quote your strings. I agree with the author we should have reduced, safe and minimalist subset of yaml, which is basically YAML 1.2, released in 2009.
There's HOCON which is pretty good if you can run on a JVM. It's a superset of JSON designed for readability and human-friendliness when writing config files. It doesn't change the type system and doesn't have yamls weird edge cases, but is still a lot easier to write than JSON. There's also a relatively tight spec.
I second that. And if people need to deal with YAML in Python, they should be using ruamel.yaml, which is a far superior library on just about every level: https://pypi.org/project/ruamel.yaml/
Why would I care that the maintainer prefers Mercurial? The document you linked to doesn't say anything about them not taking community submissions: I think you need to scroll down further in the page. And it certainly doesn't say that you have to use SO to submit changes.
Although yaml 1.2 is more than 10 years old by now, you would be mistaken to think that it is widely supported: the latest version libyaml at the time of writing (which is used among others by PyYAML) implements yaml 1.1 and parses 22:22 as 1342.
Cue is interesting, but why is it only available as a command-line tool rather than a library? I'd want to integrate such a configuration language in my programs, so I could use its evaluation and validation capabilities rather than writing a custom parser/validator.
Also their website is terrible. One of those projects that assumes you've already decided (or been forced) to use it and have cleared out a week of your schedule to learn how to use it.
I learned cue from it during one weekend with plenty of time to play with kids, using it in production since 2020, it's been absolutely great, zero problems, very terse configs, intuitive formalism.
I took another look and eventually found the bit of the website that they should put front and centre in the Tutorial page. Still difficult to navigate (why doesn't the page tree show up on the left?) but it is at least well written and to the point.
The "learn more" button on the front page should link to that, perhaps with a single paragraph giving motivation.
And the main page breaks the fundamental rule of programming languages/formats. Put examples on the front page!
I assumed they hadn't done that because the examples would be too complex or maybe the concepts were too difficult to demonstrate with small examples but having gone through the tutorial that isn't there case at all.
I find specs nearly unreadable when trying to first digest a language; While invaluable for advanced usage and implementation, I can't read a BNF-Style Spec and make heads or tails of what's going on unless I also have an annotated example next to it.
No. XML is broken for structured data that isn't HTML because it's not really clear (there aren't even "best practices" afaict) what should be a text node, what should be an attribute node, and what should be a subtag node.
It's not like other formats don't face similar questions. E.g. if you have a list of key-value pairs to serialize to JSON, do you translate those keys to JSON properties in an object, or do you translate each pair as an object in an array?
The motivation for doing that in JSON comes with best practices: you use the key-value objects thing if and only if you have an ad-hoc list of items that you'd really really like to shove into a well-typed schema.
My distaste for yaml led me to attempt just that. The first piece that was missing for me was a python parser that could produce reasonable error messages and could be transformed into the desired internal representation in python. So I wrote one [0]. It was supposed to be a single file that was less than 100 lines and could be copied and pasted into any project that I needed. Turns out that the issue was a bit more complex.
The issue is that there is sufficient complexity in finding a portable representation for configuration formats that it just kicks the can down the road. On the other hand it means that as soon as you decide what format you are going to support you can quickly implement it. There is more or less a intersectional grammar that works across most if not all lisps, and that is the plist `(:k v :k2 (:k3 v2))`. So I settled on that for my own use.
After all that work I have not dealt with the fact that numbers and chars do not have a portable representation across lisp dialects, which is a key complaint in other threads here. Limited support for let binding constants also seems like a feature that would
allow for just enough expressivity to make the format useful without opening up the terror that is `&` and `*` in yaml (cool and useful as it may be).
In summary s-expressions are:
1. missing good parsers in a number of language ecosystems
2. not standard across lisp dialects
3. need additional semantics for binding, multiple expressions, etc.
4. still better than yaml and json
I know what s-expressions are, vaguely. Vaguely in terms of "I couldn't write a grammar for them off the top of my head.", that is, not "what are they".
Is there a single agreed-upon defined grammar that everyone can use? Preferably one simple enough that like JSON's it is at least capable of being used as a graphic on the home page for the format? https://www.json.org/json-en.html
This is an honest question, because there may well be and I don't know it.
However, I will put this marker down in advance: If multiple people jump up to say "oh, yes, of course, it's right here", and their answers are not 100% compatible with each other, then the answer is no.
The other marker I'll put down is "just use common lisp", I want verification that it really is 100% standardized, no question what any construct means, ever, and I still bet we get people who would rather see Scheme or Clojure, and I bet there's some sort of difference.
Neither of these objections is fatal to the idea. JSON is technically not just "javascript objects", so if someone carved out a defined format from s-expressions, then held it up as a standard, that would be as valid as what Crockford did. But at least as of right now, I'm not aware of anyone having done that standardization work. Replies welcome.
I don't see a grammar I could use for an external standard there. I could be missing it. And I assume there must be one implied, since it appears to be a read-write format. However such things have a nasty habit of turning out upon further inspection to not be as generic as supposed and have local idioms buried in them, often in surprising places. Even JSON, simple as it is, had that problem, and it is after all a subset in an attempt to squeeze out those localisms.
Is it compatible with Common Lisp, such that all such s-expressions will be compatible with it in some natural way?
Along with the many other issues that would have for just straight-up not being a usable grammar, the word "CUSTOM" appearing in a nominal cross language standard is a non-starter.
Oh come on. Did you think anybody would write an RFC in the comments? Add arbitrary list of whitespace tokens everywhere and pick whatever favorite grammar you have for literals. Json strings and numbers since you seem to like them.
Of course not. But you are at least semi-seriously trying to propose something. I promise you it won't be that easy to get any sort of agreement.
This is a classic "oh come on how hard can it be" that, once you get into it, it turns out the answer is very. Arbitrarily so. Agreement is hard. Details are hard. A standard with no details is not terribly different from "just give us some text".
I've never met anyone who say's "I like YAML, it is great"... most people that worked with it say something like "YAML is annoying, I don't like it"...
While introducing Kubernetes at our company in the last two years, we are currently in a process going more and more away from YAML with internal Helm charts to a much simpler process by just using HCL and Terraform, and defining Kuberentes resources as Terraform resources.
As a software developer HCL just makes so much more sense than this YAML + Helm + Go templates hell, which feels like C preprocessor hell all over again. Other solutions like kustomize are neat, but I don't see how all of these YAML workarounds should be better than something like HCL with Terraform. HCL feels like a real declarative programming language (with real conditions, variables, a module system and useful built-in functions). YAML feels like another more complex JSON and other tools like Helm or Kustomize try to work around the weaknesses of YAML with some kind of templating system.
YAML looks nice to read in simple demos and in small files, but is just not adequate in the real world (in my personal opinion - I know that YAML is used by a lot of people in production as of today).
> I've never met anyone who say's "I like YAML, it is great"
Maybe I'm older than you, but I have definitely heard that line.
Mostly because the alternatives were XML, INI or the myriad of bespoke formats, relayd/apachehttpd .conf or iptables etc;etc;
INI has parsers that operate in different ways and doesn't support heirarchies... so that's not ideal.
JSON and YAML came to the fore around the same time, and JSONs limitations in comments and it's picky semantics meant that people did prefer YAML over JSON for human readable configs.
YAML itself is fine, it has some really awkward warts and the parsers are usually programatically unsafe in their implementation (leading to less compatible "safe_load" or other types of loaders)[0]; the issue we actually have with YAML is that we:
A) Template it (jinja, mustache whatever)
B) Put entirely too much stuff into it. (kubernetes manfiests can grow to the hundreds of lines really easily)
These problems will affect any configuration file format we choose to use, including TOML (which is comparatively new on the block), because reading templated/enormous files is really difficult.
What I've taken to doing is programatically generating objects and then serialising them as whatever my software depends on. It might feel ugly to use an entire turing complete language to generate objects that are mostly static: but honestly... the ability to breakpoint, test and print the subsections of output is astonishingly nice.
The tooling is super mature, it's easy to emit, it's easy to parse, it's easy to validate, it can just a little hard to read and write by hand (and I mostly blame SOAP for that). Still, basic XML isn't that hard to read or write, thanks to editor support.
I like that you can use anchors and merges. It greatly simplifies complex, repetive structures. And most of the complaints about yaml can be worked around by string-quoting.
The whitespace can get in the way if you're templating, but then you can also use [1, 2, 3] as a list notation, for example.
In fact, most of the complaints could be resolved by running it through a linter.
I like YAML. More specifically, the subset of YAML, like the author suggests. Clear, intuitive, and allows expressing of complex data structures like JSON does. Much better than TOML, which easily becomes a mess with more complex data.
Yup exactly my experience as well, again a stupid idea to try and make a "configuration" language out of nested key value pairs that end up needing fancy interpreters allowing more and more semantic into the keys and values to start doing what a simple program could have done in half the time...
I ve worked in 4 companies over a period of 10 years, each had exactly this problem, with yml, json, xml, properties file (you dont want to see business logic conditionals in a properties text file, where the keys shapes command an interpreter to behave dynamically...)
The only times I saw a team do it well was a php backend of all things where the lead said they d program all their variations in php rather than source it from configuration flat descriptors and it was amazing, clear, simple and powerful. They had to release the backend at each config change instead of releasing the config change only, but Im still unsure why exactly that's a problem: the configs are software too if we re honest with ourselves, shoe-horning them in a descriptor language isnt gonna make them flat.
I don't think YAML is great, but I still think it's the best format out there.
The only confusing problem I've run into was the sexagesimal number notation and even that was fairly obvious. Perhaps it's because I tend to overquote strings?
I mean sure, the on/off to boolean mappings are annoying, but they also become very obvious when you're parsing config because the type validation will fail. If `flush_cache` has an enum `on` but no key `True` then the type validator will instantly complain about both the missing key and the extra key in the dictionary.
Same with accidental numbers, any type check will show that the parsing failed.
I find JSON for config files to become unreadable quickly because of the non-obvious nesting and the lack of comments. You can pick a JSON extension but then you need to pick one that your tooling will support.
Exactly this. I hear so many people recommend TOML over YAML.
I see the logic in it. For simple Key-value configurations, TOML is superior and more straightforward to YAML. You can add sub-level values and it isn't too bad (if there aren't too many), but beyond two levels, TOML becomes difficult to use.
If you really work in YAML in any sort of more advanced capacity (kubernetes, Ansible, CI/CD Pipelines) then you really need the complexity that YAML provides. You also get used to the "gotchas" mentioned here. Navigating them is fairly straightfoward.
I think the article was vastly overblown. Is YAML perfect? Certainly not. But you find a better way to display such complex data structures in a more human-readable and human-writable way. The complexity is YAML's strength, but it comes with caveats as all complexity generally does. I really think its the best we have.
I think problem in this particular case is using YAML as DSL. Every other data format would be equally bad here. Replace YAML with TOML and you're still in same templating hell.
YAML is least worst for me, and I don't think I ever hit the problems article is showing because
* I use editor that will highlight stuff like anchors
* I often generate config from CM so it can't have those errors
* Loading into defined struct in statically typed language also makes them impossible.
YAML is nuts, and JSON is annoying (trailing comma limitations, lack of comment syntax no matter how annoying it is that the spec is correct about why there are no comments).
Both have their place though. YAML came out of perl, and both are some confluence between awesome and horriffic (although yaml wins the horrific crown for sure).
I've had a little bit to do with Ingy - the inventor of yaml, and I've worked closely with some of his collaborators. Ingy is nuts, mostly in a good way, but I wouldn't put him in charge of the architecture, I'd put him in charge of the abyss.
Though, in fairness, I think old Perl did that too. It's super convenient until it isn't.
Rachel also doesn't approve of JSON in high-reliability systems for other reasons: https://rachelbythebay.com/w/2019/07/21/reliability/ and point taken, if you're sending data from your service A to your service B and neither is a web browser, nor are they written in JS, then there's far better formats and you almost need a reason not to use protobuf.
There was (I think probably still is) a qemu bug with JSON. It accepted requests to read guest memory in JSON format, with the memory addresses encoded as JSON numbers.
When reading out guest kernel memory (addresses are at the top of 64 bit space) these would silently be rounded to the nearest whole double. It took me a very long time to understand what was going on.
Actually JSON doesn't specify what numbers are - it would be perfectly licit for a JSON parser to transparently use a real numerical tower, allowing perfect representations of any non-repeating decimal fractional number (since it has to be represented as a dotted-fraction and there's no support for a vinculum (aka U+0305 / COMBINING OVERLINE / ◌̅ / 3.21̅) there's no way to represent non-repeating fractions if there is not a non-repeating representation in base 10). A few JSON parsers even do this. That said, if you don't control the both sides sending something that won't be handled by the lowest-common-denominator (browser JSON parsers / JS numbers) is asking for trouble.
This is a great post but my understanding is this has nothing to do with JSON, which is unopinionated about numbers. Rather, with JS's JSON parser.
Python, for example, has several JSON libraries which let you swap out the numeric parser so it yields Decimal objects all the time. It's overkill for most use cases, but essential if you're working with REST APIs in Fintech.
JSON doesn't specify what numbers are. Integers that take 2MB to represent are valid JSON numbers.
Regarding protobuf, the following opinion is obviously insane, and if your org is already using protobuf you should ignore it: protobuf actually seems pretty bad? It has a bunch of vestigial features that people just say not to use. Its integer encoding bloats the encoded size and causes unnecessary dependency chains in the decoder. I would strongly prefer sending simdjson tape between processes and storing simdjson tape at rest, but if my coworkers insisted on doing something normal, maybe I would look into flatbuffers or capnproto.
YAML used from withing statically typed language gets rid of most of the problem, but the main one seems to be "well, we figured out which stuff was just a bad idea and put it in 1.2, except nobody uses it"
> Both have their place though. YAML came out of perl, and both are some confluence between awesome and horriffic (although yaml wins the horrific crown for sure).
Weirdly enough I'm not getting most of those issues in Perl YAML, "norway problem" for example
use Data::Dumper;
use YAML;
my $a ="---
geoblock_regions:
- dk
- fi
- is
- no
- se
";
print Dumper(Load($a));
$VAR1 = {
'geoblock_regions' => [
'dk',
'fi',
'is',
'no',
'se'
]
};
This reminds me of a certain architect at my last shop who invented a DSL on top of his Python superapp. He expected all projects to go through his superapp. The DSL was configured in YAML. The YAML was often so dense he recommended devs use Jinja to generate the YAML.
This meant debug was hell, plus it wasn't always clear if what you were trying to do was even supported / if not why & what needed to be changed. This was because you were now 3 levels of abstraction away from the Python code that was actually executing.
Every time a dev took on a new project they had to jump on a call with architect or right hand man to figure out if what they were trying to do was going to be possible.
It escalated into the architect demanding to know a sprint in advance any task devs were trying to do, in a review session, so he could explain if it was possible or not and try to triage in his DSL..
>The DSL was configured in YAML. The YAML was often so dense he recommended devs use Jinja to generate the YAML.
Did he then went on to design Ansible ? It falls into same trap
Only way you should be generating data format using language's templating system is
<%= YAML.dump(@config) %>
Also 9 times out of 10 I wished the app designer just used <app language> or <any common embeddable language> (like Lua) instead of making any kind of DSL (whether that's just data file pretending to be code or micro programming language)
Yes.
I think this is like the uncanny valley of development.
It's not no-code UI driven stuff you can put in front of a business user.
It's not real coding, which an engineer wants to do.
It's config jockeying, which devs find boring, and is generally far more limited. So you end up building out more and more complex layers of config to work around the limits, including scripts to generate config.. etc.
Seems like what you really want is modular apps that are easy to extend in the native programming language(s).
Also maybe I'm just stupid, but 9 out of 10 times, a text file or csv/demitted file accomplishes most of what you need for pure config that really belongs in config.
This is basically how I feel about working with K8S and dredging through a repo full of templated YAML spaghetti. What am I looking at now? Helm, Keda, Flux, Argo, OperatorHub, GitHub Actions? oh actually this bit is in Terraform in another folder, whoops.
You can’t actually deploy something unless you can mentally untangle it all, it just sits in front of your infra as a sort of DevOps Coming of Age ritual, where you look whistfully over your shoulder at the old Heroku or Vercel account you grew up with. Simpler times.
At work someone is trying to introduce a system where a bunch of Jinja templates in a repository are used to generate XML which can then be used to generate another XML document which can then be "executed", resulting in an annotated XML document :)
I've read about places that do this kind of stuff. Although it sounds like pure hell, I'm sure there's always a reasonable explanation, an intent. What kinds of problems was the org facing that led to the development of this?
It wasn't really necessary.
It also made the core superapp a blocker of essentially every user delivery.
If it has to do everything, then you have to add a lot of features to it.
So you have N devs doing jinja/yaml/dsl and N/4 doing core superapp underlying dev.
For the first Z features/projects, you inevitably see new things that your superapp doesn't support yet, and becomes emergent blockers midway through implementation.
Given the ratio of devs, new blockers were being generated faster than they could be cleared.
Eventually business side pulled the fire alarm and grabbed most of the devs over to use a more common AWS-centric service directly and exit the superapp dev use completely.
IE - if you are going to depend on something, would you rather it be an AWS service with 10s-100s of dev-years behind it, or some internal superapp spun up 3 months ago with 2 guys on it? Which is more likely to already support what you need?
I guess YAML has a place in that it would prevent that kind of thing happening in the first place.
YAML is easy to debug (thanks to having comment syntax) because it just deserialises into code. Sometimes it deserialises into code that compiles on the fly mind you which is never a good idea.
On the other hand one time I debugged a really nasty memory leak by dumping many megabytes of YAML then running git diff against the dumps. That was fun. Of course the client used the quick and bad hack rather than the demonstrably correct fix (thanks to the dumps) because they were frightened of their own code.
That sounds like a layer of insanity that would make me consider jobs elsewhere. It sounds entirely unnecessary and burdensome , but was it unnecessary?
It was unnecessary because he was being too clever & having a good time, versus ever having delivered real production systems in our industry.
It also put devs on a dead end path which they realized pretty quickly.
Do you want to work for years on this team becoming experts in jinja to yaml to in-house DSL you'll never use anywhere else? Or do you want to write some python? If you can't get "promoted" into the team writing the core python engine, then you are obviously a second rate.. why stay?
Less technical management hires a hero who tells them everything they want to hear!
"I'm going to deliver the superapp, everything will be super centralized & tidy.. small dev team, then all the specific implementations will be grunt work by cheap devs!"
Throw in some buzzwords and they are sold.
Same audience that always signs the checks for no code/low code stuff no one actually wants.
> lack of comment syntax no matter how annoying it is that the spec is correct about why there are no comments
This completely arbitrary ideological purity has come at the expense of countless wasted hours, headaches, and suboptimal workarounds like using strings as comments, with zero tangible benefit - zero bad things would have ever happened if JSON allowed comments. There is nothing correct about it.
Is this the same Ingy that made Test::Base? It's the best data-driven testing framework I've ever used, and I've missed it often while working with other languages. The follow-up polyglot framework just didn't cut it for me.
Do people dislike TOML only because it looks like a Windows INI file? I think it’s nice. Rust chose it in keeping with their penchant for sanity most of the time.
I would prefer if logically nested blocks could also be phyisically nested (and indented), so you can have a full tree structure. If you're describing something that can have variable levels of nesting (think folders) then it can sometimes make the format easier to understand.
I like YAML for reading and TOML is entirely worse for reading (still million times better than JSON tho), and as the use cases are mostly read, rarely written, and if written they are code-generated (using configuration management), YAML fits better.
I never could understand the hate XML got, but I'm having a bit of schadenfreude seeing what people suffer through with its replacements.
An XML document with a well-thought-out domain-specific DTD would solve all these problems; instead, we have something where no sometimes means false (but not always) and 22:22 sometimes means 1342 (but not always!)... because... why not?!?
All that horrible mess, it seems, because people didn't like to have to close tags.
Our industry has the remarkable properties of being almost entirely newbies, a constant churn of green developers, combined with being very bad about passing down generational knowledge. This is why things that are easier to explain win out over things that are technically superior but take longer to get your head around almost every time.
The thing JSON had going for it over XML is that it maps cleanly to most languages object models so you can read the results directly. No writing XQueries or DOMs to read values.
It’s only major downfall is lack of comments, which has lead people to YAML. (There’s plenty of other things it lacks in comparison to XML, like native schemas, but most of that falls into things newbies don’t know they want)
YAML is in this weird middle place where it’s easy to explain but impossible for a human to master. It appears as simple as JSON to newcomers who adopt it, but the long time users of it find it full of foot guns. People wanted JSON with comments but instead they got the complexity of XML minus the clarity.
Of course some of the hate come from the application where XML was used, more than XML itself, but it also is a deeply flawed language.
Nowadays the main issue would be that it requires a complex generator and parser libraries to be any useful (you'll never want to deal with XML parsing/escaping by yourself) yet it's not as efficient as binary formats like protobuff for instance.
That means that anything you'll want to edit by hand or be purely textual and readble will be better done in yaml or json, and anything beyond that can be done in other ways. The need for a single language trying to awkwardly span all the spectrum isn't big.
XML is ok when both the reader and writer are machines, but you still want a text-based format (otherwise I'd just use protobuf) or when maybe you occasinally want to edit by hand but not often.
I think it's the same reason why, although HTML is a great standard, lots of us like writing in Markdown and having something convert that to HTML, despite all the problems when you try and push Markdown further than it was intended.
YAML, as I see it, is trying to be to XML configurations what Markdown is to HTML, with the added bonus of an attempt at a tag/reference system to store object graphs that are not trees. Back in the day of XML-based Spring config files, we had <bean> and <ref bean=...> but as far as I know that's implemented on the Spring layer, it's not a generic property of XML, whereas YAML tries to abstract that into the format itself.
> YAML, as I see it, is trying to be to XML configurations what Markdown is to HTML
Yes, that's probably a good analogy. The big difference though is that if some Markdown fails to parse, nothing really bad happens, while a YAML file that fails to parse can bring a whole system down.
Also, Markdown is a famously ambiguous format; it trades precision for ease of write, and that's fine, mostly.
But in a configuration file, ambiguity is really the opposite of what you want.
I worked with hand editing XML files in the past, and I didn't really have an issue with simple XML files. I actually prefer XML in some cases.
I see your point if you need to edit a complex XML with multiple namespaces mixed together, but a plain XML file can be just as readable as JSON.
Some JSON files can be really hard to edit by hand too. At my current workplace I often have to deal with nested JSON files, where a JSON contains values that are also JSON, but encoded and escaped so that it is difficult to edit.
XML is great for systems to read and write, but utterly abhorrent for humans. It's not just having to close tags. It's content vs attribute confusion, namespacing noise (which are also muddled with attributes), and there's a squint factor incurred by the density of information.
Namespacing is the opposite of noise: it lets different domains coexist with no possible confusion about which is which.
But experience has taught me that trying to explain why XML is great and simple to read and write for humans, to someone who thinks differently, is useless. And so, I won't.
Yet, please accept that some people, like me, really liked it and didn't mind the little quirks in light of all it offered.
It makes sense that explaining why xml is great doesn’t work. Maybe you can convince someone who’s never worked with xml. But if someone has used xml and thinks it’s a bad format based on those experiences, you’ll need to bring _really_ good arguments to let them think it’s a good format anyway.
Just ask yourself: could a comment here convince you that xml is a bad format? If not, why would the opposite work?
I disliked it intensely at first, but over time .. I now see the merit in it. I like XML, especially compared to everything else (that came after). It was possible to clearly define things.
On the same system? I can see that. One thing I've lamented about XML for years is that it's a pain when moving to different systems that have their own namespaces/DTDs.
20-something years of web/app.config is the primary reason why I hate XML. Very, very closely followed by Java ("a DSL for turning XML into stacktraces") and its over complicated ecosystem of xml configurations.
I have worked with Java for over two decades, and your experience does not match mine.
At $work there are only two XML files in each project:
- logback.xml: configuring logging which is usually only done once or twice and is the same for each project.
- pom.xml: Maven config which is mostly autogenerated by IntelliJ when creating a new project. I only add a few lines for new dependencies.
In rare cases I may use some plugins to do specific build operations, but the actual XML is simple. Most of the time is spent on understanding the plugin itself, and not "fighting" XML. Moving this to YAML has no effect on my productivity
All other configuration is either done using YAML, properties or configuration in code (Spring Boot).
I see Spring still has options to use XML configurations, but I don't see any reasons why anyone would do that in 2023. The "new" standard in Spring is configuration by code, which I have done for the last 8 years.
The ecosystem for Java today can not be compared to what it was 10 years ago. If editing XML configurations is still a problem at your workplace, find a new job :-) Either you work with a legacy system that nobody wants to update to the new standards, or you have architects who are stuck.
I remember being excited when XML hit 1.0 (as a new programmer this seemed like a huge advance over things like classic Unix configuration files), and progressively disappointed over the next decade as the promise not only wasn’t delivered on.
The things which killed XML seem to me to be related to the old standards culture: the people involved assumed adoption was inevitable and distracted themselves with increasingly arcane thickets of new standards, with the assumption that someone else would spend time on the “boring” work of building professional-quality tools and documentation or cleaning up usability warts. That other 80% of the work never happened and most people who had a choice moved on.
As a thought experience, imagine if libxml2 had had even a single dedicated developer focused on tracking standards or making usability improvements, instead of training multiple generations of users that XML was slow and hostile to users. Various XML committees’ travel expenses building standards which were never used likely cost more than that. Not leaving XPath frozen around the turn of the century would have helped in so many places.
The other wart I think would have made a surprising difference is the usability disaster around namespaces. So many tool developers forced users to switch between the short namespace:attribute form they used everywhere in the document and the {namespace url}attribute form that resolves to, or forced you to respecify the namespaces on every operation rather than reusing the values the parser had already loaded. Users begrudged that verbosity but they hated it when it meant something silently returned incorrect results because a selector using the document’s own syntax didn’t find the element they could see using those exact values. Absolutely nothing anyone did in the XML world was a better use of time than fixing that would have been since it trained people to think of XML-based tools as a painful, error-prone experience to be avoided — and they did as soon as they could.
I miss the old days of working with XSLT and XPath. A nice way of giving some design touches and filtering/sorting to XML documents. It wasn't perfect but I would take any time over the yaml/json/toml/ini.
I don't know if I'd say I "miss" XSLT and XPath, but yeah, it was fun and powerful at the time. I made some crazy stuff with Cocoon and AxKit that, if you didn't mind the syntax, were actually pretty elegant.
XQuery gives you 90% of XSLT with a syntax that is a superset of XPath. Verbose queries (https://en.wikipedia.org/wiki/FLWOR) are especially nice and readable.
Eh, definitely there's some generational round robin going on. And the "amsterdam problem" in YML is just insanity. But you got to admit, XML has some very low level intrinsic problems
* Schemas violate underlying XML rules all the time, and due to variance in XML parsers, it gets a pass but only on specific configurations. There's no one Holy XML Parser. Leading whitespace in attributes? Sure, why not?! Whitespace sensitive element order? Ooh yeah, lots of it! But try and feed it to libxml and the whole thing collapses - without error handling, mind you, but that's not XML's fault.
* Whitespace agnostic means diffs and merges are element aware, and it's nigh-impossible to estimate the upper compute limit of an element aware diff
* There is NO OFFICIAL WHITESPACE SPEC - so if you try and fix it with normalization and lines, it's going to be different everywhere you go. So you're forced to switch on element aware diff / merge in your VCS, which is a pretty big change, and it's one you have to sell other departments on.
* XML breaking 1NF, which, aka means that XML can have XML inside of XML infinite recursion when playing data format = which breaks so very very many things . . it's actually going against the whole concept of a data hierarchy, which is built in to XML at a low level.
* Sort of riding on that, in order to parse XML you have to eat it element by element, and there's no way to tell when an element is going to end or of it recurses N levels. This makes it computationally expensive. The CAD STEP format has some of this disease - it has to be loaded in its entirety to parse, which can be holy hell with a TB file.
* Yeah sure, namespace hell. No one really figured out a way to fix it. S1000D (XML spec) to this day just denies that XML namespaces ever existed, and I can't really fault their WG for doing that. I can fault them for so many other things, but not that.
The really great thing about xml with XSD is the ability to validate the document really well.
I.e. having content matching regexps, so you can be sure version numbers are always \d+(\.\d+)* and does not have unexpected letters or spaces in it. That date values are in ISO format.
Very useful for APIs to 3rd parties as it now is very easy to catch most errors and provide an useful error message for them without having to code every check.
>> All that horrible mess, it seems, because people didn't like to have to close tags.
If people keep burning their faces off it's not the fault of the flamethrower! If they keep hacking each other's limbs off it's not the fault of the chainsaw! If they keep blowing their houses up it's not the fault of the gas bottles! It's not like we need to accommodate every possible failure mode of the human brain, and make things safe just because the next idiot that comes along is going to cause a catastrophe. It's the idiot's fault that they forget to apply the breaks and take advantage of the failsafes, it's not the responsibility of the system to have the breaks and failsafes where any idiot can find them!
I've head that kind of excuse 0 times, outside of software circles. But of course I'm exaggerating because nobody really suffers because of XML other than the people who use it everyday. Like this once junior dev, for example, who was made to create XML by hand by eyballing an Excel document, just because paying a junior dev salary is easier than getting middle management (and clients) to learn to structure an Excel spreadsheet properly.
Sometimes, just sometimes, you have to design a tool with the way it will actually be used in the real world in mind. And all the rest of the time? Well, all the rest of the time you have to do it that way, too.
> All that horrible mess, it seems, because people didn't like to have to close tags.
The issue isn't that it's bad per-se. The issue is that it's cumbersome to write. When you want to setup and tweak a tool, it gets annoying very quickly having to deal with little errors because you misspelled a closing tag. Maybe you want to test enabling a setting? Typing out 4 characters is so much less friction than the 20 or more (including the < > : / characters) you'd need for an XML config.
* `<?xml ...` something line lost a percentage of people already, etc.
* Essentially XML was a markup language (SGML stripped down), while you can use markup to mark up key-value pairs, it just wasn't designed or optimized for that.
* To the contrary, it also did away with the nice SGML features for that instead of `<tag>value</tag>` one could write `<tag/value/` and the self-closing tags (like `<ol><li> ... <li></ol>` in HTML. For most particularly deep config files self closing tags would have been perfect.
* XML attributes vs substructure was just an awkward choice to give out. I.e. `<myConfig userId="asdf" host="asdfasdf" ...>` vs `<myConfig><userId>asdf</userId><host>asdfasdf</host></myConfig>`.
More so I get the feeling when looking at the XSL, XSLT, etc. mania that a similar pattern was at work as with UML: special interest groups and tooling providers driving the evolution of a standard with their interests in mind and not the interest of users or developers.
Overall XML could have been something like this `<myConfig / <userId/asdf/ <host/asdfasdf/` if it was SGML.
YAML and JSON succeeded because they had a clean and predictable, no-nonsense mapping between encoding and object-model after decoding. Probably we should all switch to an almost-yaml format that does away with the peculiarities, and the FANG companies would have the momentum to make that happen.
I personally would like for HJSON (https://hjson.github.io) to see more adoption, but that train has passed...
It’s more typing but it’s simple typing most people don’t even think about because it’s predictable (not to mention automatic in many editors). I’d take that over the frictional cost of thinking your YAML is done and then having to debug magic data conversion or realize that you left out one character causing something to be parsed completely differently.
Where XML falls down hard is tool usability. There’s still no standard formatter or good validation tool, and things like namespace support is a constant source of friction.
Look, I’m not saying XML is perfect but the worthy criticism is more substantial than closing tags. It’s a very easy convention to learn requiring little thought and I haven’t used an editor which didn’t automate that process since the turn of the century. That’s less cognitive load than having to remember a bunch of context-sensitive rules about YAML’s magic behavior - I’m thinking in particular of people I know who’ve burned hours only realize that they’d missed a character somewhere, forgot to escape one value, or had an indentation issue causing something to be ignored.
The criticisms I would make are more fundamental: the XML data model is different than the most popular data structures and the APIs in most languages are quite cumbersome and can lead to silent data loss (name spacing and selectors). Someone probably could have done an XML5 effort 15 years ago but by now I don’t see that happening.
If I had to rank the options for a configuration language, I’d probably go HCL, TOML, JSONC, JSON, YAML + Prettier + a YAML lint schema, YAML, XML. XML could rise up with better tools but so could a low-magic YAML variant.
> An XML document with a well-thought-out domain-specific DTD would solve all these problems;
But then a YAML document written by disciplined and well-thinking people will also not have these problems.
Any of the complex formats work well when used in the most fitting way and go horribly wrong when people try to benefit too much from the complexity. XML was also a nightmare when put in the wrong hand, just as yaml is, and the next hyped and turing complete document syntax will be.
Ease to use and ease to misuse usually come hand in hand.
If we had very clear and static requirements I’d see languages/tools with more safeguards, fool proofing, optimized design etc. But we’ll never have that for configuration languages, and when aiming for flexibility you have to trust people to not shoot their own feet.
The problem with XML is mainly in the 'M': it's a _markup_ language. Using it for configuration and arbitrary data serialisation isn't where its strengths lie, but it got shoved into those niches because if you look at it _just right_, you can make it work in them.
I don't hate XML myself, but I do hate how it's been abused over the years.
It's because so many people would see examples of complex _XML-based formats (WSDL, SOAP, etc.)_ and infer that _XML itself_ is complicated. XML is really not that difficult to understand, and I find it quite amusing that the same people who don't bat an eye at writing HTML complain about how baffling XML is.
Is writing an XML parser difficult? Yes, very much so. But again, that doesn't make XML itself complicated. And before anyone tries to call out this particular comment, keep in mind that writing a fast, correct, and safe JSON parser is no walk in the park either.
Are there many examples of complicated XML-based formats? Yes, but that's just a reflection of the complexity of some particular configuration model, not XML itself.
XML is cool and useful, but for humans you need good tooling to handle it well. And it still is very noisy with the all it's boilerplate and what advanced features can bring in. And overall it has a culture of making things complex, and complicated.
Just like bad/fragmented YAML libraries now, there were plenty of bad XML libraries and implementations. I didn't think XML was too bad until I had to write a SOAP request where the endpoint would throw an error if the arguments (in their own tags, mind you) weren't in a specific order. The endpoint gave me no hints.
Additionally we had to update WSDLs for these services, but the service generating the WSDL used features our server's SOAP library didn't support, so someone had to manually transform the XML and via lengthy trial and error to get it to work.
I see nothing wrong about closing tag. Helps to navigate and understand in my opinion. I have way more problem with developers trying to be super concise and writing constructs that are very hard to parse mentally when looking at.
I do think YAML is overly complex - but there is some hyperbole in this document.
- Many of these complaints are about YAML 1.1.
- YAML 1.2 was released _14 years ago_.
- The author makes some allusions to 1.2.2, and it requiring a team of people 14 years to make, but, from the yaml.com announcement they link to: “No normative changes from the 1.2.1 revision. YAML 1.2 has not been changed”
I guess my first two comments are undercut by PyYAML using YAML 1.1 (Really?! Python’s had 24 years of the Norway problem?!)
The article mentions the fact that YAML 1.2 is really old and the fact that it doesn't matter because YAML 1.1 is still the most commonly supported version, and the fact that it's arguably even worse because YAML 1.2 gives different parsing results to YAML 1.1!
I highly recommend reading the article - it's very good.
Agree with the final part of this article that "programmable" configuration languages like Nix and Dhall are the way forward.
I've spent a lot of time writing YAML for Ansible, Cloudformation, k8s, Helm, etc. Some of the issues this article mentions are pitfalls but once you get a bit of experience with it, you know what to look out for.
I've also spent and a lot of time writing Nix expressions, which is much more "joyful" IMO. Seemingly simple features like being able to create a function to reuse the same parameterized configuration makes life much easier.
Add in a layer of type safety and some integration with the 'parent' app (think replacements for CloudFormation's !GetAtt or Ansible's handlers), the ability to perform basic unit tests, then configuration becomes more like writing code which I consider a good thing.
I agree. They make a rod for their own back by having implicit conversion rules which, while well defined, are not well understood. "Explicit is better than implicit" and all that.
Great idea. I would also suggest adding some syntax to make lists and maps more obvious (it can be a bit unclear in YAML). Maybe {} for maps and [] for lists.
My wish for a dream config language is this: Allow a choice between unambiguously-typed expressions (quoted strings, only true/false, decimal numbers) and explicit type annotations. So this:
regions: $[string]
- no
- se
options: ${bool}
a: yes
b: no
(with possibly a different syntax) would be equivalent to
It’s really no wonder that it’s hard to create a language that’s supposed to know whether the author intended to write a string or not without it being indicated by the syntax. No other language in the world tries to do this, for exactly the reasons this article points out.
Since everyone seems to throwing their favorite format into the ring (), I will too: EDN [0]
* no enclosing element (i.e., can be streamed)
* maps, lists, even sets
* tags (like "Person". UUIDs and timestamps are built-in tags)
* floating point numbers
* integers
* comments
* UTF-8
* true booleans
* no need to worry about too many or too few commas in the right or wrong place
Implementations in almost every language under the sun [1].
The format is simple enough that it's easy to implement, verify, and test. No strange string interpretation craziness (see YAML and "Norway problem"), no ambiguity between FP and integers (see JSON), comments. And if your editor has rainbow parenthesis support, reading is actually a pleasant experience.
> loading an untrusted yaml document is generally unsafe,
TIL and this is... Not great?
I often parse JSON as YAML. Since YAML is a superset of JSON, all valid JSON files parse as a valid YAML file too, but now you can add comments to your JSON since YAML has comments. Didn't know I was opening my process up to code execution doing this...
Knowing this, YAML is dead to me as a format. This really seems unacceptable for a markup parser.
Pretty much all parsers have some way to "safely" parse a YAML document which disables the custom-object unmarshal stuff; sometimes this is the default, sometimes not, some libraries/languages don't support this at all in the first place.
If it's enabled, then it's trivial to exploit; e.g. in Python:
!!python/object/apply:os.system
args: ['ls /']
If you parse this with "yaml.load()" in PyYAML (which, I believe, is the most commonly used YAML library for Python) then it will execute that code. You will need to use "yaml.safe_load()".
I believe the situation in Ruby is similar, and in PHP the only way to get any safe sane behaviour is to modify a php.ini setting (which at least defaults to "off" now, but there is no way to know if a line is safe just by looking at the code).
In Go this entire feature isn't supported at all AFAIK, so it's always safe.
Not sure about other languages from the top of my head.
I'm not sure it's true that parsing an untrusted YAML document is generally unsafe. That has to be a property of the parser, not the format.
As TFA says:
> In Python, you can avoid this pitfall by using yaml.safe_load instead of yaml.load
In Ruby, there are now analogous options (including - of course lol - a gem which monkeypatches the YAML module to make it safe by default) [1]:
> Use the safe-yaml gem which overrides YAML.load
> Require a newer version of Psych that provides a safe-load option
In Java, SnakeYaml has a document about security which i think is a long way of admitting that it's not secure [2]. It looks like eo-yaml just doesn't support tags at all.
To be fair, YAML itself does not specify how tags should be interpreted, technically the idea of grabbing constructors from those is the library's issue. But then again, you wouldn't want to accidentally introduce code execution when you adopt a new library/language.
At least YAML has comments, which JSON doesn't. I know people will say "JSON is not meant as config format" but in reality it is used as such.
In general I don't understand why there is so much churn and focus on config file formats. They can be annoying but in the end the real problem is that we have complex configurations so a different format is not going to help much.
Personally I prefer YAML over XML or JSON for config because I don't have to worry about closing brackets or braces. Maybe we need a good editor to make editing them easier.
I was at a place 7-8 years ago with a hand-rolled JSON parser that had been written across a few afternoons by one guy without much ceremony. It was untouched after that aside from some renaming and other minor refactors. As usual with these things, the decision to hand-roll was made by one very opinionated dev who got his way because the business depended on him.
When that article was published it started an argument among the team. The guy ended up implementing the test suite to defend his decision. To my surprise the parser passed all tests apart from 3 or 4 unicodey-ones where it was more permissive than it should have been. There were plenty of production bugs at this place but none of them were due to the parser.
IMO parsing JSON really is simple. If you read through the article you'll see that most of the test cases are dead simple and hardly landmines.
This is not claimed by the article afaict. It's stated though that json spec/syntax is simple, and that it's simple as a language; my interpretation is that this means "simple/understandable/predictable for humans".
If language A is a subset of language B it doesn't follow that parsing B is strictly harder.
This is not guaranteed. Consider two languages:
1. Some number of "a" followed by the same number of "b". For example, aaabbb but not aabbb.
2. Any number of "a" followed by any number of "b". For example, aabbb but not aba.
In this case (1) is a subset of (2), but parsing (2) is easier than parsing (1) since in (1) you have to verify that the numbers match (which, in technical terms, means its not regular).
> Json is so obvious that Douglas Crockford claims to have discovered it — not invented.
I mean, it's called "JavaScript Object Notation" for a reason. From what I know, the beginnings of it really were in the early days of AJAX: People were looking for a good way to encode complex data structures in dynamically generated script tags.
Then someone stumbled over essentially a random syntax element in JavaScript that turned out to be extremely well-suited for that task.
So I think talking about "discovering" JSON as a JS syntax feature which later became its own thing is quite correct here.
YAML seems like a good that gets harmed by feature-creep. All I want when using YAML is a simple human-friendly text-format for slightly structured data. But all those special features and edge cases...as if I even have the time to learn about them. Values should be only text. Outside of the handful clear specified cases of numbers and maybe true/false/none, they should not have any other interpretation on the parser.
Isn't there something like a simple YAML-definition and some YAMl-schema for the powerusers?
He mentions it at the end (the 'YAML subset' alternative), but the edge cases only cause issues if your keys and values begin with special characters but are intended to be simple text. I tend to defensively quote stuff (probably much more than I have to), and I rarely find these issues. I have other issues with YAML but not this.
> Values should be only text. Outside of the handful clear specified cases of numbers and maybe true/false/none, they should not have any other interpretation on the parser.
I think simpler way would be just forcing quoting on text. That fixes the boolean and the different base numerics problem
There's a lot of alternatives out there. One of the most complete (in terms of specification) and very promising is concise encoding (https://concise-encoding.org/) which focuses on the duality of editable human compatible representation (as text) and efficient binary encoding/decoding. The biggest issue right now is lack of actual implementations. The project is open source (I'm not affiliated with it).
In the linked YouTube video talking about JSON: "People were putting instructions to the parser in comments... so I [removed] the comments." - Douglas Crockford.
Let the impact of that sink in - that decision has almost certainly literally cost millions of developer hours! In fact, the article actually claims that the lack of comments in part led to YAML itself so by implication...
I jest (sorta) but what a great example of an initially helpful decision having last consequences.
Wow, you must really be forgetful. Maybe your productivity would improve with some post-it notes stuck next to your monitor, reminding you of the basics about how these formats work.
When I first discovered YAML, I loved it's apparent simplicity. Nowadays, I sigh every time I have to use it and am very happy with the Rust world having mostly adopted TOML.
I wonder why generated JSON is not used more widely, something like jsonnet[0], although I've never used it.
Most systems come with Python 3 installed, which supports working with JSON[1] without installing any dependencies. So, I'm wondering if we could use Python to generate JSON data that is then consumed by other tools. This would fix the lack of comments and trailing commas in JSON, you get functions and other abstractions from Python, and you don't need to install any third-party tools (vs. something like jsonnet).
I’m at a crossroads and evaluating whether to introduce jsonnet to my org. We are doing a massive conversion of legacy yaml manifests from a proprietary vendor format, and there are not a lot of chances like this where you can make such a change at scale. Any experience reports or advice on jsonnet would be appreciated.
At Grafana Labs we're using jsonnet at scale, while being a powerful functional language it is also excellent for rendering JSON/YAML config. We have developed Tanka[0] to work with Kubernetes, for other purposes I can recommend this course[1] (authored by me).
Wow I love it here. Where else can you post something and get a project leader chiming in within hours?
We are at a crossroads in moving towards GitOps and a CD vendor change, and are forced into some manifest conversion. From where we are coming from Helm is the obvious choice, but I do think we can do better, especially for debugging, readability, and inheritance.
ArgoCD’s support for jsonnet turned me onto it and Tanka, and now I’m going to take it for a more serious spin. I’m early days with it but I’m curious about how life is with having a compiled language for an infra development. I had the same reluctance when thinking about making the Typescript leap, but that turned out just fine. I kinda want to jsonnet all the things if it works out well, but I worry the compilation steps would make it cumbersome for some use cases.
Sometimes an application will start out with a need for just a configuration
format, but over time you end up with many many similar stanzas, and you
would like to share parts between them, and abstract some repetition away.
This tends to happen in for example Kubernetes and GitHub Actions. When the
configuration language does not support abstraction, people often reach for
templating, which is a bad idea for the reasons explained earlier.
Proper programming languages, possibly domain-specific ones, are a better
fit. Some of my favorites are Nix and Python
Templating is fine with YAML if you don't do it with strings but with a system that turns one YAML document into another YAML document, that is, do your substitutions in the YAML universe.
The "code up your configuration in your favorite programming language" can really work but it frequently becomes a point of frustration itself. As much as I want to like YAML it has a number of intrinsic problems like the Norway problem... But I do think people are confusing the accidental and essential complexity and because of that they flinch and reach for non-solutions to the problems of configuration rather than really thinking it through.
I don't get all the YAML hate. The article even mentions solutions, which are all better than adopting some nonstandard json variant or toml.
- for whatever language you're using, be aware of which YAML version its YAML library supports and its defaults, and how to safe load yaml in that language.
- defensively quote strings, particularly if you're on a language with an antiquated yaml library that defaults to yaml 1.1.
- defensively use true/false only, and proactively convert any other booleans in your codebase to true/false.
- Depending on your language, you can avoid any custom data types for any externally-distributed applications to mitigate the risks, even when it might make things more convenient. Use safe loading (most languages with yaml libs support it) to avoid loading any. The other major YAML alternatives that YAML haters recommend won't have custom data types either.
Features like references and folding semantics are very convenient, and you don't even have to use them. Basic yaml enjoys better readability than json. toml is only fine if you don't have much nested data.
The author's note that there are json variants that help with some json failings makes no sense. If you're going to adopt some non-standard json variant, why not just adopt yaml 1.2, make sure your language has a yaml lib that supports it, and use that? At least yaml 1.2 is standardized. It's not their fault if python's libyaml only supports yaml 1.1. It looks like pyyaml is essentially in maintenance mode and ruamel.yaml is what everyone should be using? Unfortunately nobody's gotten around to implementing safe loading natively, but that's a python problem, not a yaml 1.2 problem, and ruamel.yaml supports pure-py safe loading that's compliant with 1.2 (no integer-interpretation gotchas), which is fine in most cases where yaml is only loaded occasionally, i.e. at start-up, and performance isn't critical.
Obviously YAML has historical problems, but what's better? Using another flawed or even more limited data format, inventing your own which will begin with zero adoption, or simply ensuring your environment/app uses yaml 1.2 and best practices?
Having to watch out for footguns (by being defensive as you described) means you're just having to learn these rules. What benefit is YAML giving you then?
Why not use JSON? Conversion of types from YAML to the language's native types is a poor feature to get in return for footguns.
If you _need_ complex types - like a in RPC serialization - then i would imagine using XML is better, and forget about making it human-readable. Create a client/testbed instead.
Or you could ensure your language supports and defaults to yaml 1.2, so you don't have worry so much.
Every language has warts and pitfalls and things that are recommended against. Suggesting that one should abandon such languages, whether full-featured or data-description DSLs, when they're otherwise more productive than the alternatives, is disingenuous.
Suggesting that yaml offers no genuine advantages? JSON is annoying. It requires good editor syntax checking support to avoid mismatched and trailing punctuation. It lacks comments. I could live without the nice syntactic sugar of yaml, and even its lack of references and line-folding, if it weren't for those other things.
Which leaves something like cfg or json5, both of which have less support than yaml 1.2. So wth are we talking about? Don't use perhaps the best available (human-editable, inline-nested) data DSL because it might not be supported in some language, and because it has a few potential footguns just like json does? toml may be clean, but it's not as easy to deal with because of how it represents nested structures (which aren't fully inlined like they are in json or yaml), as so many people on this thread have pointed out.
There's a reason so many modern tools use yaml. It's not that their authors weren't aware of json. Plenty of people are simply more sick of json's problems, and consider yaml a superior, not perfect, alternative.
The amount of "defensively [do something]" and "best practices" is another way of saying "this format is so bad you need to thread carefully or else we'll blame it on you".
Good format should not require defensive writing, and also "best practice" is a bit of misunderstanding: it's best practice to avoid such a bad format, not attempt to screw people into it and then blame them for not following some arbitrary set of rules.
I agree with most of your suggestions, but I wouldn't use "safe_load" unless the file has untrusted input (in which case, you could argue, you shouldn't be using YAML at all).
If you use safe_load then you'll get an exception if you use dates or timestamps, even if it's an unquoted string that happens to look like a date (but you can get around that last one by quoting).
One of the major use-cases for YAML is as a host language for DSLs, essentially basic programming languages for specific use-cases. TOML isn't as good there, as these languages often need deep nesting of data structures. GitHub Actions is the obvious example.
Yeah, toml isn't great for that. It's greatly preferable to yaml for human-readable config. Json is better as a serialisation format.
DSLs are bit vexed, not least because they're often horrible in themselves - cruft-accumulating hacks with no tooling, blurring the distinction between code and config often as a workaround for unwieldy dev processes. That's certainly not true of all DSLs, though (can't speak for Github Actions) and there is a need for a simple common base syntax/parser for them. I don't think yaml is a good solution.
Being a cantankerous old git, I tend to think the problem of a common base syntax/parser for DSLs was solved 70 years ago: s-expressions/lisp.
I'm very iffy on DSLs in general. One that I'm using at the moment has foreach loops but no if statements! And... all the inputs must be specified in a YAML file!
This is why my own configs are either ini where I know 100% that it would never become complex and take more than few lines or XML for everything else.
> The yaml package supports most of YAML 1.2, but preserves some behavior from 1.1 for backwards compatibility. YAML 1.1 bools (yes/no, on/off) are supported as long as they are being decoded into a typed bool value. Otherwise they behave as a string.
Good solution for using YAML with strongly typed languages. No reason to leave type decisions up to a parser. I assume serde does something similar in Rust?
To me, the yaml document from hell is a series of yaml documents I helped create that replaced a bunch of database config and hard-coded constants. It helped 'unlock' the business to create newer forms of products much more quickly and correctly, but it never got moved to an actual database. So at this point, they have some yaml documents that, if expanded to include all references, end up becoming this massive fucking tangled mess.
IIRC we never moved it to a database partly because we did not have time to solve for how we actually wanted references to work.
The yaml document and code that reads it still work as a way of speeding up the business compared to how things used to be. But that code takes a long time to parse, has probably caused a decent level of confusion for developers who have to mess with it who aren't on that team, and has absolutely taken a lot of clock time being parsed for validation checks in unit tests.
Still not sure I would have solved that problem differently, aside from perhaps moving the thing to a database immediately after the first phase of working on it.
YAML with templating becomes troublesome even more so when these are Django tmeplates. That's why I do not prefer ansible for automation. It becomes so much cumbersome at certain point that it is more valuable to jump into a real programming language instead of wresteling with both YAML, Django templating and python.
That's where I am enthusiastic proponent of pyinfra.
Ansible and YAML were my primary (de)motivators to create Judo (https://github.com/rollcat/judo). This combo is extremely frustrating: for every line in a (hypothetical) shell script that would do one thing, I needed 3-5 (sometimes many more) lines of YAML. Most people on the team who were just getting started with Ansible, would often do half of their work just shelling out. I would usually push to do things "the Ansible way", but even I had to acknowledge the mental overhead of translating back & forth. I think what finally pushed me over the edge was when we started venturing into compose & k8s, and had to mix & juggle YAML+Jinja in two entirely different contexts, each with its own quirks, bugs, gotchas and brain damage.
I figured I just need a layer of glue to run shell scripts across a bunch of remote hosts (hence Judo), and otherwise resort to other tooling (like Terraform, AWS CLI, k8s CLI, etc) for problems that don't map to SSH.
I didn't know these existed, until I read your reply. Thanks - looks interesting, I will have to investigate further.
First, I've done some research into alternatives, but my primary motivation was to prove you can replace Ansible with a weekend hack that closely follows the UNIX philosophy. Here I am 6 years later still using it everyday in production, so I guess I was right.
Second, dsh looks a bit antiquated - defaulting to rsh? Granted I have very little experience with commercial Unices (which seem to be the primary use case there), but... rsh?
To me, the #1 reason to use YAML rather than anything else is if you need to embed complex multi-line strings in your document. This is a practical necessity in CI systems: you always end up with at least a little bit of shell scripting to glue things together, and embedding shell scripts into anything other than YAML is an absolute nightmare.
Yes, there are too many options for expressing multi-line strings (In the vast majority of cases, I really don't care whether it has a trailing newline or not). Yes, there are weird rules that don't make sense, like how in "folding" mode a newline followed by two spaces more than the current indentation level doesn't get folded. But it's still the best option for CI, which is why Github actually ditched HCL in favor of YAML after a while: https://news.ycombinator.com/item?id=20647691
The CFG configuration format is a text format for configuration files which is similar to, and a superset of, the JSON format. It's not new - it dates from well before its first announcement in 2008 - and has the following aims:
* Allow a hierarchical configuration scheme with support for key-value mappings, lists and basic types such as strings, ints, floats, Booleans and date/times.
* Support cross-references between one part of the configuration and another.
* Provide a string interpolation facility to easily build up configuration values from other configuration values.
* Provide the ability to compose configurations (using include and merge facilities).
* Provide the ability to access real application objects safely, where supported by the platform.
* Be completely declarative.
It's similar to newer formats such as JSON5, HJSON, HOCON and similar but offers a number of features [0] which they don't, as indicated by the above list. It's not intended to occupy the niche where you find things like Cue, Jsonnet, Dhall and similar.
It was just never especially publicised when first implemented for use in Python projects, but it now also has implementations for the JVM, .NET, Go, Rust, D, JavaScript [1], Ruby and Elixir (all BSD-3-Clause licensed) and it would be great to get feedback on the project from the HN community.
INI doesn't let me do hierarchies and is out right out of the gate.
I started my career during the "XML ALL THE THINGS" craze and feel physically ill when I need to edit XML. It's technically the best, but it can be misused in so many ways[0] that it makes it unviable. XML Schemas, DTD etc make it a breeze to handle programmatically though.
JSON might be good, but it doesn't have first-class comments and no links or refers. It even kinda has a schema spec.
YAML has a ton of edge cases (like in the linked post), but it's hierarchical, human editable and machine readable-ish as long as you take the edge cases into use. You can also link and refer elements to reduce repetition.
[0] elements with no values, but 20 attributes, too many elements with values, but no attributes, etc etc...
Many commends are (correctly IMO) pointing to JSON as superior to YAML given YAML's problems, but these ignore JSON's problems due to its lack of semantics. When moving JSON between systems, the JSON parser makes certain assumptions about the JSON document, such as whether the numbers represent integers or single-precision or double-precision floats. This is certainly less obnoxious than "no" being treated as a bool, but it is a problem.
A friend of mine created Preserves[0] in part to resolve this problem. I'd encourage everyone to check it out. To be fair, he's also quite pro-Dhall and Nix.
The simple answer to that is to store anything that may not fit in double without loss as a string. (I don't know of JSON decoders which use floats)
After all, one of the biggest upsides of JSON is its wide language/tool compatibility. And that means intentionally limiting the format to the most basic subset of types that all languages have.
Amazing that developers still spend so much time getting bogged down in encoding issues in 2023. Why can't we just edit some data structures directly and send send them around seamlessly? It's a deeply dysfunctional state of affairs.
For that, you'd need a set of commonly accepted data structures.
Alternatively, you can describe and send arbitrary data structures. Although that begs the question of how to process arbitrary data structures. (JSON and XML aren't arbitrary, for that matter)
For a human-readable, schema-free data representation, I really like Amazon's Ion format (disclosure, I'm an Amazon employee). It is basically JSON + additional types (integers, timestamps, symbols, sexpressions), and support for humane features like trailing commas and comments. It also has a more efficient binary representation. I think it could have been a contender had it been released a decade earlier, but now I think the existing formats are way too entrenched.
For managing configs of ML experiments (where each experiment can override a base config, and "variant" configs can further override the experiment config, etc), Hydra + Yaml + OmegaConf is really nice.
This is why configurations as code should be written in actual programming languages. Dhall, Nix, and Pulumi are all solutions geared towards configuration but written with fully capable, user-extensible, programming languages.
Don't forget Lua! Can be easily sandboxed, meaning you have full control over which functionality is made available to the user. Also, the Lua interpreter itself fits in less than 300kB and can be easily embedded in any language that supports C extensions or FFI, so people don't even need to write their own parsers.
People often forget about the environment, and I feel like a lot of the simpler services and applications could be configured through it easily.
For anything that requires more complex structures, JSON5 (https://json5.org/) has been gaining traction. It's basically JSON that allows a couple of more things, including comments, trailing commas, and even unquoted keys, if you're into that.
For simple use cases like key-value style config you can use JSON or TOML without too many issues.
For IaC the alternative is general purpose programming languages using declarative infrastructure APIs. E.g. TS, Go, Python with CDK, CDKTF, Pulumi. For CI are stuck with YAML for now.
As another top-level comment mentions, one alternative is NestedText, where everything is a string unless the ingesting code says otherwise, and there is no escaping needed at all.
As long as you ask your configuration language to infer the data type from a piece of text, these are the kinds of edge cases you get to experience. (They vary by language. Less types means less mistakes, and so does less expressive power - but without some form of type hinting, that's where you are)
Personally, I like YAML for expressive simplicity at the start of a project, and then if it becomes an actual load bearing piece of software (vs a haphazard one off, or an experiment), let's add some schema validation & typing.
I was looking for a human-friendly format to store data for a staticly generated website. Stuff like copy, lists, addresses, contact information (so that the rendering logic is kept separate).
I'm a huge fan of NestedText, especially as there is no escaping needed ever.
If you ever want to use it as a pre-format to generate either TOML, JSON, or YAML, I used the official reference implementation to make a CLI converter between them and NestedText.
When generating one of these formats, you can use yamlpath queries to concisely but explicitly apply supported types to data elements.
I remember the first time I played with YAML ten-ish years ago. I experimented with converting our configuration file from INI to YAML. It came with an actual noticeable increase to our app startup time in the tens of milliseconds.
The YAML evangelist in my company when asked told me I should cache the results… of reading our config file… from the local filesystem. What do I store that cache as? JSON? Just cut out the middle man. Left a really bad taste in my mouth at the time I have yet to get out.
“YAML evangelist” sounds terrifying, and I have never met one in real life. Most people who used YAML basically resorted to the old argument of “Well JSON doesn't have comments, so YAML it is”.
In which languages is it implemented? I have seen a supposedly equivalent Rust library, but could not find anything else. Is there any C library or something like that? Unfortunately, these are the easiest to use from a lot of languages because of how easy they are to wrap.
(I am genuinely interested in any useful library better than libyaml).
JSON (as per spec) is a lightweight data-interchange format.
YAML is a "human-friendly data serialization language for all programming languages" and by mere coincidence (it does not look to be by design until version 1.2.2 [0]) JSON is its subset and not vice versa!
And YAML is human-friendly in two ways:
- it is notoriously "human" in interpreting input, i.e. ignoring the context or misinterpreting others' words;
- it helps read serialized data via indentation-based syntax.
The biggest caveat is for whatever reason everyone ignores the key highlights of both JSON and YAML that are "data-interchange format" and "data serialization language". If I were to interpret these two terms I would rather say they both present great means for heterogenous programs to exchange data with YAML being a fancier brother better suited for human eyes. They were not meant to be used for configuration purposes or what not. But people started using them exactly for this purpose instead of creating a configuration format/language that would render into program-readable JSON(if needed).
CUE and Dhall are perhaps the first two attempts to create specifically a configuration language with the ability to serialize in yaml/json/etc.
I very much hope using YAML, JSON and even TOML for writing configurations will become an anti-pattern soon and will be replaced by something more suited for this role.
If you only need something for internal use, nothing prevents you from using s-expressions, and interpret atoms (number -> uint16_t, dates in "yyyy-mm-dd") whatever your application feels like... With this lil' trick all parsing problems are gone. Inferior Format Users will be jealous, and Inferior-Format-Parser-Writers will hate you
I'm surprised nobody mentions an alternative called NestedText. It only supports string type, which puts the complexity and responsibility of typing with the application. I think it's less prone to parsing errors.
> The key on is common in the wild because it is used in GitHub Actions. I would be really curious to know whether GitHub Actions’ parser looks at "on" or true under the hood.
I can say, at least, that using both on: and 'on' work in GHA. I usually write the latter, makes it simpler to do ad-hoc YAML.parse or whatever on the workflow files.
I've ways preferred HOCON to YAML but it never took off :-/
It's a pity, because compared to YAML it's a lot simpler from the rules perspective while being flexible enough to do some useful stuff over plain JSON
Also, it isn't white space dependent, something which annoys me know end with YAML
Language aware is definitely important. But honestly I've usually found it easier to use a "real programming language" to generate the structures. You can read and write as normal. Then you can just serialize them to YAML at the end.
Helm is so bad. It has a `| quote` function that is almost always wrong. People use it to escape strings into YAML strings but it just adds quotes around the values. It doesn't actually escape to YAML. I had a surprising hard time convincing people that they should be using `| toJson` and ideally be doing it for every interpolation.
But really working with text is just an inconvenience here. You can imagine how much better everything would work if your base template was `console.log(JSON.stringify({ /* your config here */ }))`
I've always hated YAML, and now I'm glad there's a very nicely written article to back me up.
I also notice that I have a preference to procedural as opposed to declarative specifications. E.g. I find conditionals and loops in declarative specifications quite bad.
Call me naive or quote xkcd, but whenever I read about the shortcomings of YAML, I daydream about a new standard that's mostly a subset of YAML, that looks like this:
rules:
- "All strings must be quoted and are parsed identically to JSON strings"
- "true and false are the only boolean values"
- """multiline strings
are allowed"""
- """|
there can even be special multiline string types
to indicate things like "dedent every line and
trim the beginning and end lines if empty
"""
# Comments are allowed!
- Number syntax just like JSON
better_than_yaml: true
"a number with multiword key": 1e9
nesting:
present: true
difficult: false
It has the ease of coding of yaml, maps 1:1 with json (so can easily be re-serialized to json or yaml if needed), is familiar to folks who know yaml, and supports comments. And it eliminates ambiguous parses and gotchas, references, tags/directives, and other complexities.
Yaml is the complete opposite of what you want: a simple specification language. JSON is the gold standard to measure against. However one step better IMHO is S-expressions.
This one liners lead to unreadable configuration.
With tools, the format is not important.
But we did not talk about tools, we talk about that humans can easy read and write a configuration.
A text editor is a tool. Text files are only "human readable"/"human editable" in the sense that such tools are ubiquitous whereas structured data editors are not.
Which is a real shame. Entering, manipulating and validating small amounts of structured data is such a fundamental task when using computers that it deserves dedicated tools, and the sheer amount of issues that only exist because such tools are not ubiquitous is absolutely mindboggling.
i want *any* configuration format that can rewrite itself(loaded and written to disk again) with two properties we've seem to have lost when we switched away from xml.
1. keep ordering of document
2. keep comments of document
I honestly don't understand why people still write YAML considering there are alternatives like TOML available.
I think attributing semantic value to indentation is a terrible idea. It gets even worse when there is so much visual ambiguity when it comes to defining values and escaping certain character sequences.
Whitespace nesting also doesn't seem to be a problem for Python programmers. I don't prefer it myself (especially because of the tabs vs spaces problem) but it's not good or bad.
Extra whitespace before 'something' in your example would cause an issue.
> Whitespace nesting also doesn't seem to be a problem for Python programmers.
It does cause problems, IDE's mitigate the issue, the same as they do for YAML.
However YAML is supposed to be a human readable data-serialization language and If you need an IDE to make it human readable then that defeats the point.
I can't imagine ever being convinced that having to 'count the number of invisible things to determine what something is' is human readable even if you can use other lines as reference points.
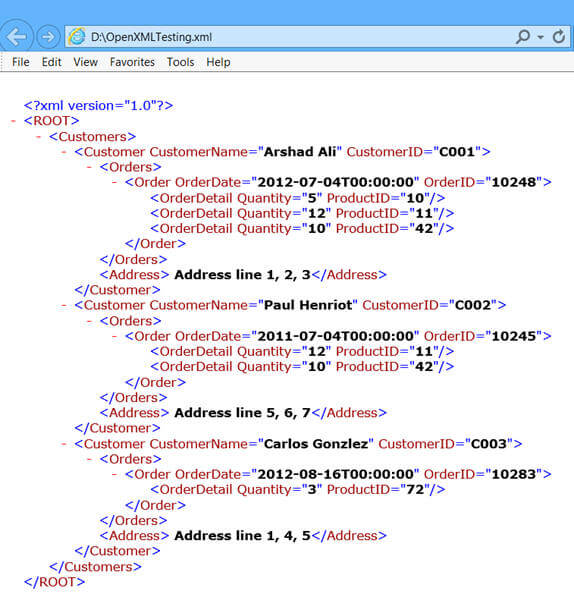{kind=link}
{kind=link}
Actually, this is not the case. We had INI format for simple stuff and XML (protected with entire schema) for complex things many years ago, which worked. Yet, we wanted something readable (like INI), but able to express complex types (XML).
I don't think Toml is a viable replacement - for me, it has an INI-level of simplicity with even worst hacks to have nested structures. But, give it time and you'll have another YAML.
But yes, YAML is confusing for edge cases (true/false, quoting), but I'm going to find a powerful replacement that is not XML. Maybe EDN can jump in, but for anything more complex, I'd rather have a Lisp interpreter and structures around than any of mentioned and upcoming formats.
Thinking that JSON is a suitable replacement, imagine writing Ansible or k8s stuff in it; that would be fun ;)